不信谣不传谣,亲自动手验证ModelBox推理是否真的“高性能”
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不信谣不传谣,亲自动手验证ModelBox推理是否真的“高性能”相关的知识,希望对你有一定的参考价值。
摘要:“高性能推理”是ModelBox宣传的主要特性之一,不信谣不传谣的我决定通过原生API和ModelBox实现相同案例进行对比,看一下ModelBox推理是否真的“高性能”。
本文分享自华为云社区《ModelBox推理真的高效吗?》,作者:吴小鱼。
“高性能推理”是ModelBox宣传的主要特性之一,不信谣不传谣的我决定通过原生API和ModelBox实现相同案例进行对比,看一下ModelBox推理是否真的“高性能”。
我们分别使用onnxruntime与ModelBox Windows SDK对相同的模型实现相同的推理逻辑进行端到端性能对比,为了防止测试视频帧率成为性能瓶颈,我们准备了120fps的视频作为测试输入。
如果对Windows ModelBox SDK使用还不熟悉,可以参考我们的ModelBox 端云协同AI开发套件(Windows)上手指南。案例所需资源(代码、模型、测试数据等)均可从obs桶下载。
案例说明
为了充分考验不同框架的推理性能,我决定做一个稍微有那么一点点繁琐的双阶段单人人体关键点检测案例。案例具体流程如下:

其中,人形检测使用开源YOLOV7-tiny预训练模型,关键点检测使用开源PP-TinyPose预训练模型,在进行人形跟踪后我们过滤得到最早出现的id的检测框进行关键点检测。
onnxruntime推理
原生API推理代码位于资源包的onnxruntime_infer目录下,具体的代码组织为:
onnxruntime_infer
├─onnxruntime_infer.py # 推理入口脚本
├─utils.py # 人形检测后处理
├─sort.py # 跟踪
├─hrnet_post.py # 关键点检测后处理
└─smooth.py # 关键点时序滤波其中,入口脚本onnxruntime_infer.py中指定了使用的模型文件与测试视频:
cam = cv2.VideoCapture("../data/dance_120fps.mp4")
size = (int(cam.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cam.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
out_fps = cam.get(cv2.CAP_PROP_FPS)
res_cam = cv2.VideoWriter("../hilens_data_dir/rt_result.mp4", fourcc, out_fps, size)
det_sess = rt.InferenceSession("../model/det_human/yolov7-tiny.onnx", providers=["DmlExecutionProvider"])
pose_sess = rt.InferenceSession("../model/det_pose/pose.onnx", providers=["CPUExecutionProvider"])人形检测模型为gpu推理,关键点检测模型为cpu推理,在使用ModelBox Windows SDK推理时也保持了同样的硬件配置。
fps取检测预处理开始到绘制关键点这一区间进行测试:
class DetPre:
def __init__(self, net_h=320, net_w=320):
self.net_h = net_h
self.net_w = net_w
def __call__(self, img_data):
buffer_meta =
buffer_meta["time"] = time.time()
resized_image, ratio, (dw, dh) = self.letterbox(img_data)
...
total_time += time.time() - buffer_meta.get("time")
idx += 1
res_img, pose_data = draw_pose(im, filter_box, pose_data, total_time / idx)
...结果视频rt_result.mp4保存在hilens_data_dir文件夹下,查看结果:

可以看到,双阶段单人关键点技能在onnxruntime推理可以达到36fps左右。
ModelBox Windows SDK推理
ModelBox Windows SDK推理代码位于资源包的single_human_pose目录下,具体的代码组织为:
single_human_pose
├─bin
│ ├─main.bat // 启动脚本
│ └─mock_task.toml // 本地模拟运行输入输出配置文件
├─data
│ └─dance_120fps.mp4 // 测试视频
├─etc
│ └─flowunit // 功能单元目录
│ ├─det_post // 检测后处理
│ ├─det_pre // 检测预处理
│ ├─draw_pose // 关键点绘制
│ ├─expand_box // 单人图像切分
│ ├─object_tracker // 人形跟踪
│ └─pose_post // 姿态后处理
├─graph
│ └─single_human_pose.toml // 技能流程图
├─hilens_data_dir // 运行结果目录
│ ├─log
│ ├─mb_profile // 性能统计目录
│ │ ├─performance_[time].toml
│ │ └─trace_[time].toml
│ ├─dance_result.mp4 // 运行结果视频
│ └─rt_result.mp4
├─model // 推理功能单元
│ ├─det_human // 人形检测推理
│ │ ├─det_human.toml // 推理配置文件
│ │ └─yolov7-tiny.onnx // 推理模型
│ └─det_pose // 关键点检测推理
│ ├─det_pose.toml
│ └─pose.onnx
└─build_project.sh我们可以查看技能流程图graph/single_human_pose.toml了解技能逻辑:
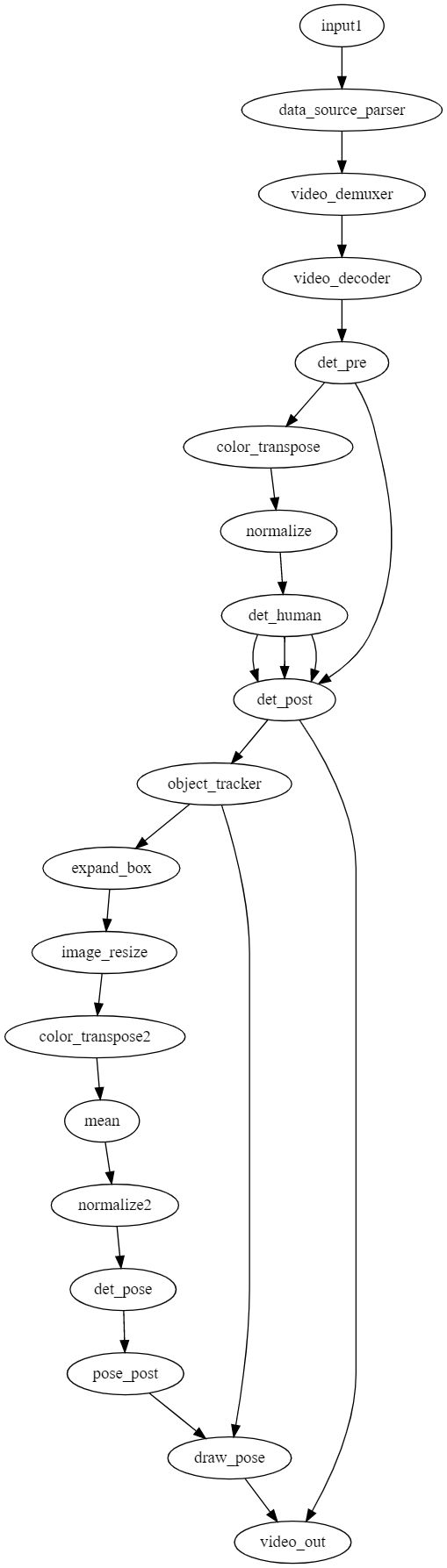
fps在关键点绘制功能单元中进行计算,计算的为端到端全流程fps:
class draw_poseFlowUnit(modelbox.FlowUnit):
def open(self, config):
...
self.start_time = time.time()
self.idx = 0
...
def process(self, data_context):
...
self.idx += 1
self.draw(out_img, bbox, pose_data, self.idx / (time.time() - self.start_time))
...在bin/mock_task.toml中配置输入输出:
# 任务输入,mock模拟目前仅支持一路rtsp或者本地url
# rtsp摄像头,type = "rtsp", url里面写入rtsp地址
# 其它用"url",比如可以是本地文件地址, 或者httpserver的地址,(摄像头 url = "0")
[input]
type = "url"
url = "../data/dance_120fps.mp4"
# 任务输出,目前仅支持"webhook", 和本地输出"local"(输出到屏幕,url="0", 输出到rtsp,填写rtsp地址)
# (local 还可以输出到本地文件,这个时候注意,文件可以是相对路径,是相对这个mock_task.toml文件本身)
[output]
type = "local"
url = "../hilens_data_dir/dance_result.mp4"在技能流程图中开启性能统计配置项:
[profile]
profile=true
trace=true之后双击bin/main.bat或在bash中运行技能:
./bin/main.bat运行完成后生成的视频与性能统计文件都在hilens_data_dir文件夹下:
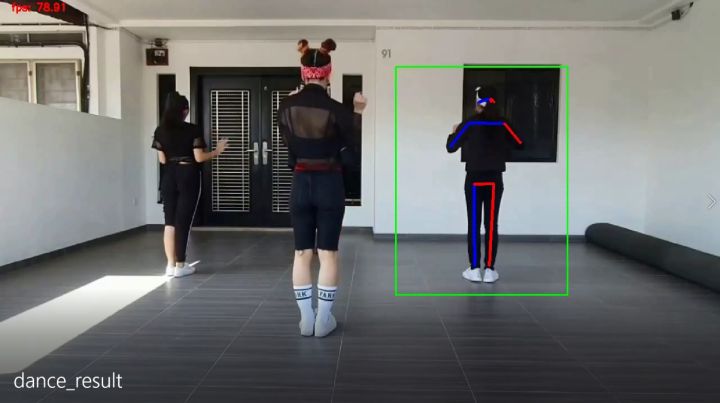
可以看到使用ModelBox SDK进行推理可以达到79fps,名不虚传哇,我们可以在Chrome浏览器chrome://tracing/中加载性能统计文件查看:
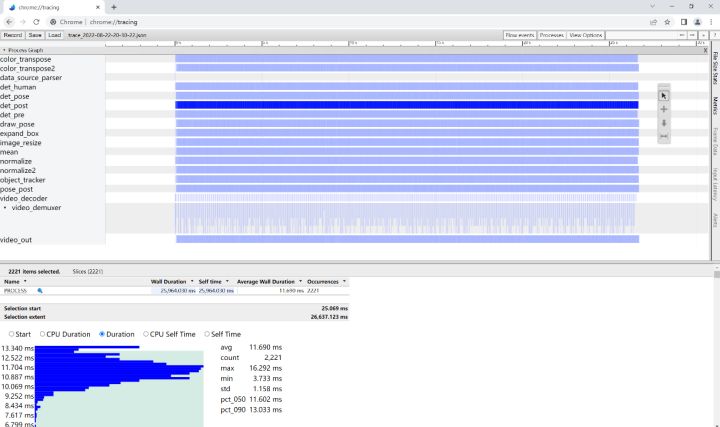
逐项查看后发现耗时最久的是检测后处理功能单元,平均耗时11.69ms,因为ModelBox是静态图并行推理,fps取决于耗时最久的功能单元,理论计算fps = 1000 / 11.69 \\approx 85fps=1000/11.69≈85,与我们在程序中打点计算结果接近。
总结:ModelBox真的很快,nice!
以上是关于不信谣不传谣,亲自动手验证ModelBox推理是否真的“高性能”的主要内容,如果未能解决你的问题,请参考以下文章