Flink 实战系列Flink pipeline.operator-chaining 参数使用以及源码解析
Posted JasonLee实时计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 实战系列Flink pipeline.operator-chaining 参数使用以及源码解析相关的知识,希望对你有一定的参考价值。
Flink pipeline.operator-chaining 参数使用和解析
当我们使用 Flink SQL 提交一个任务,没有给算子单独设置并行度的情况下,默认所有的算子会 chain 在一起,像下面的这样:
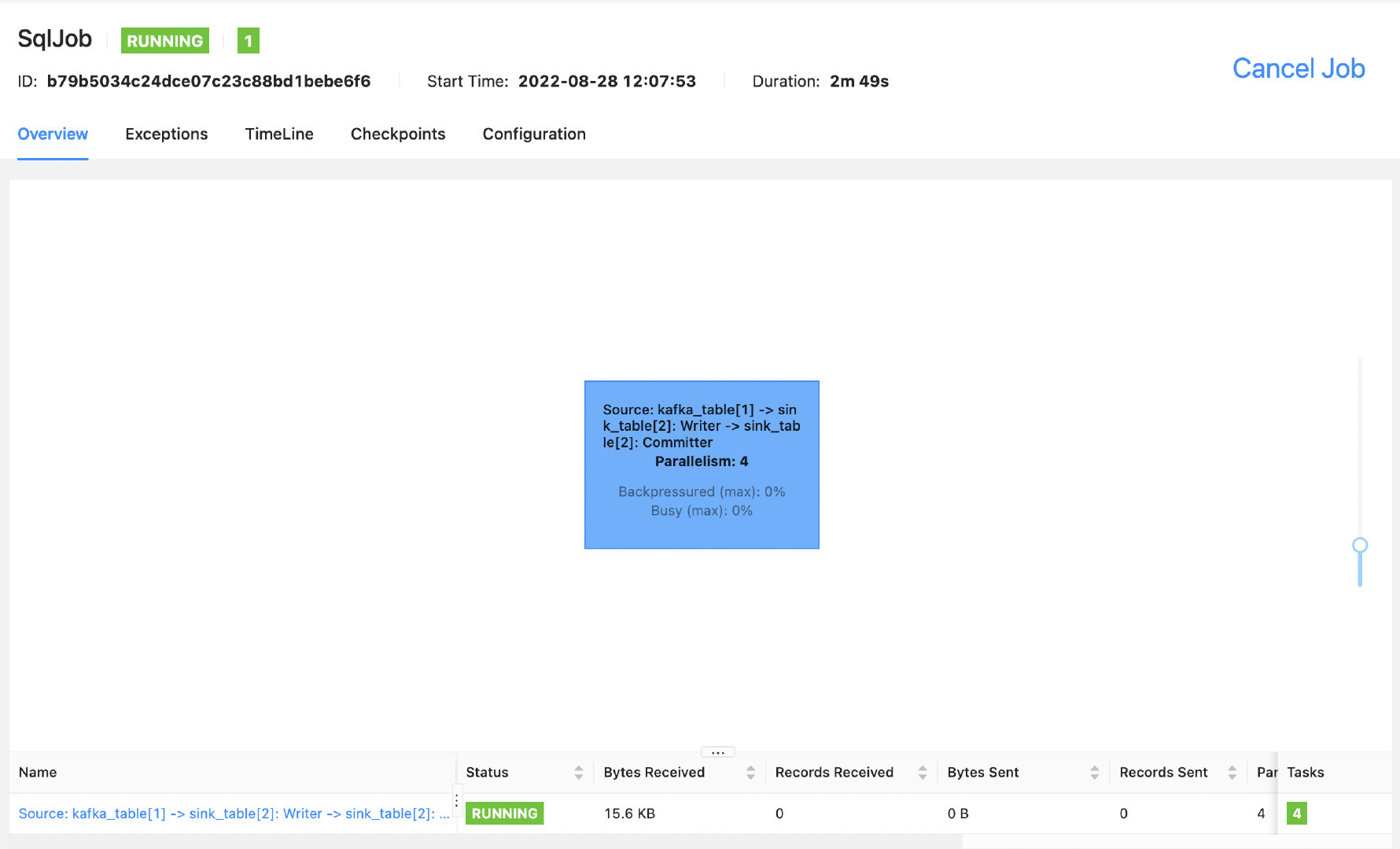
此时,整个 DAG 图只会显示一个算子,虽然这样有利于数据的传输,可以提高任务的性能,但是缺点也很明显,我们无法看到数据的输入和输出,以及反压相关的 metrics。那在 datastream api 开发的任务中我们可以使用 disableChaining 方法来打断 operatorChain,但是在 SQL 开发的任务中怎么办呢?如果我们想要查看每一个算子的输入和输出的数据量呢?其实 Flink 提供了一个参数配置 pipeline.operator-chaining 决定是否要打断 operatorChain。
还是以上面的 SQL 任务为例,我们把 pipeline.operator-chaining 参数加上,再来看下效果。
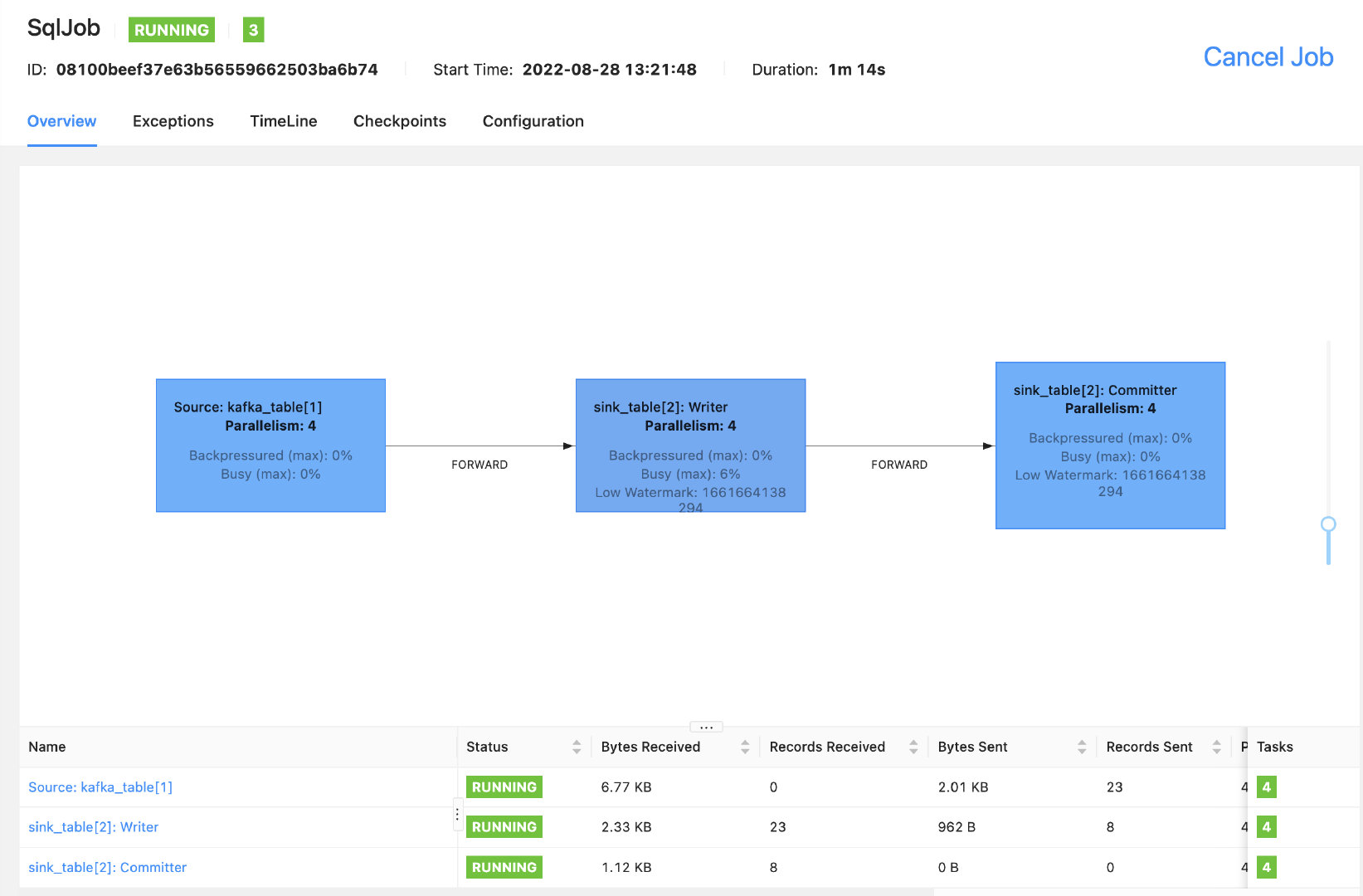
可以看到所有的 operatorChain 都被打断了,Records Send/Received 也正常显示了,其实这个参数不仅是对 SQL 任务有效,对于 datastream API 开发的任务
以上是关于Flink 实战系列Flink pipeline.operator-chaining 参数使用以及源码解析的主要内容,如果未能解决你的问题,请参考以下文章