MySQL中的explain解析
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL中的explain解析相关的知识,希望对你有一定的参考价值。
文章目录
explain
explain概念
使用EXTENED关键字,EXPLAIN语句将产生附加信息。执行该语句,可以分析EXPLAIN后面SELECT语句的执行情况,并且能够分析出所查询表的一些特征。
mysql中提供了EXPLAIN语句和DESCRIBE语句,用来分析查询语句,EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options
查询结果解析
下面对查询结果进行解释:
| 字段 | 说明 |
|---|---|
| id | SELECT识别符。这是SELECT的查询序列号。 |
| select_type | 表示SELECT语句的类型。 |
| table | 表示查询的表。 |
| type | 表示表的连接类型。 |
| possible_keys | 给出了MySQL在搜索数据记录时可选用的各个索引。 |
| key | 是MySQL实际选用的索引。 |
| key_len | 给出索引按字节计算的长度,key_len数值越小,表示越快。 |
| ref | 给出了关联关系中另一个数据表里的数据列名。 |
| rows | 是MySQL在执行这个查询时预计会从这个数据表里读出的数据行的个数。 |
| Extra | 提供了与关联操作有关的信息。 |
就比如下面的explain解释查询语句:
EXPLAIN SELECT * FROM user WHERE username='玉如';
查询结果如下:

DESCRIBE语句的使用方法与EXPLAIN语句是一样的,分析结果也是一样的,并且可以缩写成DESC,DESCRIBE语句的语法形式如下:
DESCRIBE SELECT select_options
例如:
DESCRIBE SELECT * FROM user WHERE username='玉如';
查询结果如下:

explain关注点
重点要关注如下几列:
| 列名 | 备注 |
|---|---|
| type | 本次查询表联接类型,从这里可以看到本次查询大概的效率。 |
| key | 最终选择的索引,如果没有索引的话,本次查询效率通常很差。 |
| key_len | 本次查询用于结果过滤的索引实际长度。 |
| rows | 预计需要扫描的记录数,预计需要扫描的记录数越小越好。 |
| Extra | 额外附加信息,主要确认是否出现 Using filesort、Using temporary 这两种情况。 |
其中,type包含以下几种结果,从上之下依次是最差到最好:
| 类型 | 备注 |
|---|---|
| ALL | 执行full table scan,这是最差的一种方式。 |
| index | 执行full index scan,并且可以通过索引完成结果扫描并且直接从索引中取的想要的结果数据,也就是可以避免回表,比ALL略好,因为索引文件通常比全部数据要来的小。 |
| range | 利用索引进行范围查询,比index略好。 |
| index_subquery | 子查询中可以用到索引。 |
| unique_subquery | 子查询中可以用到唯一索引,效率比 index_subquery 更高些。 |
| index_merge | 可以利用index merge特性用到多个索引,提高查询效率。 |
| ref_or_null | 表连接类型是ref,但进行扫描的索引列中可能包含NULL值。 |
| fulltext | 全文检索。 |
| ref | 基于索引的等值查询,或者表间等值连接。 |
| eq_ref | 表连接时基于主键或非NULL的唯一索引完成扫描,比ref略好。 |
| const | 基于主键或唯一索引唯一值查询,最多返回一条结果,比eq_ref略好。 |
| system | 查询对象表只有一行数据,这是最好的情况。 |
另外,Extra列需要注意以下的几种情况:
| 字段 | 说明 |
|---|---|
| Using filesort | 将用外部排序而不是按照索引顺序排列结果,数据较少时从内存排序,否则需要在磁盘完成排序,代价非常高,需要添加合适的索引。 |
| Using temporary | 需要创建一个临时表来存储结果,这通常发生在对没有索引的列进行GROUP BY 时,或者ORDER BY里的列不都在索引里,需要添加合适的索引。 |
| Using index | 表示MySQL使用覆盖索引避免全表扫描,不需要再到表中进行二次查找数据,这是比较好的结果之一。注意不要和type中的index类型混淆。 |
| Using where | 通常是进行了全表/全索引扫描后再用WHERE子句完成结果过滤,需要添加合适的索引。 |
| Impossible WHERE | 对Where子句判断的结果总是false而不能选择任何数据,例如where 1=0,无需过多关注。 |
| Select tables optimized away | 使用某些聚合函数来访问存在索引的某个字段时,优化器会通过索引直接一次定位到所需要的数据行完成整个查询,例如MIN()\\MAX(),这种也是比较好的结果之一。 |
explain代码案例
数据库准备
# 创建用户表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名称',
`birthday` datetime(0) NULL DEFAULT NULL COMMENT '生日',
`sex` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别',
`address` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '玉如', '2019-02-27 17:47:08', '男', '北京市西区');
INSERT INTO `user` VALUES (2, '晓兰', '2019-03-02 15:09:37', '男', '北京市东区');
INSERT INTO `user` VALUES (3, '花蝶', '2019-03-04 11:34:34', '女', '北京市青湖区');
INSERT INTO `user` VALUES (4, '兰咯', '2019-03-04 12:04:06', '女', '北京市青谱区');
INSERT INTO `user` VALUES (5, '咕咕', '2019-03-07 17:37:26', '女', '北京市红滩区');
INSERT INTO `user` VALUES (6, '嘻嘻', '2019-03-08 11:44:00', '男', '北京市新区');
INSERT INTO `user` VALUES (7, '萌萌', '2019-04-08 11:44:00', '男', '北京市西区');
-- 创建主键索引
CREATE UNIQUE INDEX UniqidIdx ON user (id);
-- 解释查询语句
EXPLAIN SELECT * FROM user WHERE id=3;
-- 创建名字索引
CREATE UNIQUE INDEX UniqidName ON user(username)
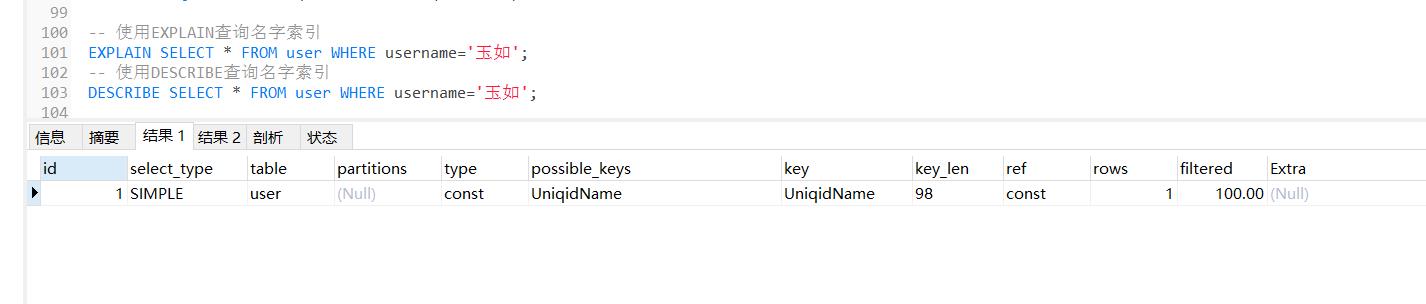
-- 使用EXPLAIN查询名字索引
EXPLAIN SELECT * FROM user WHERE username='玉如';
-- 使用DESCRIBE查询名字索引
DESCRIBE SELECT * FROM user WHERE username='玉如';
-- 探究查询结果字段
EXPLAIN SELECT * FROM user WHERE id=2;

EXPLAIN SELECT * FROM user WHERE id>3 GROUP BY username;

以上是关于MySQL中的explain解析的主要内容,如果未能解决你的问题,请参考以下文章