如何创建与引擎独立的Iceberg表
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何创建与引擎独立的Iceberg表相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
创建表是引擎的必备基本能力,引擎有很多,Hive、Spark、Flink、Trino等等,我们姑且只关注这些,创建的表按照是否跟引擎绑定,分为两大类:managed table和external table。以这里举例的引擎为例,它们都可以将表元数据维护在Hive Metastore中,对引擎来讲,这些表以external table的形式存在。
在本文中,我们将话题限制在Hive、Spark、Flink、Trino如何创建Iceberg表,并且保证各引擎都可以无障碍互相访问。这样,我们的话题分为3个部分:
不同引擎创建的Iceberg表为什么不兼容?
如何屏蔽不同引擎创建Iceberg表的差异?
创建独立引擎的Iceberg表的步骤
不同引擎创建的Iceberg表为什么不兼容
Hive、Spark、Flink、Trino创建的Iceberg表元数据都存储在HMS中,也就是复用了HMS的存储模型,主要涉及的表的相互关系如下:
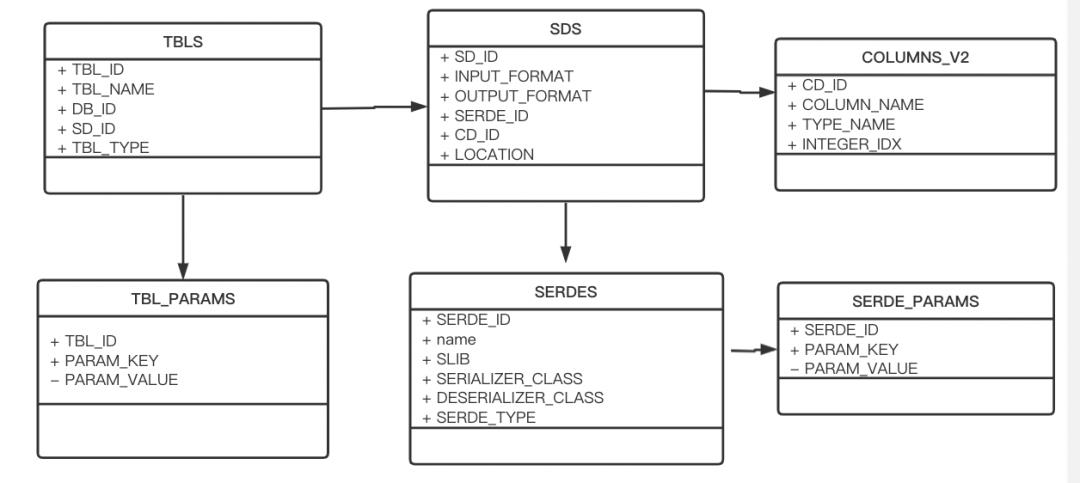
以Hive创建的Iceberg表为例,来看看其存储内容:
CREATE TABLE default.sample_hive_table_1(
id bigint, name string
)
PARTITIONED BY(
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';首先在TBLS中存储了一条记录:记录了当前表的ID,名称,类型,数据库ID,序列化ID,拥有者等信息。在TABLE_PARAMS中存储了相关参数:
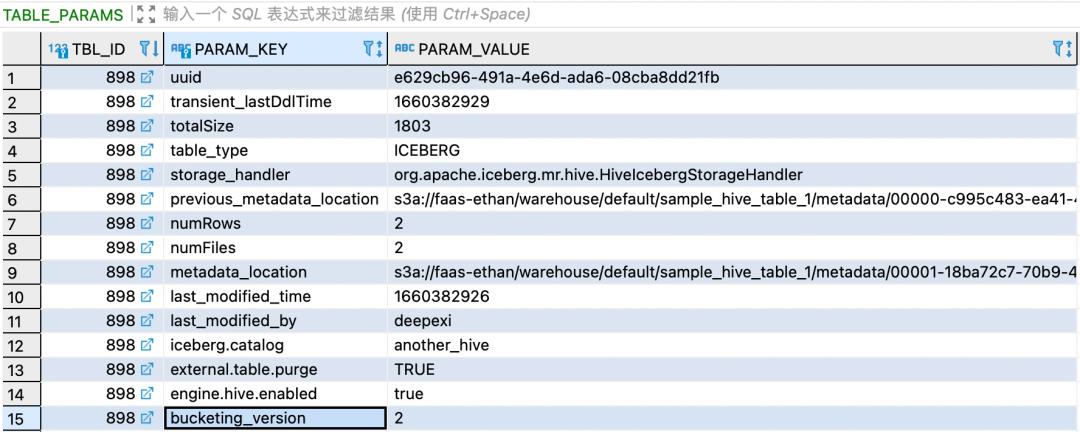
storage_handler记录了当前表需要用Iceberg handler来处理。Iceberg表的元数据信息,通过metadata_location和previous_metadata_location指定,前者代表最新变更记录,后者代表上一次的变更记录。
在字段表COLUMNS_V2中记录了字段信息:

由图可知,其并没有存储分区字段,分区信息存储在元数据文件中。这个表只保存表最新版本的字段信息。
SDS表的内容:
SD_ID | INPUT_FORMAT | OUTPUT_FORMAT | LOCATION | |
898 | org.apache.iceberg.mr.hive.HiveIcebergInputFormat | org.apache.iceberg.mr.hive.HiveIcebergOutputFormat | s3a://faas-ethan/warehouse/default/sample_hive_table_1 |
SERDES和SERDES_PARAMS存储序列化相关的信息,重要的字段只有一个:SERDES.SLIB=org.apache.iceberg.mr.hive.HiveIcebergSerDe
如果你用其他引擎来创建Iceberg表,会发现元数据存储上的几个差别:
首先是序列化信息变成了:
SERDES.SLIB=org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
其次是SDS的存储格式变成了其他HDFS文件格式(以下为示例格式):
SD_ID | INPUT_FORMAT | OUTPUT_FORMAT | LOCATION | |
898 | org.apache.hadoop.mapred.FileInputFormat | org.apache.hadoop.mapred.FileOutputFormat | s3a://faas-ethan/warehouse/default/sample_hive_table_1 |
最后是没有Iceberg的storage_handler属性,由于这些格式跟Hive创建的Iceberg表的差异,导致Hive引擎无法识别其他引擎创建的表,而其他几种引擎之间是互通的,且能访问Hive 创建的Iceberg表,互通关系表现为:
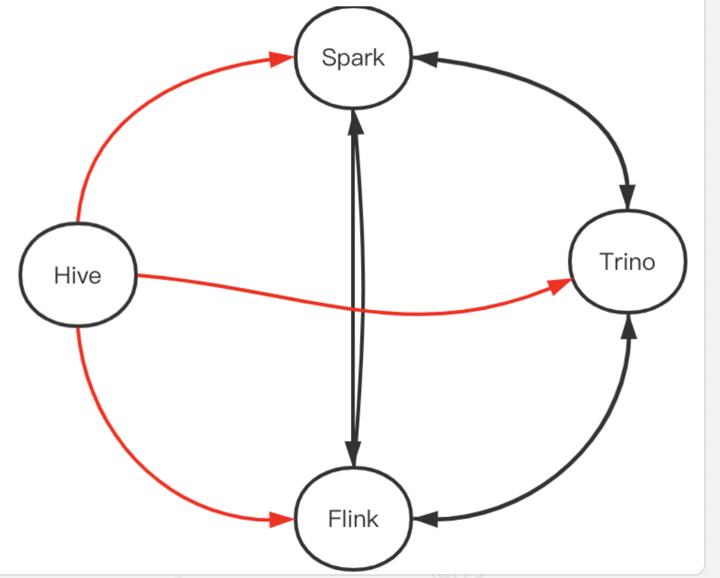
其中红色箭头表示单项互通。
如何屏蔽不同引擎创建Iceberg表的差异
最简单的办法是直接修改元数据:
INSERT INTO TABLE_PARAMS
(TBL_ID, PARAM_KEY, PARAM_VALUE)
VALUES(898, 'storage_handler', 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler');
update SDS set INPUT_FORMAT =NULL ,OUTPUT_FORMAT =NULL where SD_ID =898
update SERDES set slib='org.apache.iceberg.mr.hive.HiveIcebergSerDe' where serde_ID =898为了做到Iceberg表元数据的真正中立,也可以将SDS的INPUT_FORMAT 和 OUTPUT_FORMAT 字段都置NULL。
这是通过事后修补的办法来做到的,能否在创建表之前就修改呢?并且不修改各引擎的实现代码。实际上,引擎创建Iceberg表,是通过iceberg API来实现的,交互逻辑大概是这个样子:
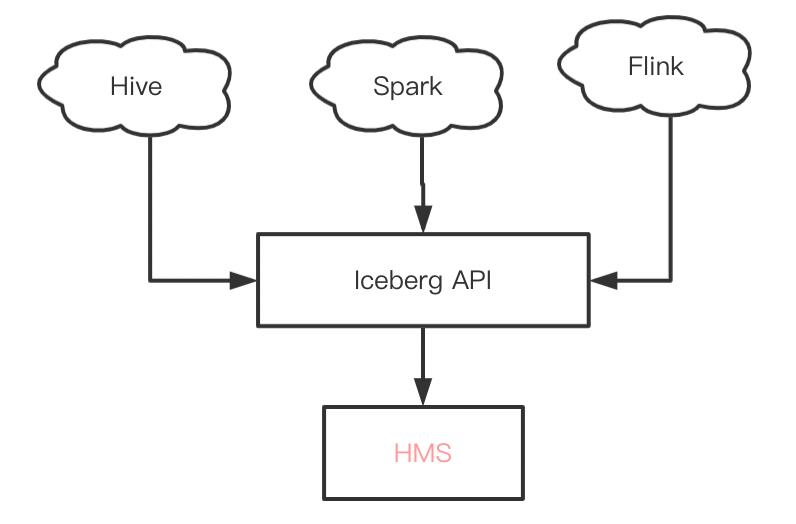
那是不是有办法直接通过Iceberg API创建HMS表呢?of course!
更进一步,我们将上述逻辑模型,抽象成如下结构,引擎变成了通用了Restful API,理想情况下,使用方只需要传入创建表的相关参数等信息即可:
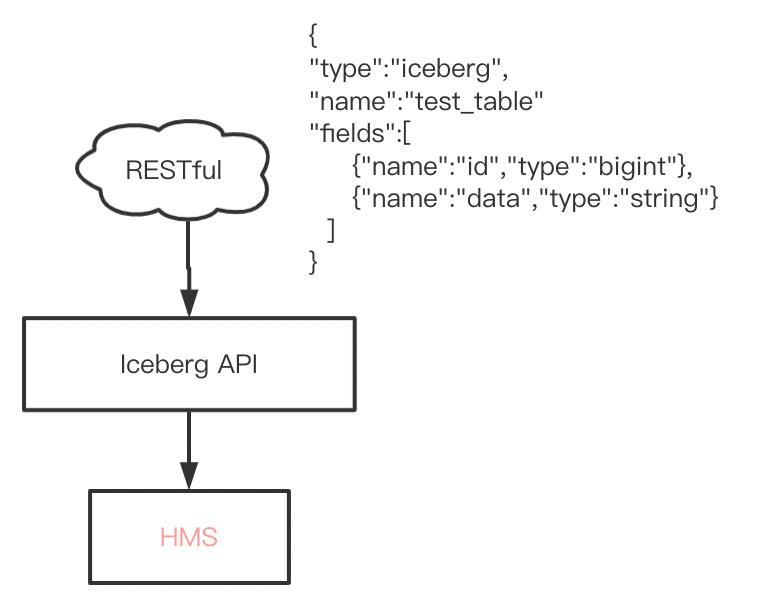
这样一来,不论是Hive表还是Iceberg表,都可以通过这个模型完成表的创建。接下来,我们看如何抽象这样的表模型。
创建独立引擎的Iceberg表的步骤
通过上面元数据的分析,可以将创建Iceberg表的元数据信息分为下面几类:
表名称和类型信息,用一个复合字段来表示:
"name":
"catalogName": "mycatalog",
"databaseName": "test_iceberg_db",
"tableName": "test_iceberg_table",
"type": "TABLE"
域字段列表信息,用一个复合数组表示:
"fields": [
"comment": "primary key",
"defaultValue": 0,
"isIndexKey": true,
"isNullable": false,
"isSortKey": true,
"name": "id",
"type": "int"
,
"comment": "data value",
"defaultValue": "",
"isIndexKey": false,
"isNullable": false,
"isSortKey": false,
"name": "data",
"source_type": "string",
"type": "string"
]元数据信息,用一个复合结构表示:
"metadata":
"table_type": "ICEBERG",
"location": "s3a://faas-ethan/warehouse/test_iceberg_db/test_iceberg_table"
序列化信息,用一个复合结构表示:
"serde":
"inputFormat": "org.apache.iceberg.mr.hive.HiveIcebergInputFormat",
"outputFormat": "org.apache.iceberg.mr.hive.HiveIcebergOutputFormat",
"parameters":
"k1":"v1"
,
"serializationLib": "string",
"uri": "your_hive_table_locaton"
有了表的模型之后,就可以按照下面创建Hive表的创建模板来走了:
List<FieldSchema> fields = new ArrayList<FieldSchema>();
//创建Fields
fields.add(new FieldSchema("colname", serdeConstants.STRING_TYPE_NAME, "comment"));
//创建StorageDescriptor
StorageDescriptor sd = new StorageDescriptor();
sd.setCols(fields);
sd.setSerdeInfo(new SerDeInfo());
//创建Table对象
Table tbl = new Table();
tbl.setDbName(DB_NAME);
tbl.setTableName(TBL_NAME);
tbl.setSd(sd);
//请求HMS持久化Table
hiveMetaStoreClient.createTable(tbl);上面示例代码将创建Hive的模板流程划分为4个步骤:
创建Fields
创建StorageDescriptor
创建Table对象
请求HMS持久化Table
总结
本文讲述了不同引擎,主要是Hive、Spark、Flink和Trino,在创建Iceberg表上存在的兼容性问题及其产生的原因,然后给出了解决办法。最后,通过抽象一种创建跟引擎无关的Iceberg表的表示方法及其创建步骤。该方法的重要作用是能够实现通用的元数据管理。
以上是关于如何创建与引擎独立的Iceberg表的主要内容,如果未能解决你的问题,请参考以下文章