2018/06/11 数据库设计规范
Posted 25-lh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018/06/11 数据库设计规范相关的知识,希望对你有一定的参考价值。
最近都没什么时间来写比克,工做太忙......
不过这也不是什么借口。
最近在学习相关知识,写下来记录一下吧。
注意:
这里的规范并不是绝对的,如果你的团队已经制定了规范。
请按照团队规范来实行。
如果没有,请尽量遵循基本规范。并推动制定规范。
数据库设计规范:
1:数据库名/表名 小写
数据库等于是在 Liunx 上的一个个文件,Linux 是区分大小写的,所以表/库也是如此,为了避免在大小写上引起的错误,尽量使用小写来作为统一规定。
2:不使用mysql关键字
关于这个问题,老生常谈了吧,不使用 mysql 的关键字,也是为了避免错误。
3: 临时表命名规范
在实际工作,不免要创建一些临时表进行工作,而且会有时忘记清理(很大可能).
最后也忘记了那个是临时表,所以需要对临时表的命名做出规范,以便于我们知道那个是临时表。
命名规范为:以tmp为前缀-日期为后缀
例如:tmp_temporary_20180611
3: 备份表命名规范
同上
命名规范为:bak为前缀_日期为后缀
例如:例如:bak_temporary_20180611
4:储存相同数据的列名和类类型必须一致
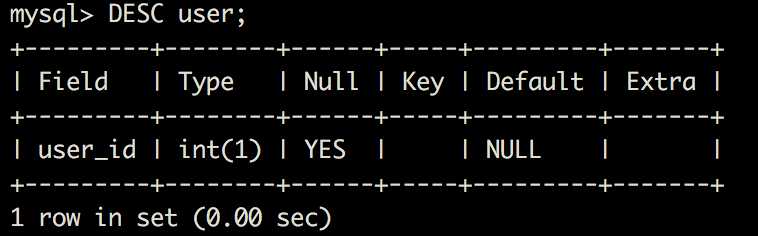
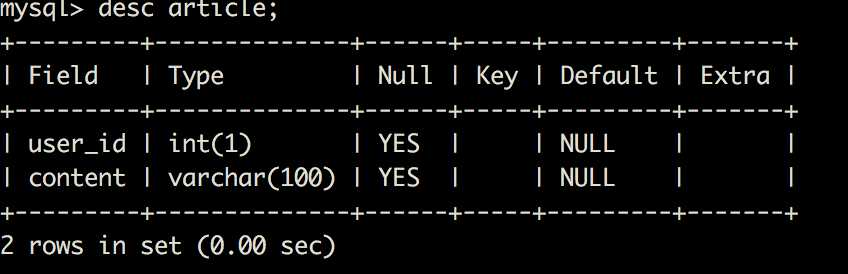
这里有两张表,一个用户ID,一个文章,文章一个外键是user_id
他们储存的是同种数据,所以在构建时,他们的数据类型等等必须都一致。
如果不一致,Mysql 其实是会在内部进行一个隐式的字符转换,会耗费性能。
5:统一使用innodb
在 mysql5.6 之后,默认引擎已经变为了 Innodb 。
和 innodb 相比,Myisam 的优势已经很小了,而且在混用的时候,Myisam 的工作并不是那么理想。
所以我们在没有特殊场景时候,应该默认使用 Innodb。
它的优势在很多地方都有 支持行锁/实务/高并发下效果更好
6:统一使用uft8
字符集一直是一个比较容易被忽视的地方,实际在任何时候,字符集都是一个比较重要的地方。
混乱的字符集会导致数据的丢失和无法恢复。
于是需要统一字符集,统一使用uft8。
7:表和字符添加注释
注释的意义,不用多言,同时数据表也是需要注释的。
从最开始 对于数据字典的维护 是非常有必要的,可以使后面的同学快速明白字段的意义。
也不会出现公司运转几年之后,拿出一张表,没有一个人能完整说出字段的意义这种窘境。
8: 尽量控制单表数据量大小
之前有人说,mysql的单表最大数是 500万。
关于这个并不是一个准确数字,他和操作系统,位数,等等都有关系。
不过太大,并不是个好事情,对于太大的表
-- 进行历史数据归档
-- 分库分表
9:尽量冷热分离,减少列数
尽量把冷热的数据区分开来,便于使用查询,提高读入效率。
减少表的列数,并不是越多越好, 表列多,在读入时就会消耗更多的内存。
建议经常使用的列放入一个列。
10: 禁止在表中预留字段
在开发中,经常会有预留字段的事情发生,因为可能知道之后需要补充一些字段。
这样感觉也没什么错,但是却造成了极大浪费。
一是由于预留字段无法见名知意,也会使用大字段VARCHAR()来进行存储。
在之后修改字段的话也会进行数据库的锁表,导致一段时间的服务异常。
怎么想都是不合算的,于是在开发时一定要避免这种事情的产生。
11:禁止存文件/图片 等二进制数据
太大,太长,你懂得
12:禁止在线上做压力测试/禁止从开发环境_测试 直接连接数据库
避免脏数据的产生,建议使用专门搭建的测试环境。
索引规范
索引并不是越多越好。
大量的索引会使Mysql优化器在选择时耗费大量的时间。
1: 限制每张表的索引数量
最好不好超过五个,索引不是越多越好,会提高/也会降低索引
禁止给每一列建立索引,并不會獲得很好的效果
2:在哪些列上建立索引?
在 select/update/delete SQL中的 where 条件中建立索引
在 order by / group by 字段上建立索引
3:如何选择索引列顺序(待研究)
区分度最高的列放在联合索引的最左侧
字段长度小的放在联合索引的最左侧
最频繁查询的字段放在联合索引的最左侧
4:尽量少使用外键
不建议使用外键约束,在使用外键约束时,会影响 父/子 的写性能。
推荐使用索引
字段设计规范
选择合适的字段类型会很大程度上提高整体性能
-- 优先选择符合存储需要的最小数据类型
-- 字符转化为数字类型存储
-- 对无符号数据采用无符号存储【省一倍空间】
-- 避免 TEXT 这种数据类型
-- 建议分离到单独的表中
-- 建议把所有列定义为 NOT NULL
-- 运算时会进行特别处理
-- 不建议储存时间类型为字符串,浪费
-- 建议使用 DATAETIME/TIMESTAMP 储存
-- 财务相关的,必须使用decial精确浮点类型
-- 计算不丢失精度
-- 可以保存比bigint更大的整数数据
-- sql 规范
-- 预编译优点
只传参数,跟高效
防范注入,一次解析,多次使用
-- 避免隐式转换
-- 可能导致索引失效
-- select * from user where id = ‘1‘;
-- 避免使用 %%/%*使用查询条件
-- 禁止跨库查询,连接不同数据库,使用不同账号
-- 为数据库迁移和分库分表留出余地
-- 避免权限过大导风险
-- 禁止 select *
-- 无用数据
-- 无法使用覆盖索引
-- 禁止使用不含字段列表的insert
-- ? inster into t values(‘a‘bc)
-- 避免表结构影响
-- 禁止使用子查询
-- 修改为 join
-- 子查询结果集不能使用索引
-- 临时表消耗IO/CPU
-- 避免 join 关联过多表
-- 多关联一个表,多耗一份内存
-- 最多61 建议不超过5个
以上是关于2018/06/11 数据库设计规范的主要内容,如果未能解决你的问题,请参考以下文章