面经联想大数据开发面经
Posted 和风与影
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面经联想大数据开发面经相关的知识,希望对你有一定的参考价值。
欢迎点击此处关注公众号。
1.说一下实习和学校做过什么事情,有什么收获。
问了一些细节。
2.Hive 怎么把 SQL 编译成 MapReduce
Hive 的基本流程:
-
UI 调用 DRIVER 的接口;
-
DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER 生成执行计划;
-
COMPILER 从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
-
COMPILER 生成的计划是分阶段的 DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者 HDFS 上的操作。将生成的计划发给 DRIVER。如果是 map/reduce 作业,该计划包括 map operator trees 和一个 reduce operator tree,执行引擎将会把这些作业发送给 MapReduce。
-
执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从 HDFS 文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时 HDFS 文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
-
最终的临时文件将移动到表的位置,确保不读取脏数据(文件重命名在 HDFS 中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接从 HDFS 读取,然后通过 Driver 发送到 UI。
编译 SQL 的任务是在上述的 COMPILER(编译器组件)中完成的。Hive 将 SQL 转化为 MapReduce 任务,整个编译过程分为六个阶段:
- 词法、语法解析:将 SQL 转化为抽象语法树 AST Tree;
- 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
- 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
- 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
- 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
其中重点是第 5 点生成物理执行计划。举例说明:
例 1 join on:
select u.name, o.orderid
from order o
join user u on o.uid = u.uid;
关于 join:在 map 的输出 value 中为不同表的数据打上 tag 标记,在 reduce 阶段根据 tag 判断数据来源。
关于 on:on 后面的字段就是 key,shuffle 的时候相同的 key 会进入同一个 reducer 中。
最后同一个 reduce 中 tag 不同的进行组合即可。

例 2 Group By:
select rank, isonline, count(*)
from city
group by rank, isonline;
将 Group By 的字段组合为 map 的输出 key 值,利用 MapReduce 的排序,在 reduce 阶段保存 LastKey 区分不同的 key。MapReduce 的过程如下:
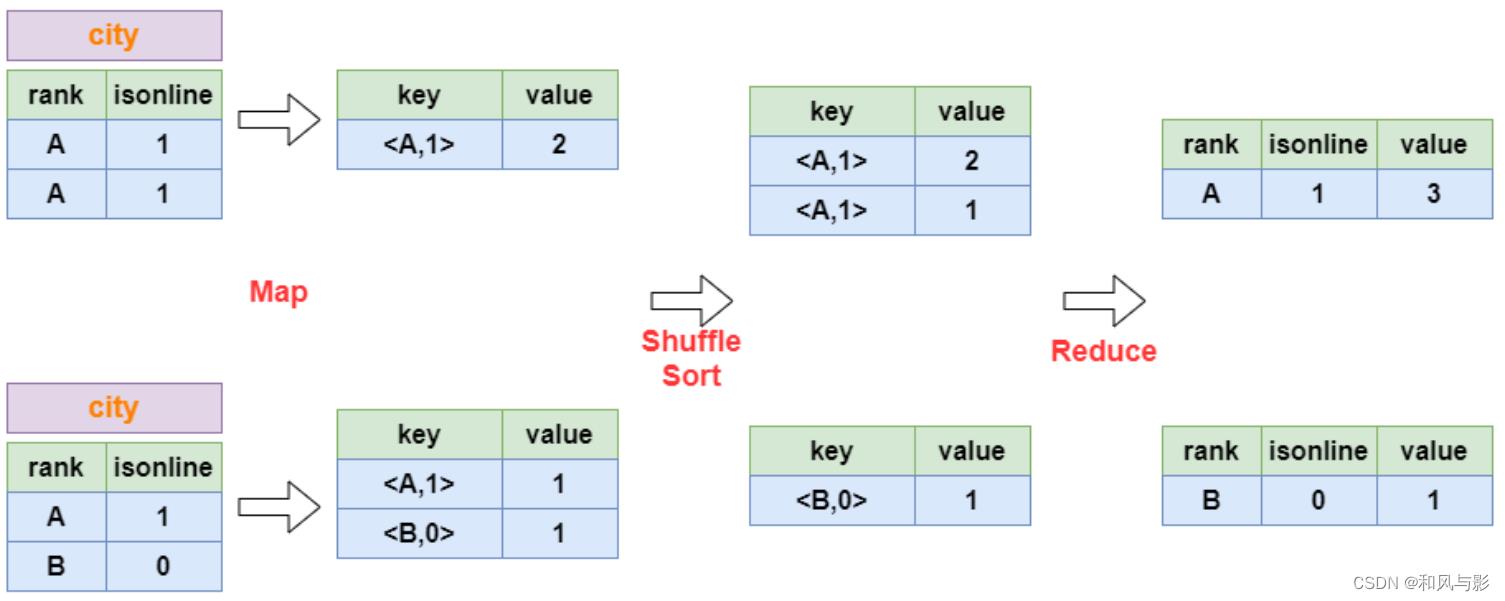
例 3 Distinct:
select dealid, count(distinct uid) num
from order
group by dealid;
当只有一个 distinct 字段时,如果不考虑 Map 阶段的 Hash Group By,只需要将 Group By 字段和 Distinct 字段组合为 map 输出 key,利用 mapreduce 的排序,同时将 Group By 字段作为 reduce 的 key,在 reduce 阶段保存 LastKey 即可完成去重。

3.Hive 调优用过哪些
小表大表Join(MapJoin)。
开启 Map 端聚合参数设置,防止数据倾斜。
一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式替换。
尽量避免笛卡尔积。
合理设置 Map 及 Reduce 数。
小文件进行合并。
严格模式:where 语句中含有分区字段过滤条件来限制范围,否则不允许执行。
JVM 重用。
压缩。
4.map join 的原理
mapJoin 适用于大表 join 小表,使用 DistributedCache 机制将小表存储到各个 Mapper 进程所在机器的磁盘空间上,各个 Mapper 进程读取不同的大表分片,将分片中的每一条记录与小表中所有记录进行合并。
合并后直接输出 map 结果即可得到最终结果。不需要进行 shuffle 流程,也不需要 reduce 处理。
5.从头到尾搭建数仓的环境,会有什么问题
框架选型:Apache、CDH、云服务器,各组件的兼容性。
服务器选型:数据量、预算、多久不扩容,算出需要对 CPU、内存、磁盘,集群规模。
节点功能规划:哪些机器部署哪些框架。
- 消耗内存的分开;
- kafka 、zk 、flume 传输数据比较紧密的放在一起;
- 客户端尽量放在一到两台服务器上,方便外部访问;
- 有依赖关系的尽量放到同一台服务器。
6.Linux 常用命令?一台新电脑要看配置(内存、磁盘、CPU)怎么看
常用命令
| 命令 | 命令解释 |
|---|---|
| top | 查看内存 |
| df -h | 查看磁盘存储情况 |
| iotop | 查看磁盘IO读写 |
| iotop -o | 直接查看比较高的磁盘读写程序 |
| netstat -tunlp | grep 端口号 | 查看端口占用情况 |
| uptime | 查看报告系统运行时长及平均负载 |
| ps -ef | 查看进程 |
linux 查看 cpu 信息的方法:使用 “cat /proc/cpuinfo” 命令。
7.JVM 的内存模型
8.查看 JVM 信息的命令
- jps:查看本地正在运行的 Java 进程和进程 ID(pid)。
- jinfo pid:查看指定 pid 的所有 JVM 信息。
- jinfo -flags pid:查询虚拟机运行参数信息。
- jinfo -flag name pid:查询具体参数信息。
- jmap:
- jmap -heap pid:输出堆内存设置和使用情况
- jmap -histo pid:输出 heap 的直方图,包括类名,对象数量,对象占用大小
- jmap -histo:live pid:同上,只输出存活对象信息
- jmap -clstats pid:输出加载类信息
- jmap -help:jmap 命令帮助信息
- jstat:Java 虚拟机统计工具,全称 “Java Virtual Machine statistics monitoring tool”。可以用于监视 JVM 各种堆和非堆内存大小和使用量。
- jstat -class pid:输出加载类的数量及所占空间信息。
- jstat -gc pid:输出 gc 信息,包括 gc 次数和时间,内存使用状况(可带时间和显示条目参数)。
- jstack:用于打印指定 Java 进程、核心文件或远程调试服务器的 Java 线程的 Java 堆栈跟踪信息。jstack 命令可以生成 JVM 当前时刻的线程快照。线程快照是当前 JVM 内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
9.别人写了一个 Java 程序,CPU 占用 100%,怎么查问题
上面的 6、7、8 都是这一问的铺垫。问题都是循序渐进的。
思路:定位 Java服务进程 → 定位 Java 线程 → 定位代码块。
- 通过
top命令可查看是哪个服务 cpu 使用率较高。 - 使用
ps来分析进程和线程的占用情况。 - 采用
jstack来进行虚拟机栈的区分。通过 16 进制的 TID 查找问题所在的代码块。
10.你相比于别人,工作上有什么优势。
该题是下面三个题的铺垫。
11.你怎么证明你的优势。
12.你要处理一个别人从来没解决过的问题,你怎么办。
13.假如昨天开源了一个大数据组件,没人知道应用场景,你怎么快速了解其应用场景。
以上是关于面经联想大数据开发面经的主要内容,如果未能解决你的问题,请参考以下文章