一节课让你学会从 MySQL 到 Kibana 微博用户及推文数据可视化
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一节课让你学会从 MySQL 到 Kibana 微博用户及推文数据可视化相关的知识,希望对你有一定的参考价值。
先上图,有图有真相!
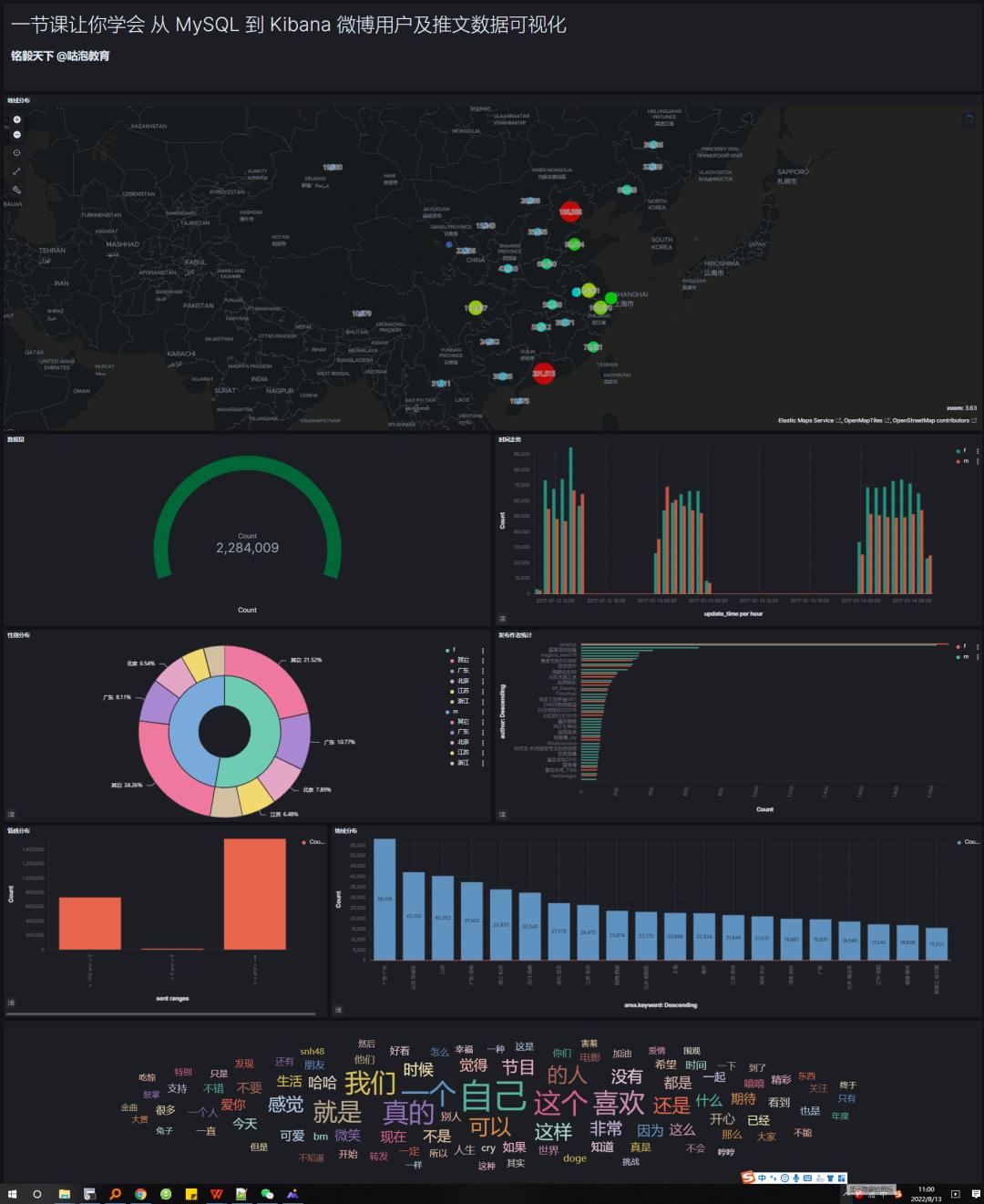 微博数据可视化
微博数据可视化
熟悉 Elastic Stack 的小伙伴对上面的图会感觉并不新鲜,对其中的技术栈也如数家珍,如下图一把梭走起:
 数据同步
数据同步
mysql 数据借助 Logstash 同步到 Elasticsearch,然后借助 Kibana 进行可视化。
但是,如下问题该如何解决呢?
问题 1:MySQL 不是全部字段都是结构化的,其中一个详情字段存储了 Json?
 MySQL 数据源
MySQL 数据源
问题 2:地图打点数据需要经纬度坐标,原始数据并没有,怎么办?
问题 3:Logstash 部署时,宿主机内存所剩无几,同步数据经常会出现内存耗尽,怎么办?
问题 4:Logstash 同步能否用 Kibana 可视化监控起来?
问题 5:8.X+ 系列和以往版本有没有什么不同或创新地方?
问题 6:数据如何建模才能更好的实现可视化?
问题7:字段无法满足可视化需求,Logstash filter 预处理和 Elasticsearch 预处理孰优孰劣?
问题 8:Kibana 可视化时,单字:”的“、”你“、”有“、”好“、”乐“等噪音数据非常多,如何一键搞定?而非手动过滤?
带着如上8个问题,我们开始今天的探索。
1、整体看待 Elastic Stack 技术栈的用途
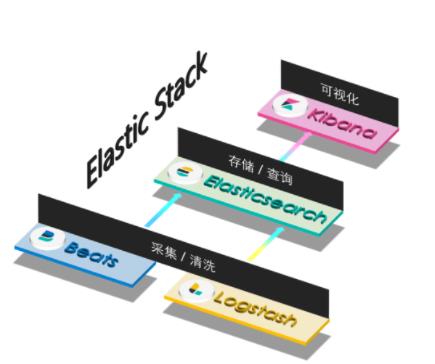 Elastic Stack 架构
Elastic Stack 架构
Elasticsearch:大数据预处理、存储和检索
Kibana:大数据可视化
 Kibana 功能图解
Kibana 功能图解
Logstash:数据同步管道,同步一切可同步数据源。借助其强大的同步插件实现,包含但不限于:
| 插件 | 用途 |
|---|---|
| logstash_input_jdbc | 各种数据库相关 |
| logstsh_input_redis | redis 数据同步 |
| logstash_input_kafka | kafka数据同步 |
| logstash_input_log4j | 日志数据同步 |
2、从数据流全局视角看待数据
当我们要进行数据分析、数据可视化的时候,首先要梳理清楚的是:数据从哪里来?数据要到那里去?
我们手头拿到的数据来自 MySQL,而你真实项目需求可能来自:Oracle、MongoDB、Spark、Kafka、Flink等等......
其实,来自哪里并不重要。
这些我们都统一归类为:数据源。
以终为始,最终我们期望借助 kibana 实现数据的可视化的分析。
那么最终数据需要落脚点为:Kibana,而 Kibana 是基于 Elasticsearch 数据进行分析的,所以:MySQL 数据需要先同步到 Elasticsearch。
借助什么来同步呢?当然可以自己写代码批量读、批量写。数据量大涉及到增量同步和全量分布,前文提到 Logstash 类似管道,可以实现同步一切可以同步的数据。
所以,可以借助:logstash 实现同步。当然,其他的同步工具:flume、Debezium、阿里开源的 canal 等等也可以实现。
选型方面可以参考如下的脑图:
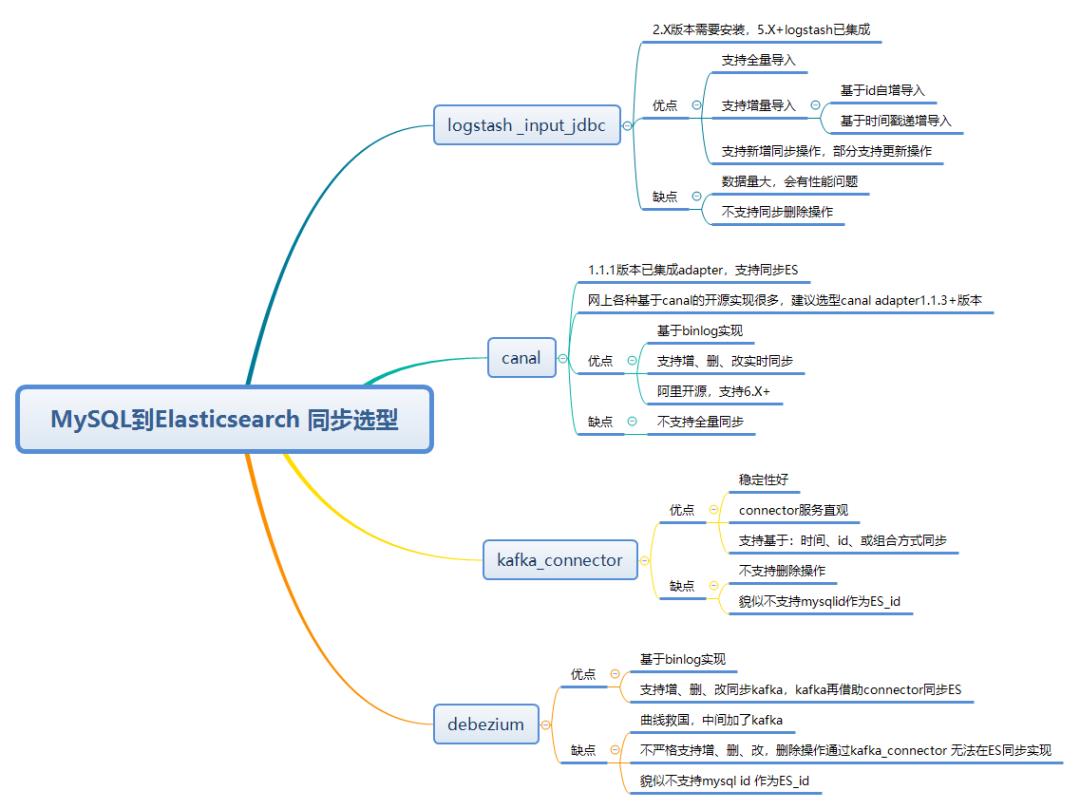
同步选型脑图
Logstash 支持增量和全量同步,我们选择 Logstash 实现 MySQL 到 Elasticsearch 同步。
所以整个数据流基本敲定:MySQL -> Logstash -> Elasticsearch -> Kibana。
3、从数据模型角度看待 Kibana 可视化
Kibana 可供可视化的维度最核心是基于 Elasticsearch 聚合实现的,而 Elasticsearch 聚合对应于 MySQL 的 groupby 等分组统计语句。
了解了这个本质之后,我们最终要考虑对数据可视化,往前推最重要的是需要考虑数据的模型和建模。
而数据源是微博数据(假数据),微博数据又细分为微博用户数据及微博推文数据,我们是一整条宽表存储到一起的。
可以预估实现的维度包含但不限于:
| 字段名称 | 字段含义 | 可视化类型 |
|---|---|---|
| publish_time | 推文时间 | 时间走势图 |
| un | 用户名 | 用途推文量排序统计图 |
| ugen | 用户性别 | 性别统计 |
| location | 发布省份 | 省份统计图 |
| uv | 是否认证 | 认证用户统计 |
| cont | 推文内容 | 推文内容词云 |
| sent | 情感 | 情感分类统计 |
| 自己完善 | 经纬度 | 地图打点图 |
这个环节为以 MySQL 已有数据为蓝本,然后构造出上面的表格。进而会发现问题。
当前问题主要包括:
1)MySQL 有一个字段 wb_detail Json 形式存储的,如何打散以便于后续的逐个字段分析?
2)有省份名称,没有经纬度,但是我们期望打点地图显示?
这些都是亟待解决的问题。
4、具体实现效果
4.1 MySQL 同步 Elasticsearch实现
批量值自己定义的,我内存不足,设定一次 10000条(后期调整为 20000,再大内存扛不住)数据。
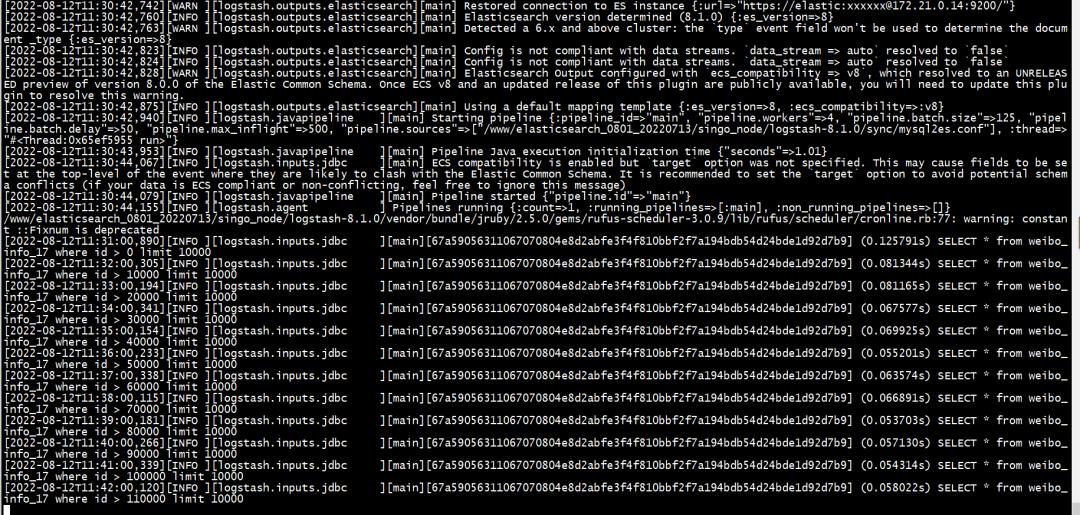
Logstash 同步截图
写入环节 Kibana 可视化监控效果图:
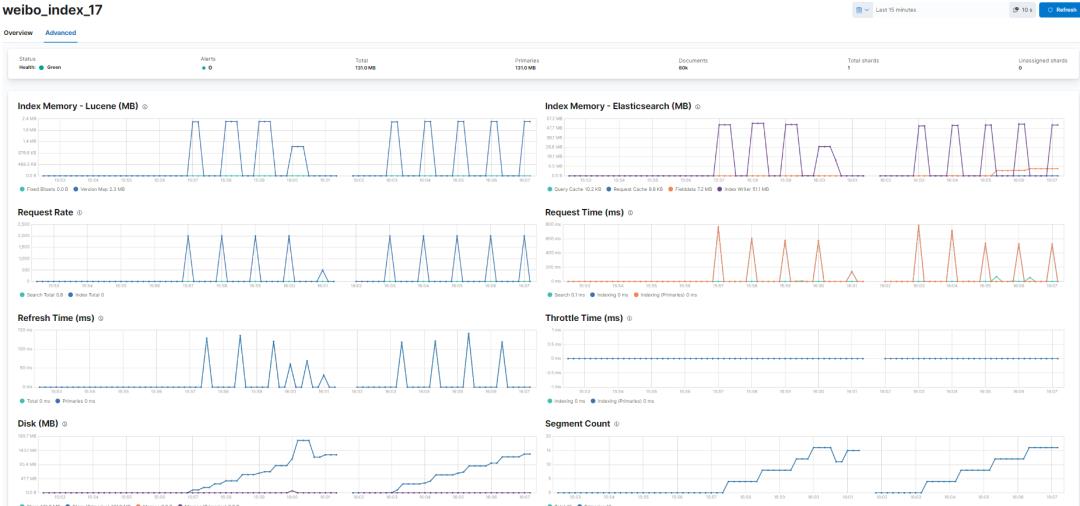
4.2 Logstash 监控的同步写入效果
写入比较平稳,资源利用率整体可控。
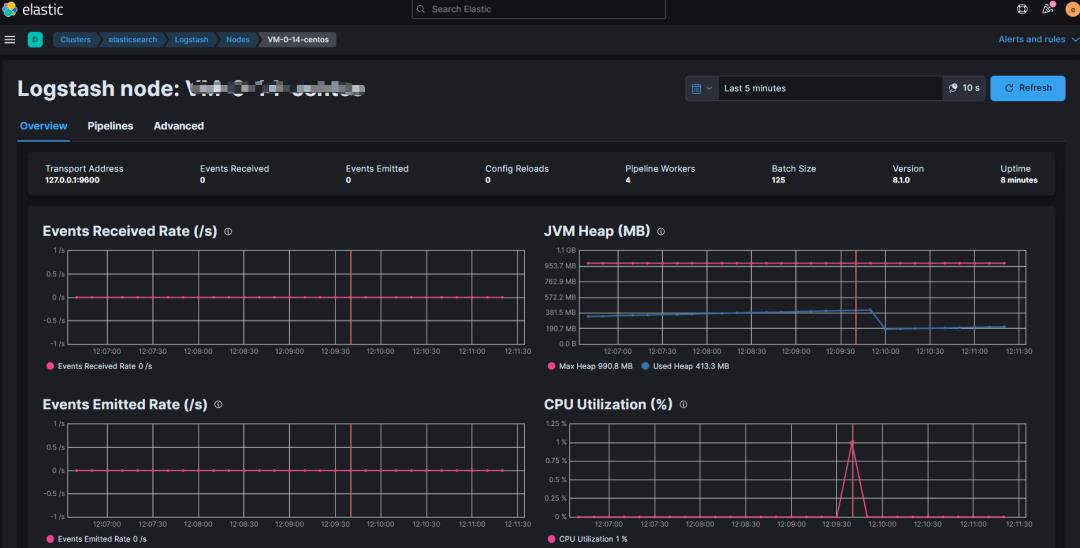

4.3 可视化效果
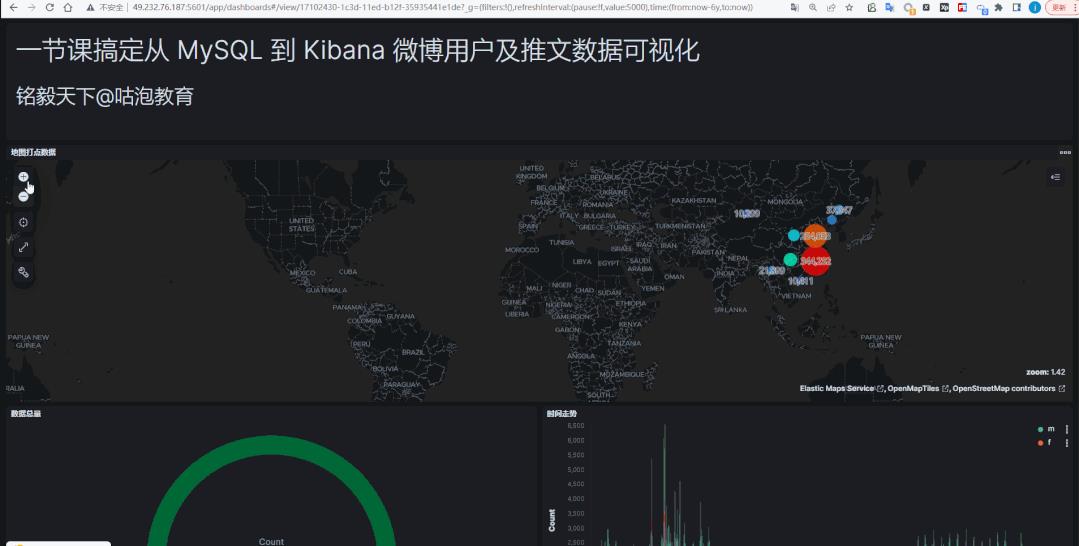
整体流程会比较清晰,但涉及的细节会非常多,篇幅原因,没有穷尽所有实现。
我们找个时间,直播带领大家走一遍。

以上是关于一节课让你学会从 MySQL 到 Kibana 微博用户及推文数据可视化的主要内容,如果未能解决你的问题,请参考以下文章