PyTorch笔记 - LSTM(Long Short-Term Memory) 和 LSTMP(Projection)
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch笔记 - LSTM(Long Short-Term Memory) 和 LSTMP(Projection)相关的知识,希望对你有一定的参考价值。
RNNCell:torch.nn.RNNCell
- input:输入向量的维度
- hidden:隐含层的维度
RNN是将多个RNNCell连接起来
文章:Understanding LSTM Networks,源码:torch.nn.LSTM
- i输入门、f遗忘门、g单元门、o输出门、c单元状态、h隐藏层

LSTM:
-
竖线:第1条线:遗忘门f、第2条线:输入门i、第3条线:单元门g、第4条线:输出门o
-
横线:上面是c单元状态(向下传递);下面是h隐藏状态(输出,向下传递)
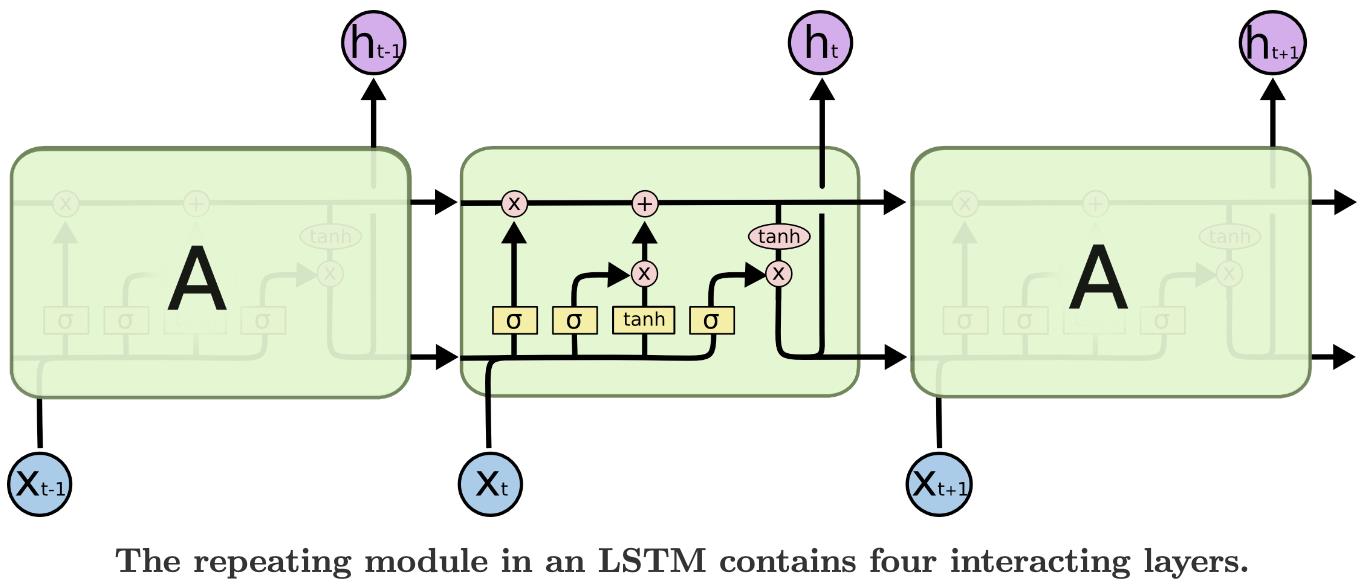
矩阵相乘,和点乘(Hadamard Product),即元素一一相乘:

LSTM也需要初始状态,有两个C和H,都是初始状态,即t-1下标的数值。
LSTM构造参数:
input_size:输入尺寸hidden_size:隐藏层尺寸num_layers:层数bias:是否使用偏置batch_first:批次在前,默认是批次在中间,即*(seq, batch, feature),如果为True,则(batch, seq, feature)*dropout:是否增加Dropout层,训练使用,推理不用bidirectional:是否为双向,如果是双向,则输出尺寸加倍,即2xhidden_sizeproj_size:LSTM网络的变体,即LSTMP,减少LSTM的参数和计算量,进行h_t进行压缩,性能损失不大
输入:
input:默认(L, N, H_in) ,batch_size在中间h_0、c_0:两个初始状态
输出:
output:全部状态,many2many的任务h_n:最后一个状态,many2one的任务,如果有proj_size参数,输出的尺寸由hidden_size变为proj_size;c_n:单元状态
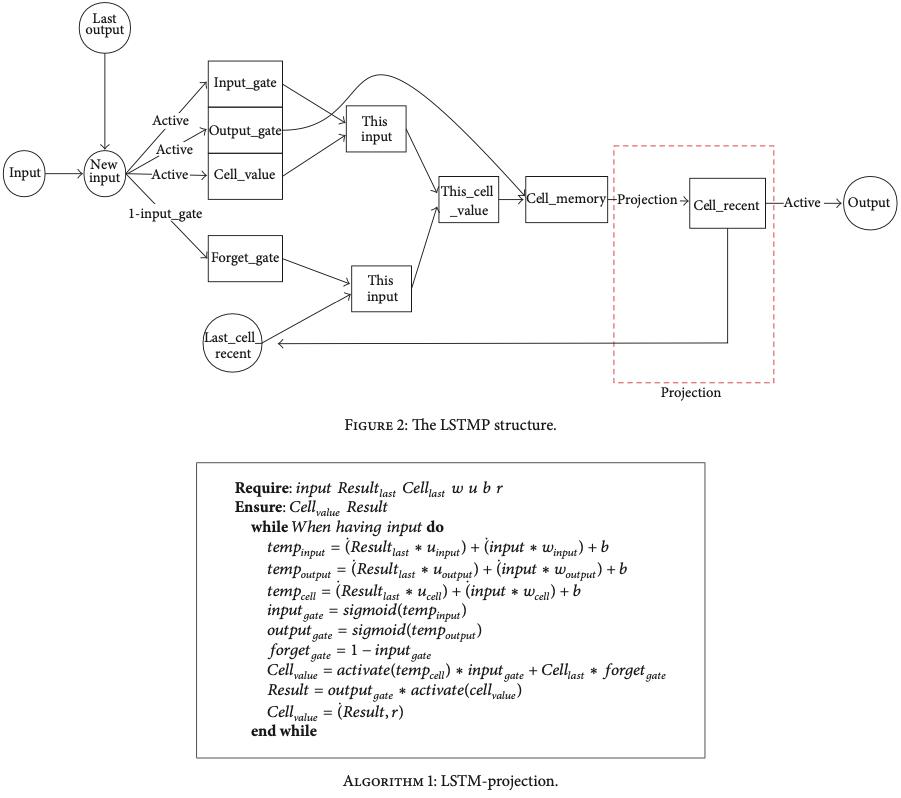
LSTM源码和LSTMP源码:
# 实现LSTM和LSTMP的源码
bs, T, i_size, h_size = 2, 3, 4, 5
proj_size = 3 # 压缩,proj_size要小于h_size
input = torch.randn(bs, T, i_size) # 输入序列
c_0 = torch.randn(bs, h_size) # 初始值,不需要训练
h_0 = torch.randn(bs, proj_size) # proj是对h进行压缩
# 调用官方LSTM API
lstm_layer = nn.LSTM(i_size, h_size, batch_first=True, proj_size=proj_size)
output, (h_final, c_final) = lstm_layer(input, (h_0.unsqueeze(0), c_0.unsqueeze(0)))
print(f'[Info] output:\\noutput')
print(f'[Info] h_final:\\nh_final') # 每个batch都会返回一个状态
print(f'[Info] c_final:\\nc_final')
# for k, v in lstm_layer.named_parameters():
# print(k, v.shape) # weight_ih_l0: [20, 4],20是4个weight合并至一起,即4x5,4是i_size
# 自定义的LSTM模型
def lstm_forward(input, initial_states, w_ih, w_hh, b_ih, b_hh, w_hr=None):
h0, c0 = initial_states # 初始状态
bs, T, i_size = input.shape
h_size = w_ih.shape[0] // 4
if w_hr is not None:
p_size, _ = w_hr.shape
output_size = p_size
batch_w_hr = w_hr.unsqueeze(0).tile(bs, 1, 1)
else:
output_size = h_size
output = torch.zeros(bs, T, output_size) # 输出序列
# 每个门,都是当前值x*w + 隐藏状态h*w,那么有两个w,一个是w_ih,一个是w_hh
batch_w_ih = w_ih.unsqueeze(0).tile(bs, 1, 1) # w_ih = [4*h_size, i_size]
batch_w_hh = w_hh.unsqueeze(0).tile(bs, 1, 1) # w_hh = [4*h_size, h_size]
prev_h, prev_c = h0, c0 # 循环更新h和c
# 每一时刻,都在对上一个时刻的更新
for t in range(T):
x = input[:, t, :] # 当前时刻的输入向量,[bs, i_size]
w_times_x = torch.bmm(batch_w_ih, x.unsqueeze(-1)) # [bs, 4*h_size, 1]
w_times_x = w_times_x.squeeze(-1) # 去掉最后一维,[bs, 4*h_size]
w_times_h_prev = torch.bmm(batch_w_hh, prev_h.unsqueeze(-1))
w_times_h_prev = w_times_h_prev.squeeze(-1)
# 分别计算输入门i,遗忘门f,单元门c,输出门o
i_t = torch.sigmoid(w_times_x[:, :h_size] + w_times_h_prev[:, :h_size] + \\
b_ih[:h_size] + b_hh[:h_size])
f_t = torch.sigmoid(w_times_x[:, h_size:h_size*2] + w_times_h_prev[:, h_size:h_size*2] + \\
b_ih[h_size:h_size*2] + b_hh[h_size:h_size*2])
g_t = torch.tanh(w_times_x[:, h_size*2:h_size*3] + w_times_h_prev[:, h_size*2:h_size*3] + \\
b_ih[h_size*2:h_size*3] + b_hh[h_size*2:h_size*3])
o_t = torch.sigmoid(w_times_x[:, h_size*3:] + w_times_h_prev[:, h_size*3:] + \\
b_ih[h_size*3:] + b_hh[h_size*3:])
prev_c = f_t * prev_c + i_t * g_t
prev_h = o_t * torch.tanh(prev_c) # [bs, h_size]
# Projection 对输出状态的压缩,prev_c不变,prev_h维度降低
if w_hr is not None:
prev_h = torch.bmm(batch_w_hr, prev_h.unsqueeze(-1))
prev_h = prev_h.squeeze(-1)
# print(output.shape, prev_h.shape)
output[:, t, :] = prev_h
return output, (prev_h, prev_c)
output_custom, (h_final_custom, c_final_custom) = lstm_forward(input, (h_0, c_0), lstm_layer.weight_ih_l0, lstm_layer.weight_hh_l0, \\
lstm_layer.bias_ih_l0, lstm_layer.bias_hh_l0, lstm_layer.weight_hr_l0)
print(f'[Info] output_custom:\\noutput_custom')
print(f'[Info] h_final_custom:\\nh_final_custom') # 每个batch都会返回一个状态
print(f'[Info] c_final_custom:\\nc_final_custom')
以上是关于PyTorch笔记 - LSTM(Long Short-Term Memory) 和 LSTMP(Projection)的主要内容,如果未能解决你的问题,请参考以下文章