论文笔记 Triformer: Triangular, Variable-Specific Attentions for Long SequenceMultivariate Time Series
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记 Triformer: Triangular, Variable-Specific Attentions for Long SequenceMultivariate Time Series相关的知识,希望对你有一定的参考价值。
1 abstract & introduction
- 长期时间序列预测(long term multivariate time-series forecasting)、
- 相比于RNN或者TCN,attention效果更好
- attention在捕获长期依赖关系中很常用,但是会存在两个问题
- 传统自注意力是
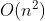 的复杂度(n是时间序列长度)——>效率欠佳
的复杂度(n是时间序列长度)——>效率欠佳 - 不同变量的时间序列通常由不同的时序动力,而现有的模型一般对这些变量使用统一的QKV投影函数(variable-agnoistic,对变量不感知的)——>精确度欠佳
- 传统自注意力是
- 为了解决上述的两个问题,这篇paper提出了Triformer
- 线性复杂度
- patch attention+三角层次结构
- ——>O(n)的复杂度
- 每个变量有自己的参数
- 对不同变量,有属于自己的、不同的参数
- 同时不用以效率/内存为代价
- 线性复杂度
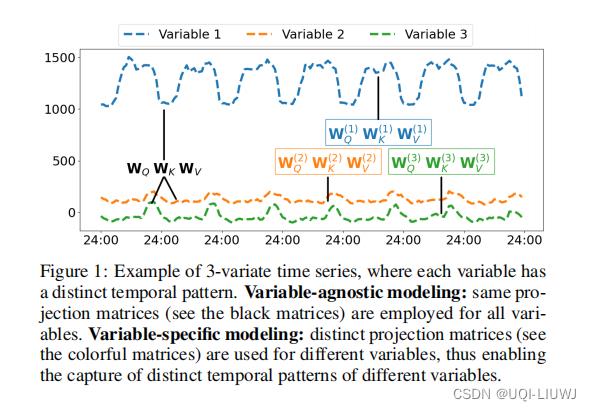
如果每个变量的参数都一样的话(比如这里共享投影矩阵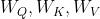 ),那么学到的可能只是平均pattern。
),那么学到的可能只是平均pattern。
Triformer对每个变量有一套自己的投影矩阵,同时经过特殊设计,逐变量的矩阵 参数量不大。
2 related works
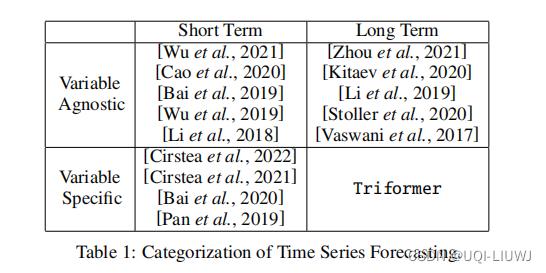
2.1 短期预测和长期预测
- 短期预测(12~48时间片之后),使用RNN/TCN是OK的,但是变成长期预测之后,RNN和TCN都只有很有限的能力,因为他们得靠中间的步骤一点一点将时序信息传过去 。——>RNN和TCN不太适用于长期预测。
- 对长期预测,self-attention在准确度上效果突出,但是在时间和空间上是的复杂度
- 有一些paper致力于找到稀疏的attention
- LogTrans(2019):
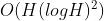
- Informer(2021):O(HlogH)
- LogTrans(2019):
- Transformer会保持输出的维度和输入一致
- 在迭代多层的attention的时候,上述方法会使用一个额外的池化层,来帮助将输入的尺寸缩小到和下一层attention需要的一致
- ——>本篇论文提出来的方法可以自己缩小每一层元素的数量,而不用池化操作
- 有一些paper致力于找到稀疏的attention
2.1.1 加池化的self-attention和本文的PA的对比
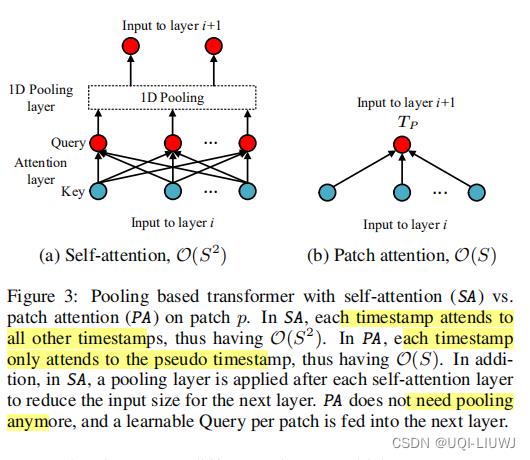
PA在不用池化的情况下,每一层可以缩小1/S倍
2.2 Variable-agnostic vs. variable-specifific modeling
- 大部分相关的工作是variable agnostic的
- 也就是各个变量的参数是一样的
- 比如RNN的权重矩阵,TCN的卷积核,attention中的投影矩阵。。。
- 也就是各个变量的参数是一样的
3 方法部分
3.1 时间序列标记
这里的一个多变量时间序列由N个变量组成。每一个时刻的观测为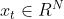 .
.
时间序列预测的意思是,通过过去H个时间片的信息,预测将来F个时间片的数据
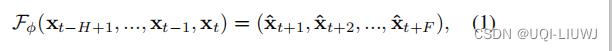
3.2 Triformer
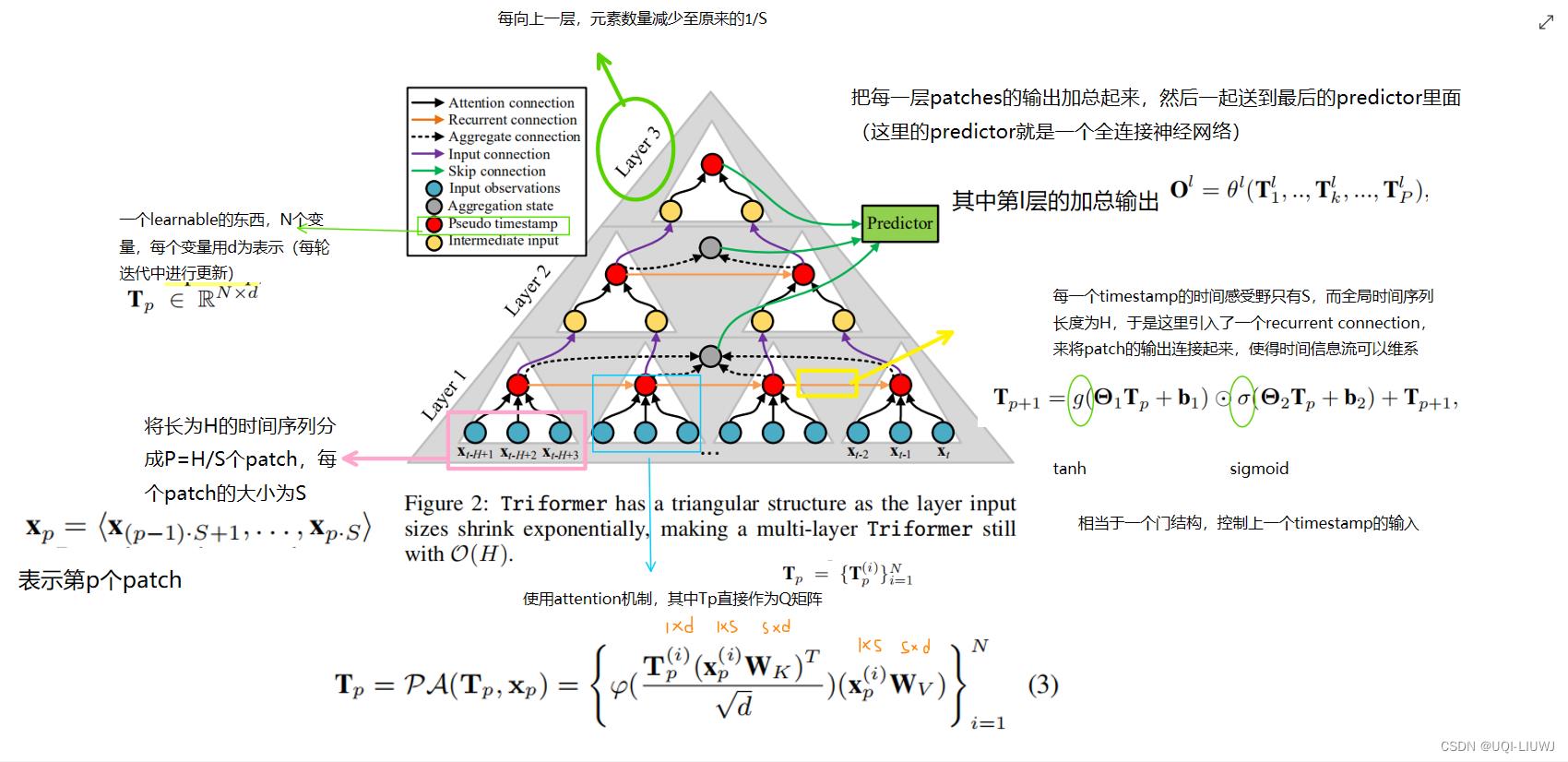
注:我觉得这边Wk和Wv应该有上标(i),且维度应该是s*d
3.3 Variable-Specific Modeling
最简单的实现方法,就是给每一个变量d*d的投影矩阵Wk和Wv,但是这样的话,需要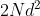 个参数。
个参数。
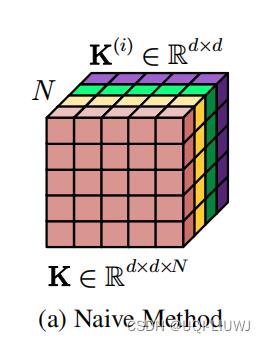
这篇论文使用了矩阵分解的思路:
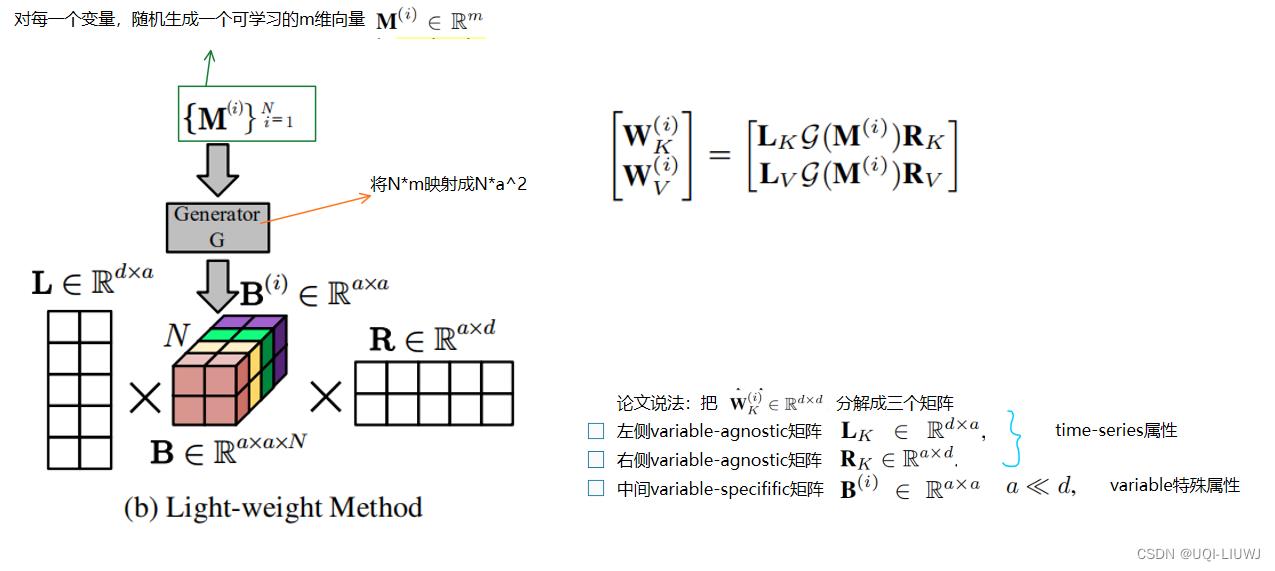
注:这里我还是不太理解为啥Wk和Wv是d*d维度,我认为是s*d
4 实验部分
4.1 实验配置
4.1.1 数据集
| ETTh1,ETTm1 | 每15min观察一次;每个观察有6个特征 (6变量的时间序列) |
| ECM | 321个变量的时间序列,每小时采样一次 UCI Machine Learning Repository: ElectricityLoadDiagrams20112014 Data Set |
| weather | 12元素的时间序列,每小时记录一次 |
4.2 实验分析
4.2.1 预测结果
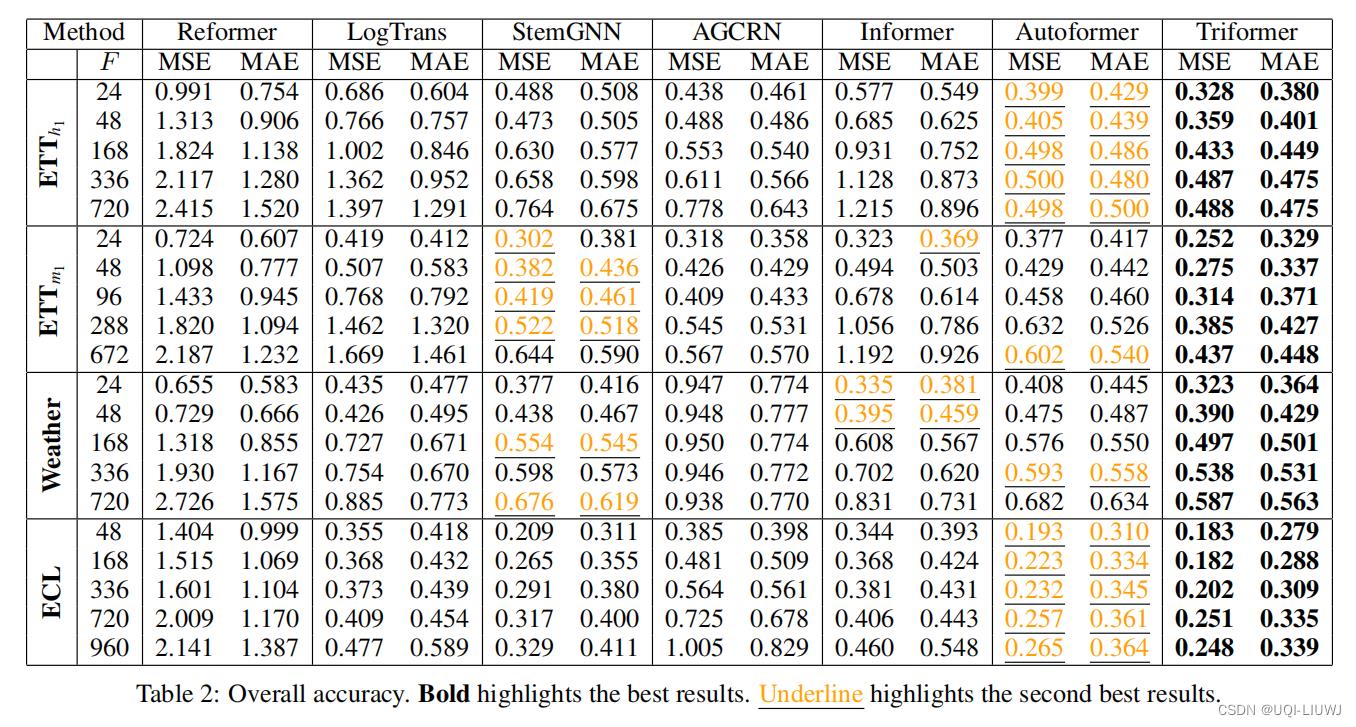
- 相比于其他三个variable-agnoistic的、基于attention的baseline,AGCRN效果最好
- ——>variable-specific 模型的好处
4.2.2 更长的序列的预测结果
把上面最优和次优的baseline拿出来进行比较
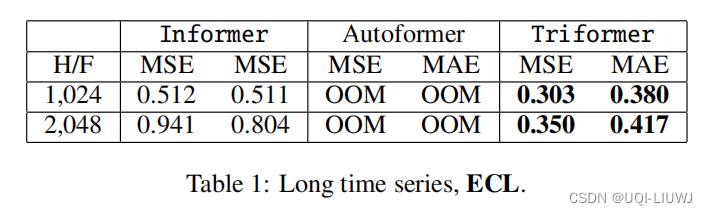
OOM——out of memory
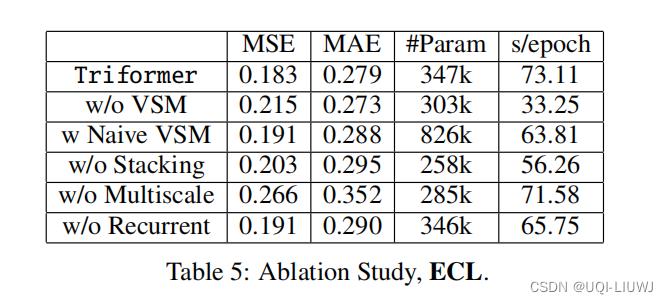
4.3 ablation study
4.3.1 消融实验
w/o 表示without
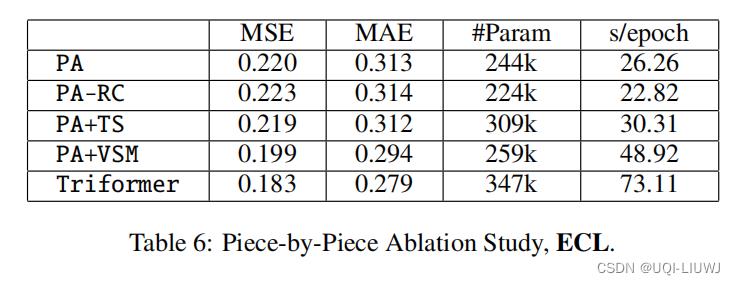
4.3.2 piece-by-piece ablation study
| PA | 单层patch attention |
| PA+TS | 多层patch attention |
| PA+vSM | 单层patch attention+3.3小节的VSM |
| Triformer | 相当于PA+TS+VSM |
| PA-RC | 没有recurrent connection的单层patch attention |
4.4 超参数敏感度
4.4.1 patch Size 大小S
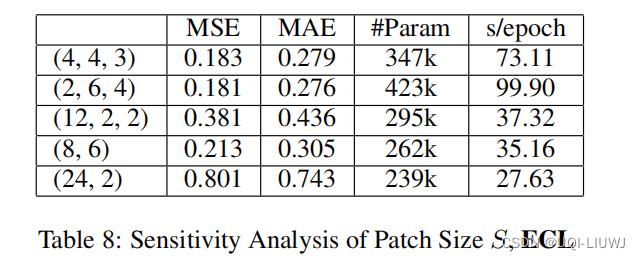
(a,b,c)表示三层各自的patch大小
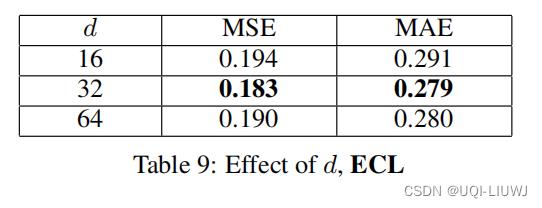
4.4.2 hidden representation 大小d
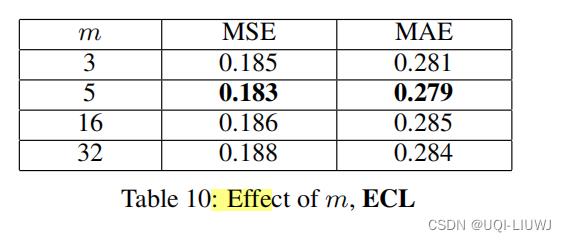
4.4.3 VSM中memory vector的维度m
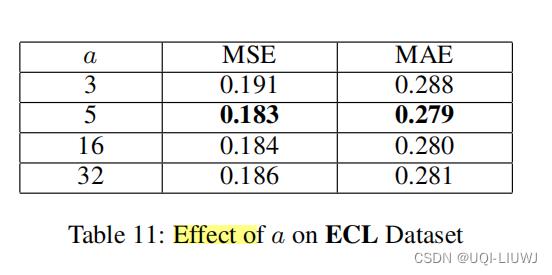
4.4.4 VSM中间矩阵的大小a
4.5 学到的内容的可视化
对VSM中的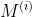 进行可视化,选择了8个时间序列,进行t-SNE,将每个 压缩至两维
进行可视化,选择了8个时间序列,进行t-SNE,将每个 压缩至两维
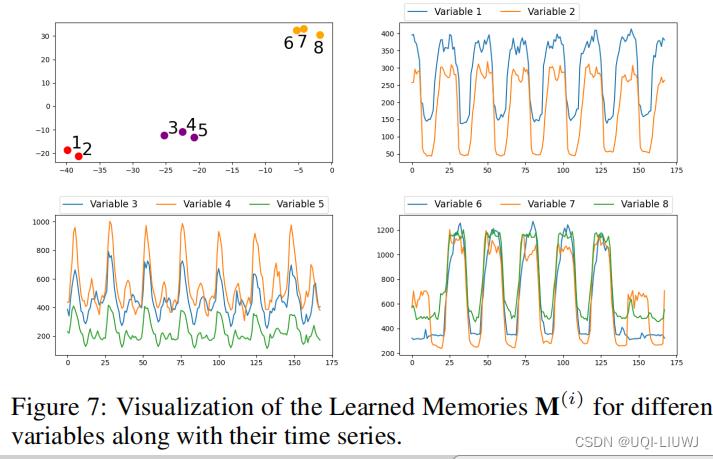
可以看到变量被分成了三类,每一类有接近的feature
以上是关于论文笔记 Triformer: Triangular, Variable-Specific Attentions for Long SequenceMultivariate Time Series的主要内容,如果未能解决你的问题,请参考以下文章