Hadoop运行模式编写Hadoop集群常用脚本Hadoop集群启停脚本常用端口号说明集群时间同步时间服务器配置其他机器配置
Posted Redamancy06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop运行模式编写Hadoop集群常用脚本Hadoop集群启停脚本常用端口号说明集群时间同步时间服务器配置其他机器配置相关的知识,希望对你有一定的参考价值。
文章目录
- 3.Hadoop运行模式
3.Hadoop运行模式
3.9编写Hadoop集群常用脚本
3.9.1Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
- [summer@hadoop102 ~]$ cd /home/summer/bin
- [summer@hadoop102 bin]$ vim myhadoop.sh

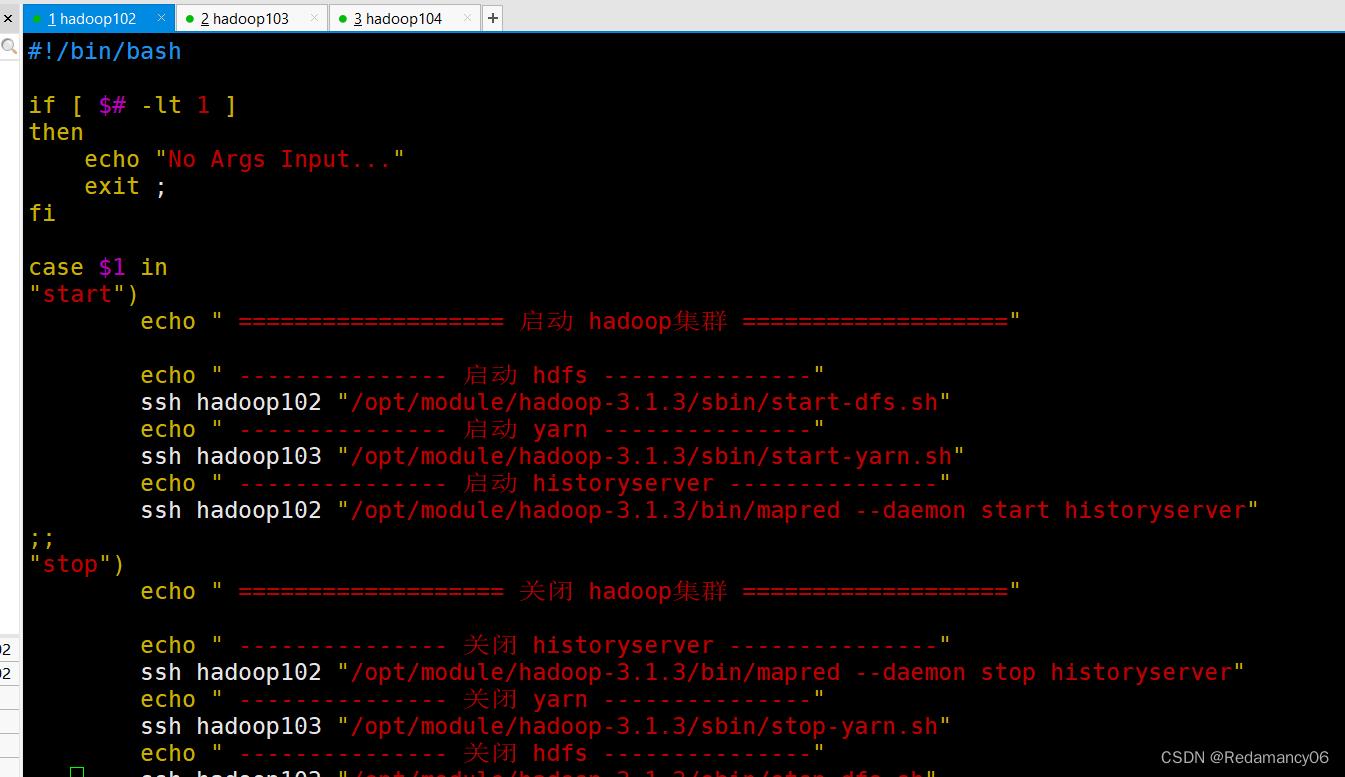
输入如下内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
保存后退出,然后赋予脚本执行权限
- [summer@hadoop102 bin]$ chmod 777 myhadoop.sh
3.9.1.1测试
- [summer@hadoop102 bin]$ myhadoop.sh stop



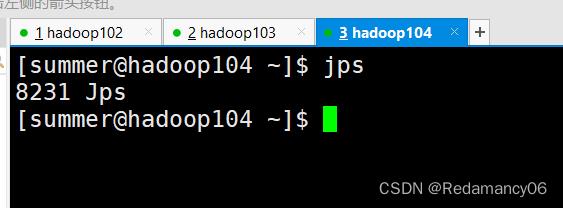
- [summer@hadoop102 bin]$ myhadoop.sh start

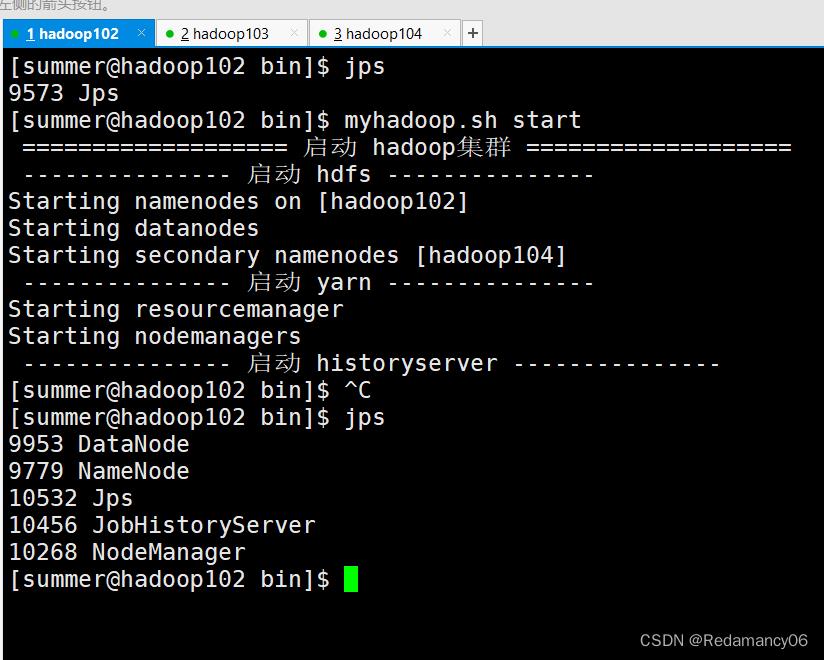


由于再查jps的时候每台服务器都需要输入命令,太麻烦了,因此写下面的脚本方便查jps
3.9.2查看三台服务器Java进程脚本:jpsall
- [summer@hadoop102 bin]$ vim jpsall

保存后退出,然后赋予脚本执行权限
- [summer@hadoop102 bin]$ chmod 777 jpsall
3.9.2.1测试结果

3.9.3分发/home/atguigu/bin目录,保证自定义脚本在三台机器上都可以使用
- [summer@hadoop102 ~]$ xsync /home/summer/bin/


3.10常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
3.11集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
3.11.1需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。

3.11.2时间服务器配置(必须root用户)
3.11.2.1查看所有节点ntpd服务状态和开机自启动状态
- [root@hadoop102 ~]# systemctl status ntpd
- [root@hadoop102 ~]# systemctl start ntpd
- [root@hadoop102 ~]# systemctl is-enabled ntpd
3.11.2.2修改hadoop102的ntp.conf配置文件
- [root@hadoop102 ~]# vim /etc/ntp.conf
修改内容如下
3.11.2.2.1修改1(授权192.168.159.0-192.168.159.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.159.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.159.0 mask 255.255.255.0 nomodify notrap
取消注释
3.11.2.2.2修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
3.11.2.2.3添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
在最后添加
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3.11.2.3修改hadoop102的/etc/sysconfig/ntpd文件
- [root@hadoop102 ~]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
3.11.2.4重新启动ntpd服务
- [root@hadoop102 ~]# systemctl start ntpd
3.11.2.5设置ntpd服务开机启动
- [root@hadoop102 ~]# systemctl enable ntpd
3.11.3其他机器配置(必须root用户)
3.11.3.1关闭所有节点上ntp服务和自启动
- [root@hadoop103 ~]# systemctl stop ntpd
- [root@hadoop103 ~]# systemctl disable ntpd
- [root@hadoop104 ~]# systemctl stop ntpd
- [root@hadoop104 ~]# systemctl disable ntpd
3.11.3.2在其他机器配置1分钟与时间服务器同步一次
- [root@hadoop104 ~]# crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
3.11.3.3修改任意机器时间
- [root@hadoop104 ~]# date -s “2022-8-7 22:11:11”
3.11.3.4 1分钟后查看机器是否与时间服务器同步
- [root@hadoop104 ~]# date
以上是关于Hadoop运行模式编写Hadoop集群常用脚本Hadoop集群启停脚本常用端口号说明集群时间同步时间服务器配置其他机器配置的主要内容,如果未能解决你的问题,请参考以下文章