MyBatis是什么?使用它作为持久层框架有什么优点?
Posted Java技术那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyBatis是什么?使用它作为持久层框架有什么优点?相关的知识,希望对你有一定的参考价值。

一、前言
在阅读本篇文章之前,我先提问一下:
- mybatis映射文件、核心配置文件、properties配置文件、日志文件到底在这个框架中各自的功能是什么?它们在文件夹中的位置该如何设定?
- resultMap、resultType有什么不同?什么时候要使用它们?
- 遇到像模糊查询时,我们该如何正确操作?
-
、$ 之间的区别是什么?各自使用的情景是什么?
- mybatis缓存是什么?
- 分步查询会不会?
- ...
废话不多说,满满的干货,赶快来看看吧~
二、基本介绍
一句话总结一下,MyBatis是一个基于Java的持久层框架,是一个半自动的ORM框架。那么可爱的它具有哪些很好的特性呢?
- 支持定制化 SQL、存储过程以及高级映射
- 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的操作
- 可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(实体类)映射成数据库中的记录
那么它有哪些优点呢?
- 轻量级,性能出色
- SQL 和 Java 编码分开,功能边界清晰。Java代码专注业务、SQL语句专注数据
好了,了解这些就差不多了,接下来进入Mybatis的知识世界!
三、搭建开发环境
首先要做的就是引入依赖,具体的pom.xml如下:
<packaging>jar</packaging>
<dependencies> <!-- Mybatis核心 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency> <!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency> <!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency><!-- log4j日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
这里需要注意的就是MySQL的驱动依赖了,我直接跟着视频走,使用的是版本5.7,结果可想而知,报错了,呜呜呜~
接着就是创建实体类、mapper接口、核心配置文件、映射文件,我给大家依次演示一下如何使用:
实体类:与数据库字段相关联,这个数据库在我的石墨文档第一个位置,大家可以自己运行一下SQL代码试一试
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User
private Integer id;
private String username;
private String password;
private Integer age;
private String sex;
private String email;
mapper接口:可以从官方文档中找案例复制下来——Mybatis官方文档
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.cabbage.mappers.UserMapper">
</mapper>
核心配置文件:跟mapper接口一样,也可以从官方中复制下来
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"/>
<typeAliases>
<package name="com.cabbage.pojo"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="$jdbc.driver"/>
<property name="url" value="$jdbc.url"/>
<property name="username" value="$jdbc.username"/>
<property name="password" value="$jdbc.password"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--<mapper resource="mappers/UserMapper.xml"/>-->
<package name="com.cabbage.mappers"/>
</mappers>
</configuration>
最后再来一个日记文件记录信息以及jdbc.properties配置文件
日志文件:可以当做是一种模板
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="STDOUT" class="org.apache.log4j.ConsoleAppender">
<param name="Encoding" value="UTF-8"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %dMM-dd HH:mm:ss,SSS %m (%F:%L) \\n"/>
</layout>
</appender>
<logger name="java.sql">
<level value="debug"/>
</logger>
<logger name="org.apache.ibatis">
<level value="info"/>
</logger>
<root>
<level value="debug"/>
<appender-ref ref="STDOUT"/>
</root>
</log4j:configuration>
jdbc.properties配置文件:配置数据库的连接信息——用户名、密码等等
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis
jdbc.username=
jdbc.password=
说了这么多配置文件,大家估计都懵了,这些文件各自放在什么目录下呢?大家可以参考一下我的位置
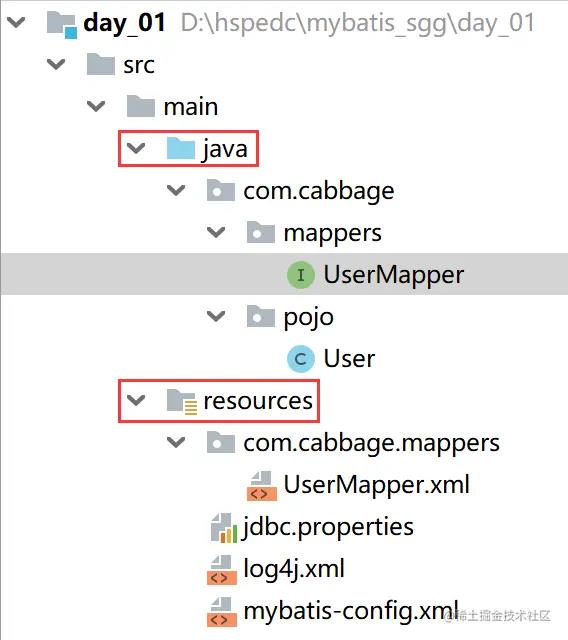
好了,各位小伙伴们,基本的环境搭建已经完成了,熟悉mybatis的小伙伴们看到这些文件中的属性,也知道各自是什么功能;不知道的小伙伴也不要着急,从案例中慢慢就会解密他们的各自功能以及使用方法。
四、核心配置文件
让我们回过头来看看刚才搭建的核心配置文件,如何使用?
- 1、
<properties/>
- 2、
<typeAliases></typeAliases>
-
3、
<mappers></mappers>
需要特别注意的是:在
resources文件夹下建包时,格式应该是下图的样式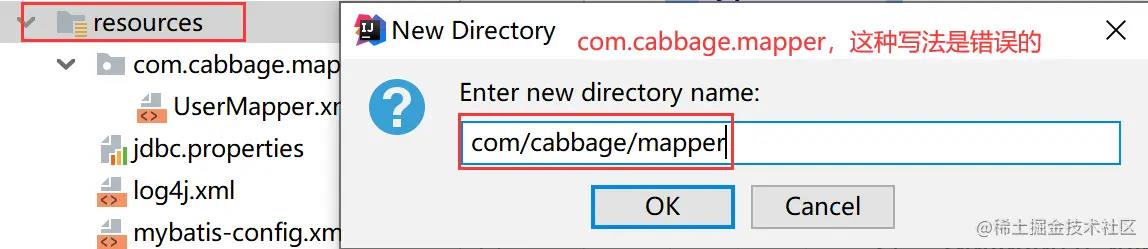
五、mapper映射文件
先看一下映射文件的命名规则:
- 表所对应的实体类的
类名+Mapper.xml
例如:表t_user,映射的实体类为User,所对应的映射文件为UserMapper.xml 因此一个映射文件对应一个实体类,对应一张表的操作
- MyBatis映射文件用于编写SQL,访问以及操作表中的数据
- MyBatis映射文件存放的位置是
src/main/resources/mappers目录下
此外,MyBatis中可以面向接口操作数据,要保证两个一致:
- mapper接口的全类名和映射文件的命名空间
(namespace)保持一致 - mapper接口中方法的方法名和映射文件中编写SQL的标签的id属性保持一致
写一个代码演示一下:查询表中id=3的user
<!--User selectById();-->
<select id="selectById" resultType="User">
SELECT * FROM t_user WHERE id = 3
</select>
public interface UserMapper
User selectById();
运行结果完全正确:

需要注意的是:
- 查询的标签select必须设置属性
resultType或resultMap,用于设置实体类和数据库表的映射 - resultType:自动映射,用于属性名和表中字段名一致的情况
- resultMap:自定义映射,用于一对多或多对一或字段名和属性名不一致的情况,这个后面就会讲到
- 当查询的数据为多条时,不能使用实体类作为返回值,只能使用集合,否则会抛出异常
TooManyResultsException;但是若查询的数据只有一条,可以使用实体类或集合作为返回值
六、参数值的两种方式(重点)
-
MyBatis获取参数值的两种方式:
$和# -
$的本质就是
字符串拼接,#的本质就是占位符赋值 -
$使用字符串拼接的方式拼接sql,若为字符串类型或日期类型的字段进行赋值时,需要手动加单引号;但是#使用占位符赋值的方式拼接sql,此时为字符串类型或日期类型的字段进行赋值时,可以自动添加单引号
在学习中,原本把参数值分为五种情况,最后介绍了注解@Param的使用,最后就把这五种情况归纳为两种情况,那就来介绍这两种情况吧!
- 1、实体类类型参数
- 2、使用@Param标识参数,使用该注解时,以@Param注解的值为键,以参数为值,或者以param1、param2为键,以参数为值
下面找一些具有代表性的代码,方便以后的回忆,小伙伴们也可以看看这些代码是否还知道是什么意思呀,测试代码就不写了

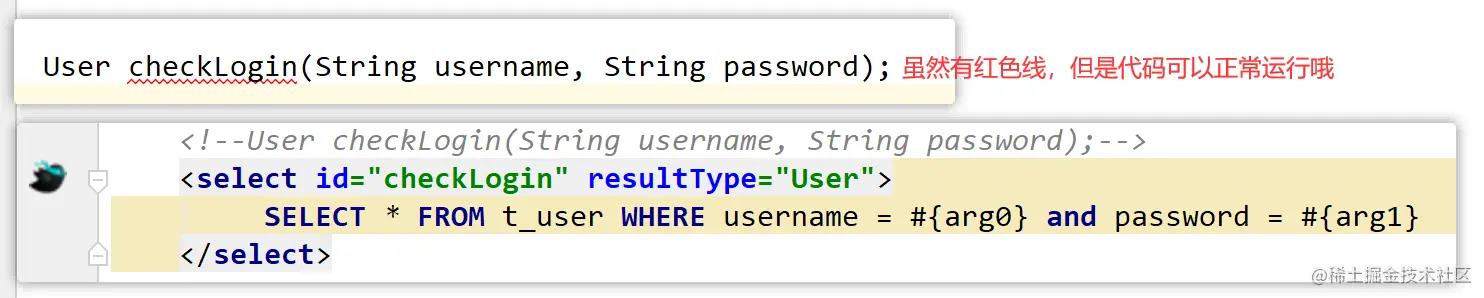
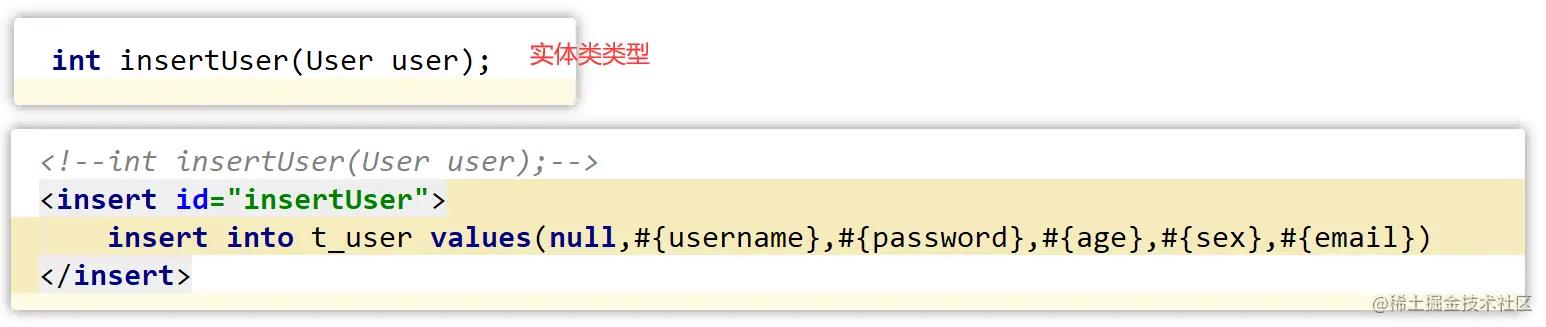
七、select的重点介绍
查询单个数据,这个很简单了
<!--Integer getCount();-->
<select id="getCount" resultType="integer">
select count(*) from t_user
</select>
查询一条数据为map集合,会把查询到的一个对象封装在map中
<!--Map<String,Object> getUserByIdToMap(@Param("id") Integer id);-->
<select id="getUserByIdToMap" resultType="map">
select * from t_user where id = #id
</select>
查询所有数据放入到map集合中
//方式一: List<Map<String,Object>> getAllUsersToMap();
@MapKey("id"),<!--把id当做map的键,查询的对象作为值返回过来-->
Map<String, Object> getAllUsersToMap();
对查询所有数据放入到map集合中这种方式,进行代码测试一下:
@Test
public void test4() throws IOException
SqlSession sqlSession = GetSqlSession.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// List<Map<String, Object>> mapList = mapper.getAllUsersToMap();
Map<String, Object> map = mapper.getAllUsersToMap();
// System.out.println(mapList);
System.out.println(map);
看一下查询的部分结果:
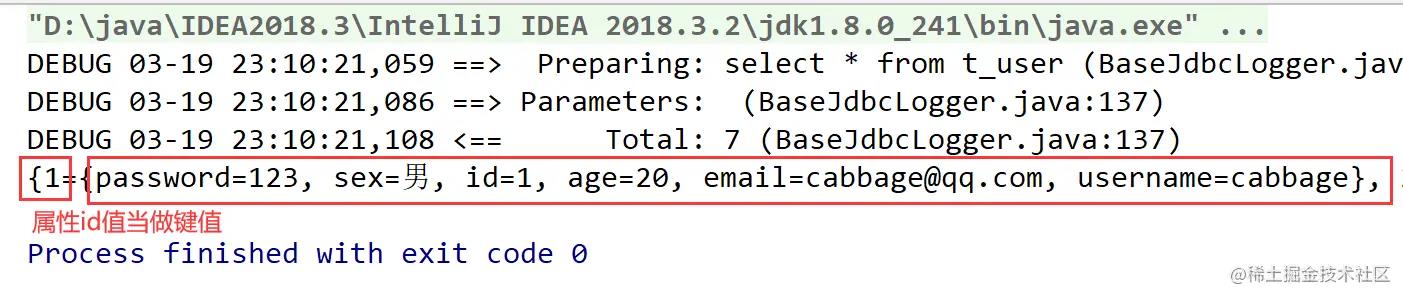
八、特殊SQL的查询
- 1、
模糊查询
<!--List<User> getUserByLike(@Param("username") String username);-->
<select id="getUserByLike" resultType="User">
select * from t_user where username like "%"#username"%"
</select>
- 2、
批量删除
<!--Integer deleteMore(@Param("ids") String ids);-->
<delete id="deleteMore">
delete from t_user where id in ($ids)
</delete>
代码演示一下:
@Test
public void test2() throws IOException
SqlSession sqlSession = GetSqlSession.getSqlSession();
SQLMapper mapper = sqlSession.getMapper(SQLMapper.class);
Integer result = mapper.deleteMore("7,8,9");
System.out.println(result);
复制代码
运行结果: [图片上传失败...(image-4c6888-1659663334477)]
- 3、
动态设置表名
<!--List<User> getAllUserByTableName(@Param("tableName") String tableName);-->
<select id="getAllUserByTableName" resultType="User">
select * from $tableName
</select>
- 4、
添加功能获取自增的主键
<!--int insertUser(User user);
useGeneratedKeys:设置使用自增的主键
keyProperty:因为增删改有统一的返回值是受影响的行数,
因此只能将获取的自增的主键放在传输的参数user对象的某个属性中
-->
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into t_user values (null,#username,#password,#age,#sex,#email)
</insert>
<!--这句话是什么意思呢?也就是说加入一个user对象的同时
,把该对象的自增键的值赋给id,通过调用getter方法拿到id值-->
代码演示一下:
@Test
public void test4() throws IOException
SqlSession sqlSession = GetSqlSession.getSqlSession();
SQLMapper mapper = sqlSession.getMapper(SQLMapper.class);
User user = new User(null, "cabbage8"
, "123454", 23, "男"
, "cabbage8@qq.com");
int result = mapper.insertUser(user);
System.out.println(result);
System.out.println(user.getId());
运行结果:

九、自定义resultMap
- 1、
resultMap处理字段和属性的映射关系,若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射
<resultMap id="mapEmp" type="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
</resultMap>
<!--List<Emp> getAllEmp();-->
<select id="getAllEmp" resultMap="mapEmp">
select eid,emp_name,age,sex,email,did from t_emp
--或者select eid,emp_name empName,age,sex,email,did from t_emp
</select>
resultMap:设置自定义映射属性:
- id:表示自定义映射的唯一标识
- type:查询的数据要映射的实体类的类型子标签:
- id:设置主键的映射关系
result:设置普通字段的映射关系
- property:设置映射关系中实体类中的属性名
- column:设置映射关系中表中的字段名
当然,若字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用),实体类中的属性名符合Java的规则(使用驼峰)时,可以在MyBatis的核心配置文件中设置一个全局配置信息mapUnderscoreToCamelCase,在查询表中数据时,自动将类型的字段名转换为驼峰 例如:字段名user_name,设置了mapUnderscoreToCamelCase,此时字段名就会转换为userName
- 2、
多对一映射处理,这是重点!
我们需要修改一下核心配置文件的内容,添加一些配置(这些配置在官方文档中都有介绍):
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--开启延迟加载-->
<setting name="lazyLoadingEnabled" value="true"/>
</settings>
三种方式的介绍:
<!--Emp getEmpAndDept(@Param("eid") Integer eid);-->
<!--方式一:级联属性赋值-->
<resultMap id="getEmpAndDeptMap1" type="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
<result property="dept.did" column="did"/>
<result property="dept.deptName" column="dept_name"/>
</resultMap>
<!--方式二:association解决映射关系-->
<resultMap id="getEmpAndDeptMap2" type="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
<association property="dept" javaType="Dept">
<result property="did" column="did"/>
<result property="deptName" column="dept_name"/>
</association>
</resultMap>
<!--方式三:分步查询-->
<!--
select:设置分步查询的SQL的唯一标识(namespace.方法名)
column:设置分步的查询条件
fetchType:当开启了全局的延迟加载之后,可通过此属性手动控制延迟加载的效果
eager,立即加载;lazy,懒加载
-->
<resultMap id="getEmpAndDeptByStepMap" type="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
<association property="dept"
select="com.cabbage.mappers.DeptMapper.getEmpAndDeptByStepTwo"
column="did"
fetchType="eager">
</association>
</resultMap>
<!--Emp getEmpAndDeptByStepOne(@Param("eid") Integer eid);-->
<select id="getEmpAndDeptByStepOne" resultMap="getEmpAndDeptByStepMap">
select * from t_emp where eid = #eid
</select>
方式三中DeptMapper.xml对应的分步查询的第二步:
<!--Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);-->
<select id="getEmpAndDeptByStepTwo" resultType="Dept">
select * from t_dept where did = #did
</select>
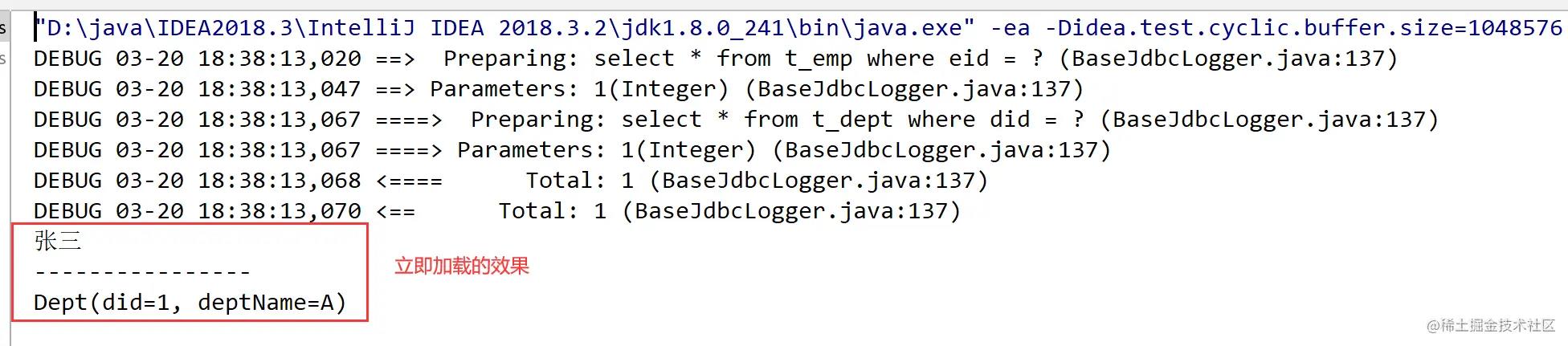
老师说,方式三在实际开发中使用的最多,方式三是一种懒加载,那咱们就测试一下方式三:
@Test
public void test3() throws IOException
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp emp = mapper.getEmpAndDeptByStepOne(1);
System.out.println(emp.getEmpName());
System.out.println("----------------");
System.out.println(emp.getDept());
运行结果:
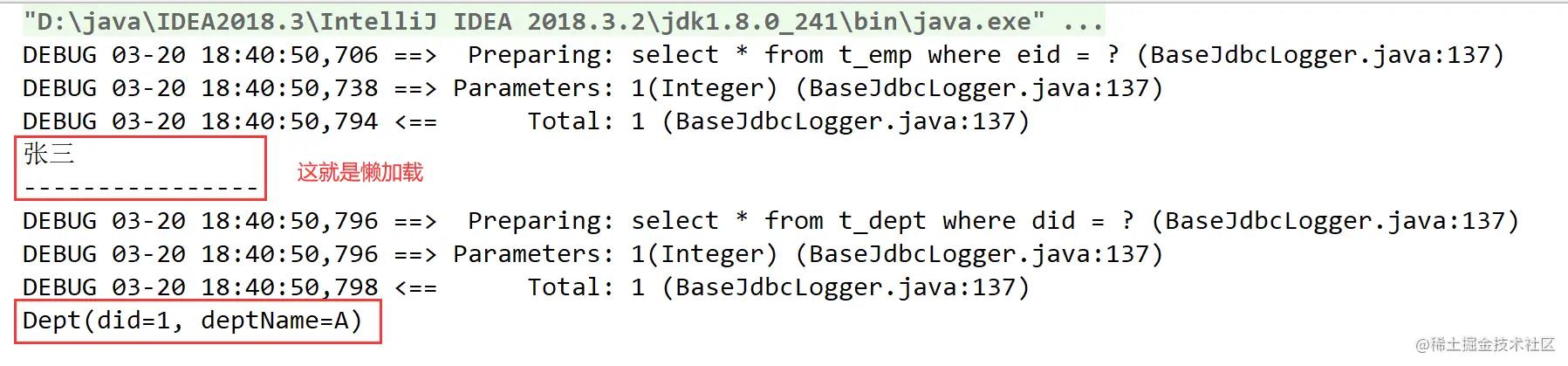
我们把eager改成lazy后的运行结果:
- 3、
一对多映射处理,这是重点!
<!--方式一:
collection:处理一对多的映射关系
ofType:表示该属性所对应的集合中存储数据的类型
-->
<resultMap id="getDeptAndEmpMap" type="Dept">
<result property="did" column="did"></result>
<result property="deptName" column="dept_name"></result>
<collection property="emps" ofType="Emp">
<result property="eid" column="eid"></result>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="email" column="email"></result>
<result property="sex" column="sex"></result>
<result property="did" column="did"></result>
</collection>
</resultMap>
<!--Dept getDeptAndEmp(@Param("did") Integer did);-->
<select id="getDeptAndEmp" resultMap="getDeptAndEmpMap">
select * from t_dept t1 left join t_emp t2 on t1.did = t2.did where t1.did = #did
</select>
<!--方式二-->
<resultMap id="getDeptAndEmpOneMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<collection property="emps"
select="com.cabbage.mappers.EmpMapper.getDeptAndEmpByStepTwo"
column="did">
</collection>
</resultMap>
<!-- Dept getDeptAndEmpOne(@Param("did") Integer did);-->
<select id="getDeptAndEmpOne" resultMap="getDeptAndEmpOneMap">
select * from t_dept where did = #did
</select>
方式二中EmpMapper.xml对应的分步查询的第二步:
<!--List<Emp> getDeptAndEmpByStepTwo(@Param("eid") Integer eid);-->
<select id="getDeptAndEmpByStepTwo" resultType="Emp">
select * from t_emp where did= #eid
</select>
写个测试代码:
@Test
public void test4() throws IOException
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept dept = mapper.getDeptAndEmpOne(1);
System.out.println(dept);
十、动态SQL
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题。接下来就为大家逐一介绍他们的使用代码
- 1、
if的使用:if标签可通过test属性的表达式进行判断,若表达式的结果为true,则标签中的内容会执行;反之标签中的内容不会执行
<!--List<User> getUserByCondition(User user);-->
<select id="getUserByCondition" resultType="User">
select * from t_user where 1=1
<if test="username !=null and username != ''">
and username = #username
</if>
<if test="password != null and password != ''">
and password = #password
</if>
</select>\\
这个语句是什么意思呢?其实就是我们传入一个实体对象,对象的username、password属性不为空或者不为null,就查询。对应的SQL语句是:select * from t_user where 1=1 and username = ? and password = ?
- 2、
where的使用
<!--List<User> getUserByWhere(User user);-->
<select id="getUserByWhere" resultType="User">
select * from t_user
<where>
<if test="username != null and username != ''">
and username = #username
</if>
<if test="password != null and password != ''">
and password = #password
</if>
</where>
</select>
\\
where和if一般结合使用: 1、若where标签中的if条件都不满足,则where标签没有任何功能,即不会添加where关键字 2、若where标签中的if条件满足,则where标签会自动添加where关键字,并将条件最前方多余的 and去掉 3、注意:where标签不能去掉条件最后多余的and
- 3、
trim的使用
<!--List<User> getUserByTrim(User user);-->
<select id="getUserByTrim" resultType="User">
select * from t_user
<trim prefix="where" suffixOverrides="and">
<if test="username != null and username != ''">
username = #username and
</if>
<if test="password != null and password != ''">
password = #password and
</if>
</trim>
</select>
\\\\\\
trim用于去掉或添加标签中的内容,常用属性: 1、prefix:在trim标签中的内容的前面添加某些内容 2、prefixOverrides:在trim标签中的内容的前面去掉某些内容 3、suffix:在trim标签中的内容的后面添加某些内容 4、suffixOverrides:在trim标签中的内容的后面去掉某些内容
- 4、
choose、when、otherwise的使用,相当于if...else if..else,满足一个if条件就不会执行下一个条件了
<!--List<User> getUserByIfElse(User user);-->
<select id="getUserByIfElse" resultType="User">
select * from t_user
<where>
<choose>
<when test="username != null and username != ''">
username = #username
</when>
<when test="password != null and password != ''">
password = #password
</when>
<otherwise>
id = 3
</otherwise>
</choose>
</where>
</select>
- 5、
foreach的使用
<!--int insertByForeach(@Param("users") List<User> list);-->
<insert id="insertByForeach">
insert into t_user values
<foreach collection="users" item="item" separator=",">
(null,#item.username,#item.password,#item.age,#item.sex,#item.email)
</foreach>
</insert>
<!--对应的SQL语句就是:insert into t_user values (null,?,?,?,?,?) , (null,?,?,?,?,?)-->
<!--int deleteByForeach(@Param("id") int[] id);-->
<delete id="deleteByForeach">
delete from t_user where id in
<foreach collection="id" open="(" close=")" separator="," item="item">
#item
</foreach>
</delete>
<!--对应的SQL语句是:delete from t_user where id in ( ? , ? )-->
一起来看看其中的属性: 1、collection:设置要循环的数组或集合 2、item:表示集合或数组中的每一个数据 3、separator:设置循环体之间的分隔符 4、open:设置foreach标签中的内容的开始符 5、close:设置foreach标签中的内容的结束符
- 6、
SQL片段的使用,可以记录一段公共sql片段,在使用的地方通过include标签进行引入
<sql id="selectAll">
id,username,password,age,sex,email
</sql>
<!--比如我们把select * 这个查询字段可以改为表中所有的字段到sql片段中,
最后再把 *去掉,引入sql片段就可以了-->
select <include refid="selectAll"></include> from t_user
十一、MyBatis的缓存
对于这一部分的讲解,我不打算举例代码,因为相信学过mybatis的小伙伴们,看看对缓存的文字介绍,就可以回想起缓存所具有的特点,那么咱们就先从一级缓存开始吧!
一级缓存是SqlSession级别的,通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就会从缓存中直接获取,不会从数据库重新访问。把握两点:一是同一个sqlsession,二是查询相同的数据。缓存影响着我们的查询速度,但不影响我的查询数据!
使一级缓存失效的四种情况:
- 不同的SqlSession对应不同的一级缓存
- 同一个SqlSession但是查询条件不同
- 同一个SqlSession两次查询期间执行了任何一次增删改操作(注意一下)
- 同一个SqlSession查询期间手动清空了缓存(
sqlSession.clearCache();)
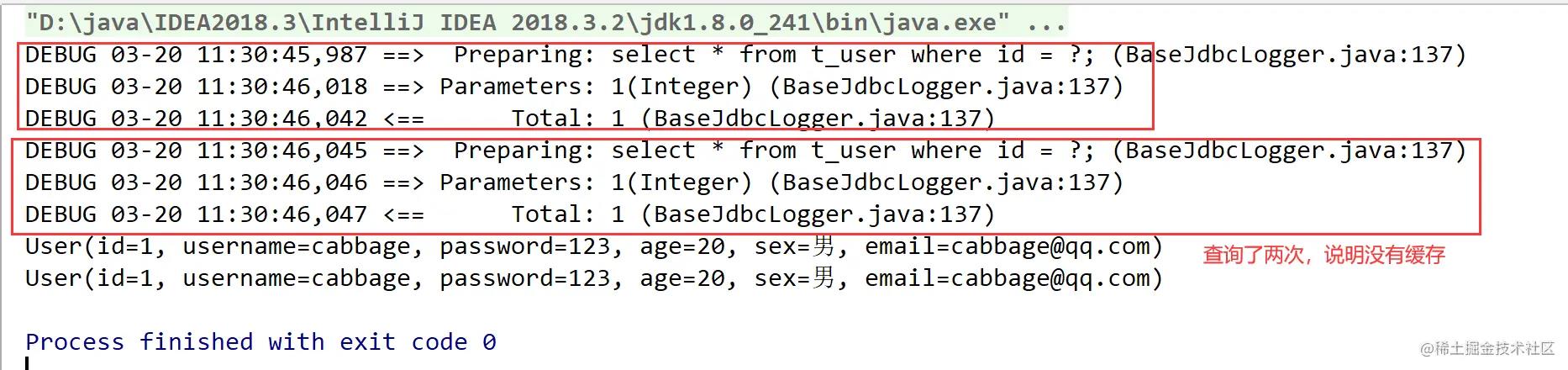
还是演示一下手动清空缓存的情况吧:
@Test
public void test1() throws IOException
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = factoryBuilder.build(inputStream);
SqlSession sqlSession = factory.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
UserMapper mapper1 = sqlSession.getMapper(UserMapper.class);
User user = mapper.selectById(1);
sqlSession.clearCache();
User user1 = mapper1.selectById(1);
System.out.println(user);
System.out.println(user1);
运行结果:
二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取
二级缓存开启的条件:
- 在核心配置文件中,设置全局配置属性cacheEnabled="true",默认为true,不需要设置
- 在映射文件中设置标签
<cache /> - 二级缓存必须在SqlSession关闭或提交之后有效(不要忘记了哦)
- 查询的数据所转换的实体类类型必须实现序列化的接口(
implements Serializable)
使二级缓存失效的情况:
- 两次查询之间执行了任意的增删改,会使一级和二级缓存同时失效
演示一下二级缓存:
@Test
public void test2() throws IOException
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = factoryBuilder.build(inputStream);
SqlSession sqlSession = factory.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user1 = mapper.selectById(1);
System.out.println(user1);
sqlSession.close();//关闭一个后,放入了二级缓存中
SqlSession sqlSession1 = factory.openSession(true);
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
User user = mapper1.selectById(1);
System.out.println(user);
sqlSession1.close();
运行结果:
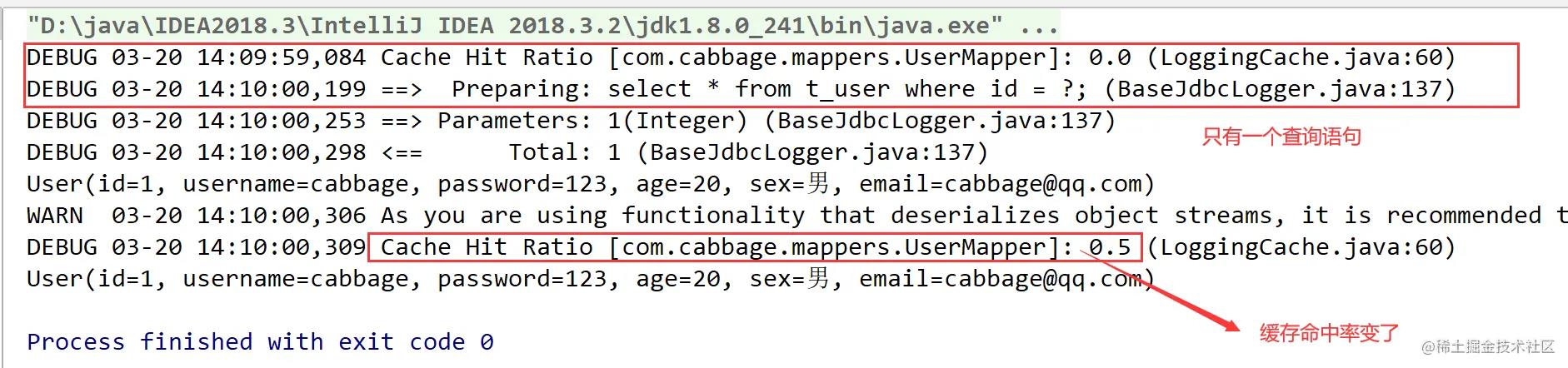
二级缓存的相关配置,这一部分老师没有细讲,摘录下来,了解一下。在mapper配置文件中添加的cache标签可以设置一些属性:
eviction属性:缓存回收策略LRU(Least Recently Used) – 最近最少使用的:移除最长时间不被使用的对象。 FIFO(First in First out) – 先进先出:按对象进入缓存的顺序来移除它们。 SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。 WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 默认的是 LRU。flushInterval属性:刷新间隔,单位毫秒,默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新size属性:引用数目,正整数代表缓存最多可以存储多少个对象,太大容易导致内存溢出readOnly属性:只读,true/false true:只读缓存;会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。 false:读写缓存;会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
最后来讲一讲MyBatis缓存查询的顺序:
- 先查询二级缓存,因为二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用。
- 如果二级缓存没有命中,再查询一级缓存
- 如果一级缓存也没有命中,则查询数据库
SqlSession关闭之后,一级缓存中的数据会写入二级缓存
十二、创建逆向工程
什么是逆向工程呢?就是先创建数据库表,由框架负责根据数据库表,反向生成如下资源:
- Java实体类、mapper接口、mapper映射文件
那么就开始根据步骤创建逆向工程吧!
首先需要添加依赖和插件,这里有些依赖使用已经在前面使用过了,大家可以注意一下哦
<!-- 依赖MyBatis核心包 -->
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies> <!-- 控制Maven在构建过程中相关配置 -->
<build> <!-- 构建过程中用到的插件 -->
<plugins> <!-- 具体插件,逆向工程的操作是以构建过程中插件形式出现的 -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.0</version> <!-- 插件的依赖 -->
<dependencies> <!-- 逆向工程的核心依赖 -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency> <!-- 数据库连接池 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.2</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
接着创建MyBatis的核心配置文件以及逆向工程的配置文件,第一个配置文件已经讲过了,来看看逆向工程配置文件如何创建(使用时,发现实体类属性值补全,后来完善了一下视频中的笔记,加了一个配置):
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!-- targetRuntime: 执行生成的逆向工程的版本 MyBatis3Simple:
生成基本的CRUD(清新简洁版)
MyBatis3: 生成带条件的CRUD(奢华尊享版) -->
<context id="DB2Tables" targetRuntime="MyBatis3">
<!-- 数据库的连接信息 -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver" connectionURL="jdbc:mysql://localhost:3306/mybatis"
userId="root" password="">
<!-- 解决table schema中有多个重名的表生成表结构不一致问题 -->
<property name="nullCatalogMeansCurrent" value="true"/>
</jdbcConnection>
<!-- javaBean的生成策略-->
<javaModelGenerator targetPackage="com.cabbage.pojo" targetProject=".\\src\\main\\java">
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- SQL映射文件的生成策略 -->
<sqlMapGenerator targetPackage="com.cabbage.mappers" targetProject=".\\src\\main\\resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- Mapper接口的生成策略 -->
<javaClientGenerator type="XMLMAPPER" targetPackage="com.cabbage.mappers"
targetProject=".\\src\\main\\java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- 逆向分析的表 --> <!-- tableName设置为*号,可以对应所有表,此时不写domainObjectName -->
<!-- domainObjectName属性指定生成出来的实体类的类名 -->
<table tableName="t_user" domainObjectName="User"/>
</context>
</generatorConfiguration>
需要注意的是:逆向工程配置文件的数据库相关的信息还是需要自己修改配置的
最后执行插件,如图所示:
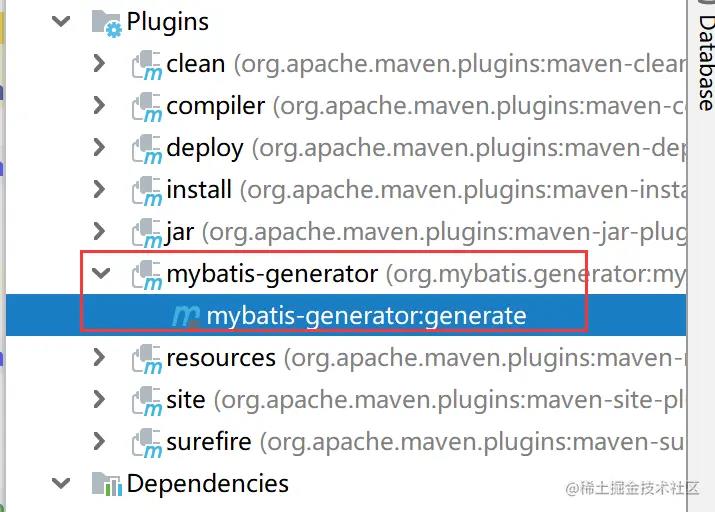
使用逆向工程生成的目录给大家看一下,可以看出跟我们自己手动创建的一模一样,是不是很简便呢?

好了,本文对MyBatis的知识总结就到这里了,在复习的过程中,对使用逆向工程后的方法没有具体举例介绍,因为方法实在是太多了;还有一个知识点就是分页插件的使用也没有在本文中介绍,原因也是提供的方法很多,不方便介绍,自己认为最好的办法就是找一个小项目,在实际开发中慢慢熟练使用这些框架给的方法!
以上是关于MyBatis是什么?使用它作为持久层框架有什么优点?的主要内容,如果未能解决你的问题,请参考以下文章