Hadoop完全分布式部署
Posted 小黄人的哆啦梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop完全分布式部署相关的知识,希望对你有一定的参考价值。
Hadoop完全分布式配置
- Hadoop完全分布式部署
Hadoop完全分布式部署
一、需要的软件
1、虚拟机管理软件:VMware15
2、系统:CentOS 7
3、ssh软件:Xshell 7
4、hadoop版本:2.7.7
5、Jdk版本:jdk8

二、安装配置Hadoop
注意:使用超级管理员root登录。
1、 配置静态网络,关闭防火墙,设置hosts映射关系
1.1使用ping 命令检测网络是否连通
ping www.baidu.com
使用ctrl+c来停止命令
如果网络没有打开,打开网络:
service network restart
1.2 修改ip地址,设置为静态网络。
vi /etc/sysconfig/network-scripts/ifcfg-ens33
选择编辑ifcfg-ens33这个文件修改ip地址信息。
1) 把BOOTPROTO="hdcp" 改为BOOTPROTO=”static”静态网络ip
2) 设置ONBOOT="yes"
3) 添加master IP地址为:IPADDR=192.168.100.10
4) 添加子网掩码:NETMASK=255.255.255.0
5) 添加网关: GATEWAY=192.168.100.2
6) DNS1=192.168.100.1
7) 重启网络:systemctl restart network
8) 测试网络有没有连通:ping www.baidu.com

1.3 关闭防火墙
#关闭防火墙
systemctl stop firewalld
#禁用防火墙
systemctl disable firewalld
#查看防火墙状态
systemctl status firewalld
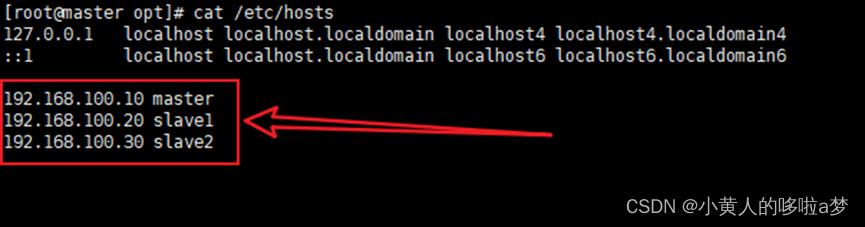
1.4 设置hosts映射关系
备注:这里是把三个Linux的ip地址保存到三个虚拟机去,相当于我们自己在手机里面存别人的电话号码 一样的道理,这样相互之间就知道对应ip地址的机器是哪一台。所以这个操作也是要在三台虚拟机都要 进行的。给ip地址起名字,几个机器需要互相连通,这样在连接几台机器的时候只需要使用机器名就行,不需要使用ip地址。
1.4.1 编辑hosts文件:
vi /etc/hosts
1.4.2 进入编辑模式 i,在最后一行添加
192.168.100.10 master
192.168.100.20 slave1
192.168.100.30 slave2
此时关机,克隆出两台机器,分别为 slave1 、 slave2
2. 设置机器主机名和网络,以及测试hosts映射是否成功。
2.1 设置slave1 和slave2 的网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33
slave1 的网络为 192.168.100.20/24
slave2 的网络为 192.168.100.30/24
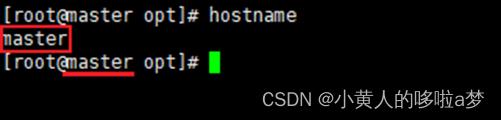
2.2 设置master、slave1 和slave2 的主机名
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
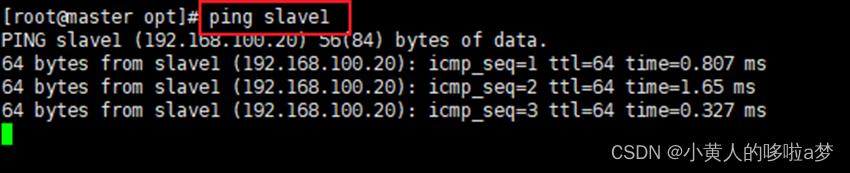
2.3 使用ping命令,看是否能够进行相互的连通。
在master里面连通slave1和slave2。 在slave1里面连通master和slave2。
在slave2里面连通master和slave1。
3、 配置SSH免密登录及时间同步
3.1 在各个机器(master、slave1、slave2)家目录执行
ssh-keygen -t rsa
然后一直回车确认
3.2 ls -all :查看所有文件和文件夹,
会在/root/.ssh产生id_rsa和id_rsa.pub文件
查看.ssh目录可以看到id_rsa(私钥), id_rsa.pub (公钥)两个文件
如何能在master中对s1和s2进行免密登录?
需要把master的公钥放到s1和s2的authorized_keys文件里
(执行以下步骤即可)
3.3 在master、slave1、slave2中分别执行
(期间需要输入yes ,和对应机器的密码,看提示自行决定)
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id master
3.4 设置时间同步(按需设置)
crontab -e
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
4、 解压jdk包和Hadoop包并安装jdk
在/opt目录下创建
/module(存放解压或安装好的软件),
/software(tar包等软件包),
目录存放文件

4.1 解压压缩文件:解压hadoop文件和jdk文件,
输入命令时可以用tab键补全
tar -zxvf /opt/software/hadoop-2.7.7.tar.gz –C /opt/module/hadoop
tar -zxvf /opt/software/jdk-8u171-linux-x64.tar.gz –C /opt/module/jdk
4.2 创建一个专门用于配置环境变量的文件
vi /etc/profile.d/bigdata_env.sh

4.3 在bigdata_env.sh文件中设置java的环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_162
export PATH=$JAVE_HOME/bin:$PATH
4.4 使环境变量生效
source /etc/profile
#可以查看java的版本
java –version

到此,master中的java配置已经结束了.
4.5 在slave1和slave2中不用再去安装,直接分发就好了
scp -r /opt/module/jdk1.8.0_162/ slave1:/opt/module
scp -r /opt/module/jdk1.8.0_162/ slave2:/opt/module
4.6 配置s1和s2的环境变量,参考步骤(3)(4)。
5、 解压Hadoop及配置环境变量
5.1 解压Hadoop
tar -zxvf /opt/sofrware/hadoop-2.7.7.tar.gz -C /opt/module
5.2 配置环境变量
系统环境配置在master、s1和s2相同,以master 为例。
vi /etc/profile.d/bigdata_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使变量生效
source /etc/profile
6、 配置Hadoop相关的自定义配置
切换到/opt/module/hadoop-2.7.7/etc/hadoop目录下
cd /opt/module/hadoop-2.7.7/etc/Hadoop
6.1 vi core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
6.2 vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop-2.7.7/tmp/dfs/data</value>
</property>
6.3 vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
6.4 vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_162
6.5 vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master </value>
</property>
6.6 vim workers(slaves)
master
slave1
slave2
7、 分发Hadoop安装包
scp -r /opt/module/hadoop-2.7.7 slave1:/opt/module/
scp -r /opt/module/hadoop-2.7.7 slave2:/opt/module/
8、 Hdfs格式化
hdfs namenode -format
9、 Hadoop启动
start-all.sh
使用jps查看java进程会看到 如下进程
在master上可看到
NameNode
SecondaryNameNode
ResourceManager
NodeManager
DataNode
在slave1上可看到
NodeManager
DataNode
在slave2上可看到
NodeManager
DataNode
以上是关于Hadoop完全分布式部署的主要内容,如果未能解决你的问题,请参考以下文章