PanGu-Coder:函数级的代码生成模型
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PanGu-Coder:函数级的代码生成模型相关的知识,希望对你有一定的参考价值。
摘要:华为诺亚方舟实验室语音语义实验室联合华为云PaaS技术创新实验室基于PanGu-Alpha研制出了当前业界最新的模型PanGu-Coder
本文分享自华为云社区《PanGu-Coder 函数级的代码生成模型》,作者:DevAI 。
1. 概述
基于预训练模型的生成技术在自然语言处理领域获得了极大的成功。近年来,包括OpenAI GPT-3、华为PanGu-Alpha等在内的文本生成模型展示出了惊人的创造力,生成能力远超以往的技术,逐渐成为序列生成的一种基本范式,并显示出了巨大的商业潜力。在这种范式的引导下,研究人员开始尝试将语言生成模型引入到软件工程领域,并在代码生成与补全等任务中取得了突破性进展。其中,最广为人知的当属微软发布的AI辅助编程工具Copilot。
近日,华为诺亚方舟实验室语音语义实验室联合华为云PaaS技术创新实验室基于PanGu-Alpha研制出了当前业界最新的模型PanGu-Coder [1]。与业界标杆Copilot 背后的Codex[2]以及谷歌的AlphaCode等[3][4]相比,PanGu-Coder在代码生成的一次通过率(PASS@1)指标上不仅大幅超越同等规模的模型,甚至超越了参数量规模更大的模型。在支持的语言上,除英文外,PanGu-Coder在中文上同样有出色的表现,在未来也可以更好地服务使用中文的开发者。在内测中还发现:PanGu-Coder不但熟悉常见算法,还能熟练地使用各种API,甚至可以求解高等数学问题。相信经过不断打磨,PanGu-Coder将逐步成为编程人员的聪明助手。
2. 训练数据
PanGu-Coder使用了380GB的原始Python文件,通过MD5校验,限制文件大小、代码长度以及AST解析等方式对原始文件进行了清洗、去重等工作,最终得到了147GB的数据用作模型训练阶段的输入。
为了提升函数级代码生成的效果,每个Python文件中的代码语料均按照函数级的方式进行了重新组织。例如:如果某个函数的定义之后紧接着对于函数的自然语言注释,该注释将被放置到函数定义之前,形成自然语言到代码的配对数据,并用以构建训练数据集。
3. 训练方法
PanGu-Coder将训练分为了两个阶段:第一阶段使用了全量的代码数据进行训练;第二阶段选择了更符合目标任务的自然语言和代码对作为训练数据对模型进行调优。
3.1 模型架构
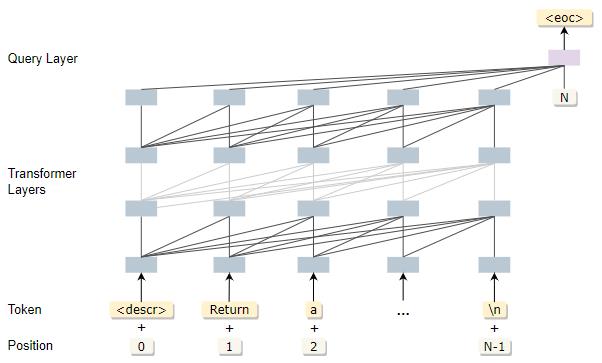
图1 PanGu-Coder的模型结构
由于PanGu-Alpha所采用的的自回归Transformer架构所具备强大的文本生成能力,在PanGu-Coder的训练中也沿用了此模型架构用于代码生成任务,其架构如图1所示。同时,PanGu-Coder也沿用了PanGu-Alpha的中英文多语词表,从而同时具备支持中英文输入的能力。
3.2 训练方法
受课程学习(Currilum Learning)启发,PanGu-Coder采用了两阶段训练的方式进行训练:1)在原始语料上,采用传统的自回归语言建模(Causal language modeling,CLM)进行训练;2)在经过筛选的语料上,仅对<自然语言,代码>平行句对样本,采用创新的代码自回归语言建模(Code-CLM)进行训练。

图2 PanGu-Coder的两阶段样本构成方式
PanGu-Coder的两阶段样本示例如图2所示。图2(左)为第一阶段训练样本,图2(右)为第二阶段样本。在第一阶段的训练中,PanGu-Coder具备了自然语言和代码交错的语言模型的能力,而第二阶段样本则帮助PanGu-Coder在通过自然语言进行代码生成的任务上得到了更好的适配。
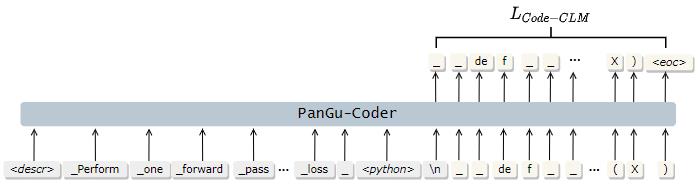
图3 PanGu- Coder: Code-CLM 损失函数
在第二阶段的训练中,PanGu-Coder采用了专门为代码生成而设计的Code-CLM作为其损失函数。如图3所示。在训练过程中,Code-CLM仅保留代码部分的Loss计算结果,同时忽略了自然语言部分的Loss。Code-CLM损失函数的采用,让PanGu-Coder更专注于学习生成代码序列的同时减少了自然语言序列带来的干扰,使得PanGu-Coder的第二阶段训练数据与训练目标都更接近代码生成任务的真实场景。
4. 实验结果
4.1 模型生成的通过率
模型的一次生成通过率(PASS@1)是代码语言生成模型最重要的能力衡量指标。PanGu-Coder采用了OpenAI发布的HumanEval以及谷歌发布的MBPP两个函数级代码生成任务的数据集作为评测目标。表1给出了HumanEval中一个非常简单的例子。PanGu-Coder生成的代码需要通过单元测试(Unit Tests)才被认为生成正确。

表1 HumanEval 示例
在HumanEval数据集上,与业界标杆Codex(OpenAI)以及包括AlphaCode(Google Deep Mind)、CodeGen(Saleforce)、 INCoder(Meta)等模型相比,PanGu-Coder在3亿和26亿模型上的一次通过率PASS@1均达到最优。值得一提的是,3亿参数的PanGu-Coder模型(PASS@1=17.07%)超越了Codex (PASS@1=16.22%)接近7亿参数的模型结果,基本持平了谷歌10亿的模型(表2)。在MBPP数据集上, 26亿参数的模型超越了META INCoder 接近70亿参数的模型效果(表3)。另外,在训练的充分程度上,PanGu-Coder是所有模型中所用数据量以及计算量最小(train tokens)的模型。这一结果充分说明了PanGu-Coder数据集构建策略和分阶段训练设计的合理性,并展示了采用这种方式能够在函数级代码生成这一最重要场景上达到业界最优。
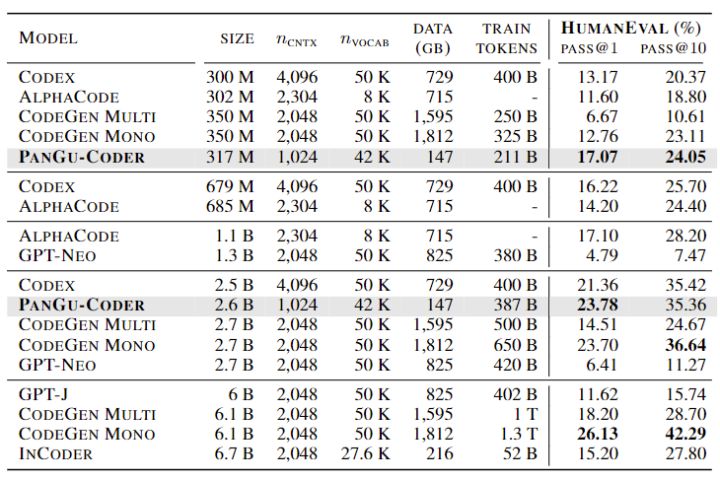
表2 PanGu-Coder在HumanEval上的一次通过率以及十次通过率
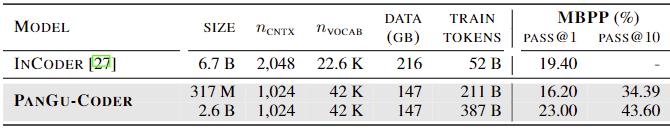
表3 PanGu-Coder在MBPP上的一次通过率以及十次通过率
为进一步提升模型函数级代码生成的能力,PanGu-Coder收集了包括CodeContest、CodeSearchNet、APPS在内的业界已公开的大规模函数级数据集对模型进行微调(Fine-tune),得到了PanGu-Coder-FT。实验结果表明,微调模型在MBPP以及HumanEval上的表现到了明显提升(表4)。

表4 PanGu-Coder: 3亿模型Fine-tune结果
实际编码过程中,通常在实现一个函数之前,会预先设计若干测试用例来测试函数实现结果。在HumanEval 164个函数描述中,有130个问题描述中包含了预设的测试用例。为验证基于测试用例的代码生成的有效性,PanGu-Coder在进行多次生成(200次)的情况下使用这些测试用例对生成的代码进行了过滤,并统计了过滤后代码的通过率。从最终结果可以看出,利用测试用例对生成的代码进行过滤可以极大地提升通过率,其中3亿的模型可以达到41.52%。

表5 PanGu-Coder: 3亿模型测试用例过滤结果
4.2 工具内测
PanGu-Coder模型已集成到了华为云的代码开发辅助工具中,可以在IDE中使用自然语言描述生成函数级的Python代码,或者根据上下文进行补全。
如下是内测过程中产生的几个实际的例子。
(1)常见的数据结构算法
Input: 使用冒泡排序的方法对数组进行排序。
OutPut:

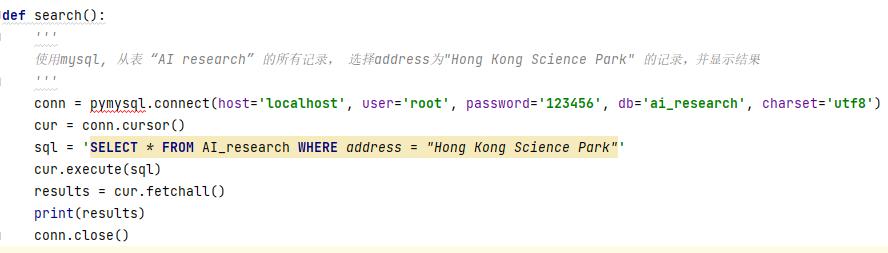
(2)SQL查询功能
Input: 使用mysql, 从表 “AI research” 的所有记录, 选择address为"Hong Kong Science Park" 的记录,并显示结果.
OutPut:
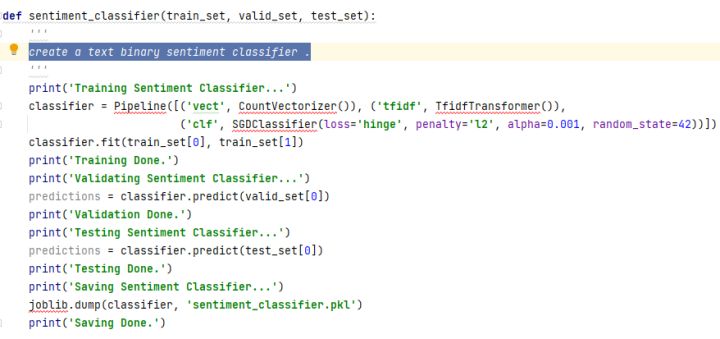
(3)使用机器学习工具创建文本分类器
Input: create a text binary sentiment classifier .
Output:
(4)高等数学题1: 求微分
Input: Using sympy find the derivative of the function using the definition of the derivative.f(x)= (x**2-1)/(2*x-3).
Output:

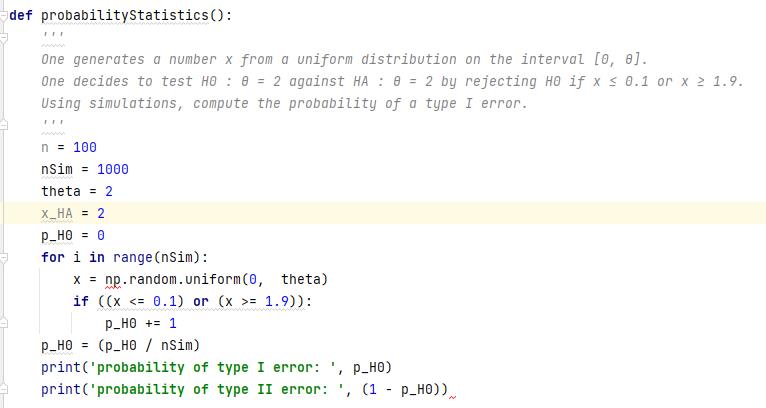
(5)高等数学题2,求概率分布
Input: One generates a number x from a uniform distribution on the interval [0, θ].One decides to test H0 : θ = 2 against HA : θ = 2 by rejecting H0 if x ≤ 0.1 or x ≥ 1.9.Using simulations, compute the probability of a type I error.
Output:
5. 展望
PanGu-Coder是基于华为的预训练语言模型PanGu-Alpha演进而来的代码生成模型,在模型训练的高效性以及函数级生成与补全性能上均达到业界领先的水平。目前PanGu-Coder已经集成在华为云的代码开发辅助工具中进行内测。同时PanGu-Coder也在不断的迭代与演进,以支持更多的编程语言、提供更好、更快的生成能力。
文章来自 PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:PaaS技术创新Lab-华为云
参考文献:
[1] Christopoulou, Fenia, et al. "PanGu-Coder: Program Synthesis with Function-Level Language Modeling." arXiv preprint arXiv:2207.11280 (2022).
[2] Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
[3] Li, Yujia, et al. "Competition-level code generation with AlphaCode." arXiv preprint arXiv:2203.07814 (2022).
[4] Nijkamp, Erik, et al. "A conversational paradigm for program synthesis." arXiv preprint arXiv:2203.13474 (2022).
以上是关于PanGu-Coder:函数级的代码生成模型的主要内容,如果未能解决你的问题,请参考以下文章
优云软件又双叒通过CMMI ML3评估 , 研发和质量管理水平创新高