分布式学习和联邦学习简介
Posted deephub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式学习和联邦学习简介相关的知识,希望对你有一定的参考价值。
在这篇文章中,我们将讨论分布式学习和联邦学习的主要原理以及它们是如何工作的。首先,我们从一个简单的单机示例开始,然后将其发展为分布式随机梯度下降(D-SGD),最后是联邦学习(FL)。
集中学习(单机)
一个最简单的例子,我们想学习人的身高和体重之间的线性关系,并且我们拥有100人的体重和身高数据,想训练一种线性模型,该模型使用身高预测人们的体重,线性回归W = [a,b]如下:
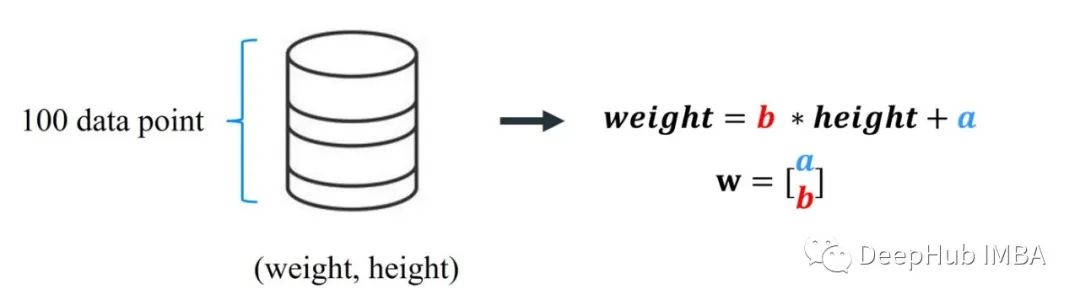
我们怎么找到w?为了求w,使用梯度下降法(GD),从一个随机的w开始,然后通过沿误差的相反方向在100个数据点上最小化模型的误差。
设置A = 0和B = 2,并为每个数据点计算我们的模型,如下所示:

上面的方程肯定是不成立的,因为2 * 1.70 + 0不等于72。我们的目标是找到一个a和b使这个等式成立。所以需要计算该模型对于所有100人的数据点的误差:

目标是找到使所有数据点的误差为零的模型,我们假定负误差与正误差相等。因此将总误差定义为所有数据点平方误差的平均值,如下所示:
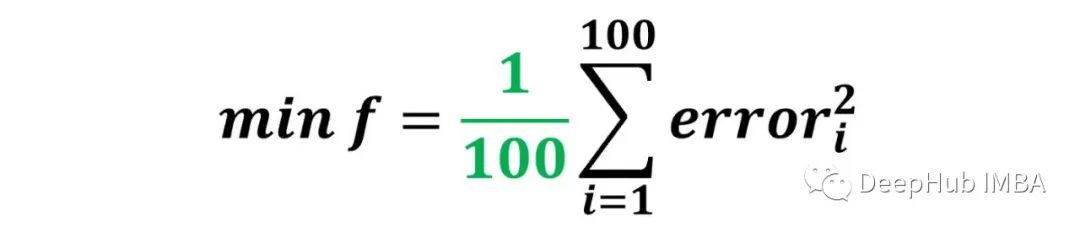
强调一下这个总误差或者说损失函数的关键点是对所有数据点的平均值,也就是说每个数据点对总误差的贡献是相等的。损失函数是通过平均所有数据点的误差来计算的,每个数据点对损失函数的贡献是相等的。
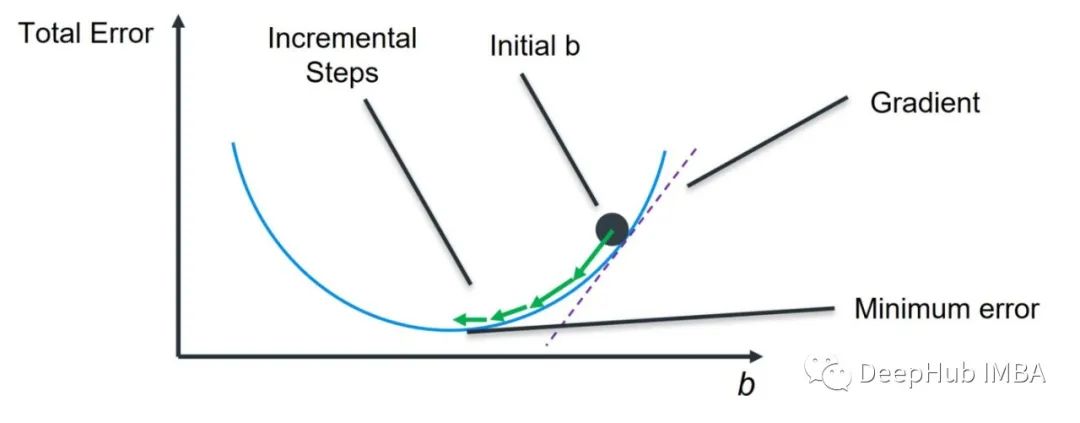
为了用梯度下降法求出a和b的最优值,需要计算b在初始b点的梯度,并按如下方式更新值:
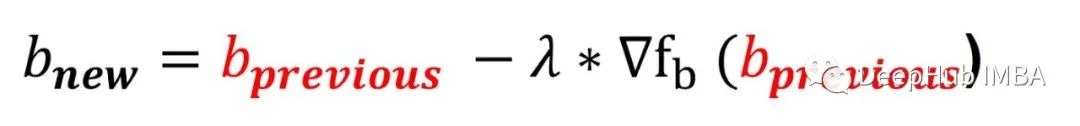
Lambda是学习率,继续看下图
要计算F的梯度,首先需要以完整的形式编写F。
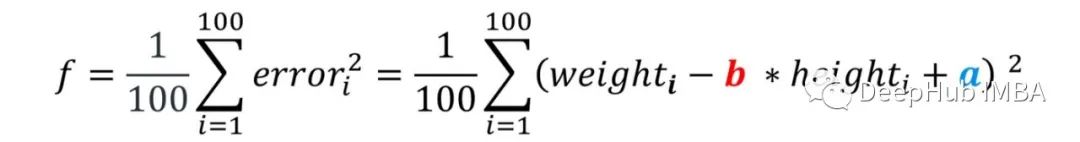
现在,准备计算F相对于B的梯度:

到梯度是每个数据点错误梯度的平均值!使用上面定义的符号,我们可以按以下方式完成梯度下降更新规则:
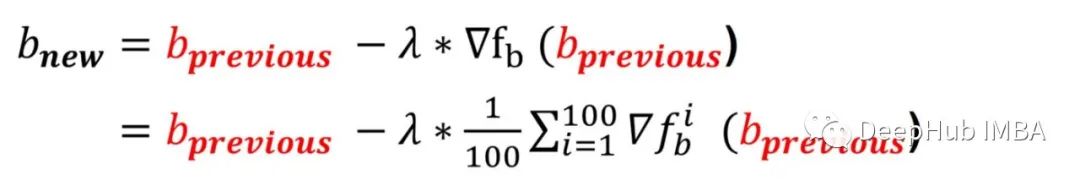
通过平均每个数据点的误差来计算损失函数的真实梯度,然后将新B替换为上一个B,直到我们的总错误足够小。这是一个迭代过程,通过多次宠物可以找到A和B的最佳价值。
随机梯度下降(SGD)
我们通过在100个数据点的所有梯度上平均来计算F的梯度。如果我们仅使用20个数据点进行估计,该怎么办?

这被为小批量的随机梯度下降,仅利用数据子集来计算梯度。
分布式随机梯度下降(D-SGD)
让我们看一下从另一个角度计算的梯度。
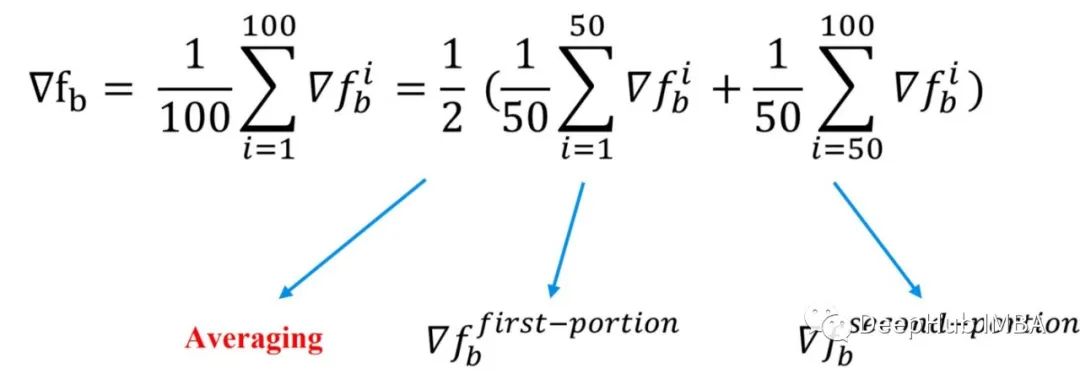
如果我们按照上面的公式重写梯度并将其分为2部分求和时,每个和式都有其意义。第一部分实际上是前50个点数据的平均梯度,第二部分是数据集后50个点数据的平均梯度。
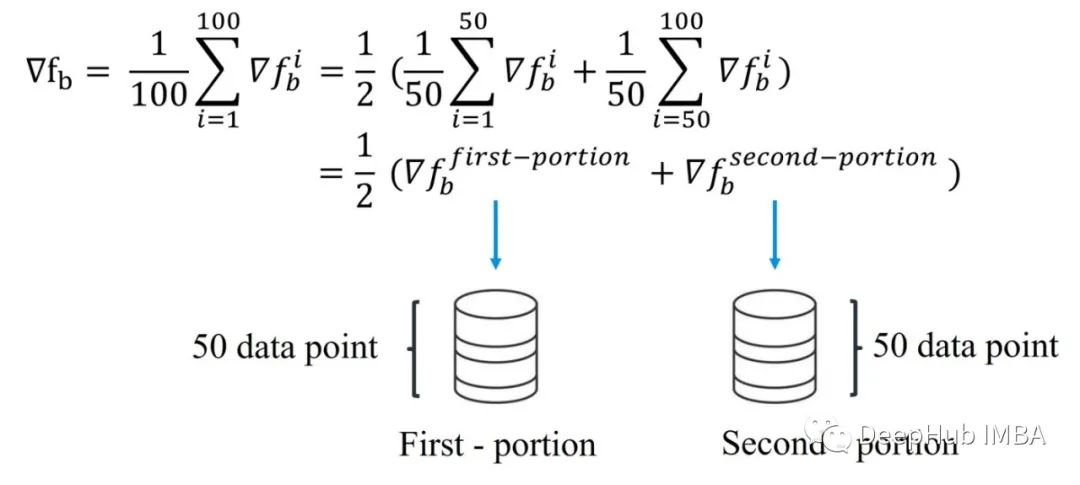
这意味着我们不需要将所有的100个数据点放在一个地方(同一台服务器)!我们可以将数据分成两部分然后分别计算每个部分的梯度,然后对这两个梯度求平均值,来计算整个数据的梯度。这就是D-SGD的主要思想。
现在,我们有两个客户机的分布式SGD。
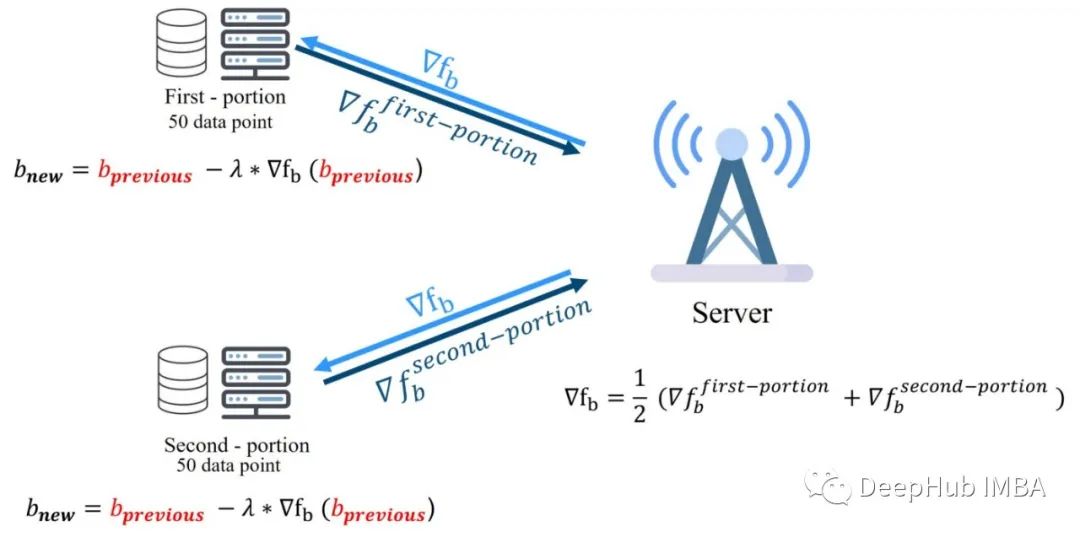
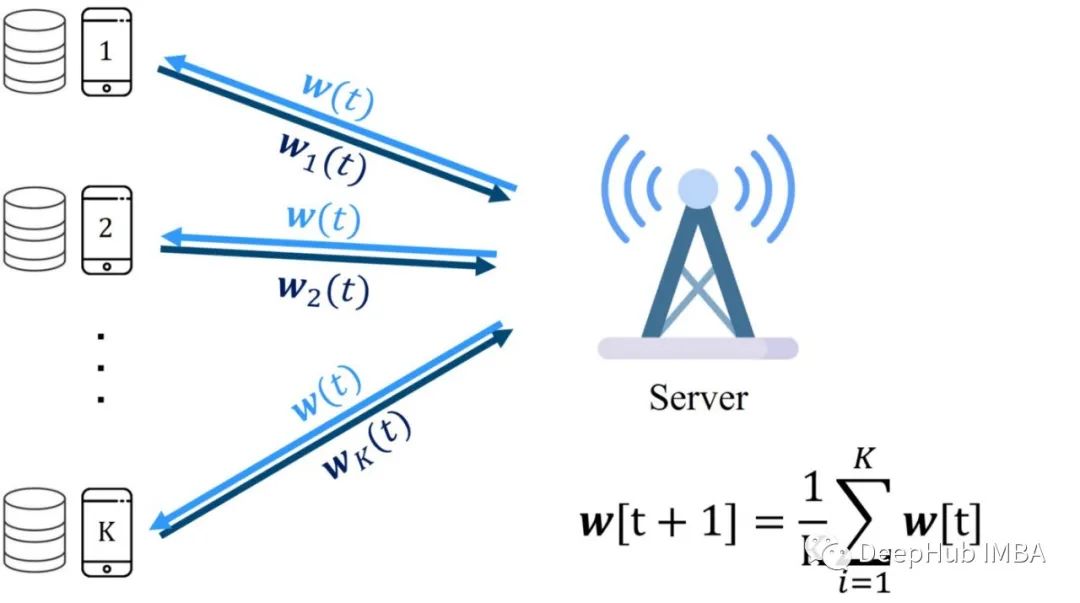
如上所示,在D-SGD中两个客户端都从相同的b点开始,然后各自用50个数据点计算每个客户端的梯度。然后将局部梯度发送到充当协调器的服务器上。该协调器会对两个梯度求平均值,然后计算整个数据的梯度或叫全局梯度。服务器返回这个全局梯度给两个客户端,客户端使用这个全局梯度来更新他们的b值或他们的模型。b的新值对每个客户端都是一样的,因为全局梯度是一样的,计算出来的新b也应该是一样的。这个过程如下图所示。
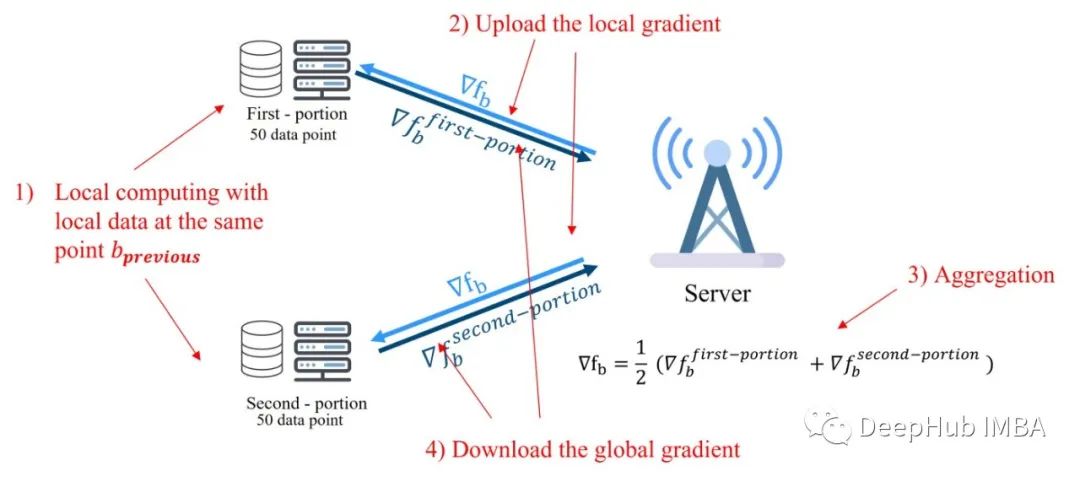
从1(计算局部梯度)到4(下载全局梯度)的步骤不断迭代,直到达到预定义的误差水平。在这个示例中,我们只使用了两个客户端,但是它可以扩展到许多客户端。
需要说明的是,我们是用局部梯度来估计全局梯度!
联邦学习(FL)
如果我们利用每个客户端的局部梯度来计算每个局部模型,或者在我们的例子中,b如下所示,会发生什么?

在这个场景中,会以每个客户端不同的b值结束,如上图所示,我们称之为本地模型。

如果我们这样做,每个局部模型都会进行参数b的更新,这意味着不需要发送局部梯度。而是将局部模型的参数或者中间结果发送到服务器进行平均,然后得到全局模型。这是联邦学习的主要思想。
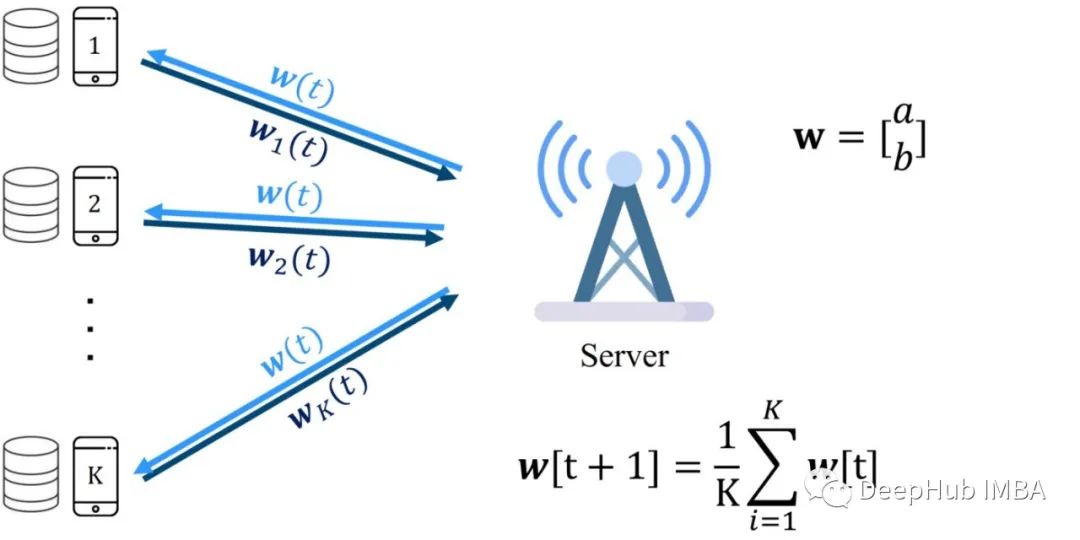
FL系统通过重复以下过程来优化全局机器学习(ML)模型:
i)每个客户端设备对其数据进行本地计算以最小化全局模型w。
ii)然后将其本地更新的模型发送到FL服务器进行聚合;
iii) FL服务器对接收到的局部模型进行聚合,生成改进的全局模型;
Iv),服务器将更新后的全局模型发送给客户端设备,客户端设备使用新的全局模型进行下一次的计算。
这个过程会不断迭代,直到模型达到预定义的精度水平。这个过程如下图所示。
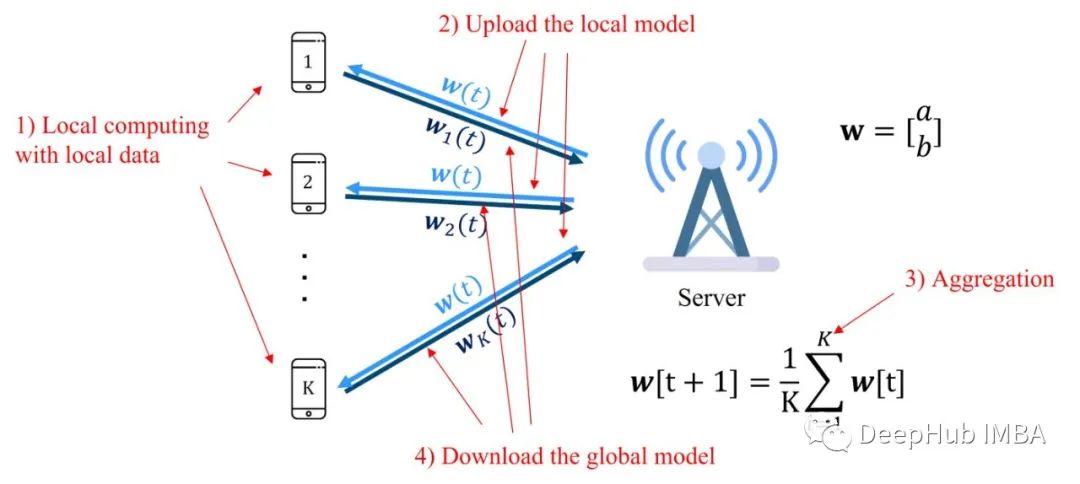
联邦学习vs分布式SGD
在FL中使用模型权重,但在D-SGD中只使用梯度。在我们讨论的例子中,在发送更新之前只进行了梯度下降的一个局部步骤。在这种情况下,FL相当于分布式sgd。如果要进行多个步骤,需要使用FL发送模型权重。一般形式的FL的收敛分析(多个局部步骤)不同于我们所做的分布式- sgd分析。但是原理都是差不多的。
我们在本文中描述的D-SGD算法(中心化D-SGD)和FL算法(FEDAVG)只是D-SGD和FL的众多算法之一。
为什么联邦学习是有用的?
我们需要FL的主要原因是因为隐私。我们不希望将私人原始数据泄露给任何用于训练机器学习模型的服务器。所以需要一种不需要从客户端设备发送原始数据就可以训练机器学习算法,这就是联邦学习的作用。例如,谷歌利用FL来改进它的键盘应用程序(Gboard)。FL在不同的应用中有用还有其他原因。例如FL使系统能够利用移动设备等本地计算,以减轻服务器的压力。
联邦学习的挑战
我们可以将FL面临的挑战分为两类。第一类是在运行FL流程之前的数据准备流程流程。这个的关键问题是,不能访问原始数据,甚至不能访问FL系统的设备。我们需要知道如何在不访问设备的情况下设计模型或评估数据?
第二类的挑战是运行FL流程时出现的问题。需要考虑到参与FL系统的客户端资源是受限的,他们在发送或处理ML模型方面的能力有限,例如在本文的例子中,我们的参数只有b,传输完整的参数是可行的,但是如果模型很大,例如BERT,那么我们不可能在客户端和服务器之间传输几个G的数据,这是不可能的。
总结
联邦学习是一个建立在分布式学习框架上的新兴主题,它试图解决现实应用程序中训练ML模型的隐私问题。在本文中,我们只触及了这些系统的表面,如果你想深入了解这方面的知识可以自己搜素相关的文章或者等待我们后续的相关文章。
https://avoid.overfit.cn/post/ea6d50f42f904c97b4fa299be0c389b5
作者:Mahdi Beitollahi
以上是关于分布式学习和联邦学习简介的主要内容,如果未能解决你的问题,请参考以下文章