数据库表数据归档后,统计的功能怎么办
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库表数据归档后,统计的功能怎么办相关的知识,希望对你有一定的参考价值。
pt-archiver原理解析作为mysql DBA,可以说应该没有不知道pt-archiver了,作为pt-toolkit套件中的重要成员,往往能够轻松帮助DBA解决数据归档的问题。例如线上一个流水表,业务仅仅只需要存放最近3个月的流水数据,三个月前的数据做归档即可,那么pt-archiver就可以轻松帮你完成这件事情,甚至你可以配置成自动任务,无需人工干预。
作为DBA,我们应该知其然更应该知其所以然,这样我们也能够放心地使用pt工具。相信很多DBA都研究过pt-online-schema-change的原理,那么今天我们深入刨一刨pt-archiver的工作原理。
一、原理观察
土人有土办法,我们直接开启general log来观察pt-archiver是如何完成归档的。
命令
pt-archiver --source h=127.0.0.1,u=xucl,p=xuclxucl,P=3306,D=xucl,t=t1 --dest h=127.0.0.1,P=3306,u=xucl,p=xuclxucl,D=xucl_archive,t=t1 --progress 5000 \
--statistics --charset=utf8mb4 --limit=10000 --txn-size 1000 --sleep 30
常用选项
--analyze
指定工具完成数据归档后对表执行'ANALYZE TABLE'操作。指定方法如'--analyze=ds',s代表源端表,d代表目标端表,也可以单独指定。
--ask-pass
命令行提示密码输入,保护密码安全,前提需安装模块perl-TermReadKey。
--buffer
指定缓冲区数据刷新到选项'--file'指定的文件并且在提交时刷新。
只有当事务提交时禁用自动刷新到'--file'指定的文件和刷新文件到磁盘,这意味着文件是被操作系统块进行刷新,因此在事务进行提交之前有一些数据隐式刷新到磁盘。默认是每一行操作后进行文件刷新到磁盘。
--bulk-delete
指定单个语句删除chunk的方式来批量删除行,会隐式执行选项'--commit-each'。
使用单个DELETE语句删除每个chunk对应的表行,通常的做法是通过主键进行逐行的删除,批量删除在速度上会有很大的提升,但如果有复杂的'WHERE'条件就可能会更慢。
--[no]bulk-delete-limit
默认值:yes
指定添加选项'--bulk-delete'和'--limit'到进行归档的语句中。
--bulk-insert
使用LOAD DATA LOCAL INFILE的方法,通过批量插入chunk的方式来插入行(隐式指定选项'--bulk-delete'和'--commit-each')
而不是通过逐行单独插入的方式进行,它比单行执行INSERT语句插入的速度要快。通过隐式创建临时表来存储需要批量插入的行(chunk),而不是直接进行批量插入操作,当临时表中完成每个chunk之后再进行统一数据加载。为了保证数据的安全性,该选项会强制使用选项'--bulk-delete',这样能够有效保证删除是在插入完全成功之后进行的。
--channel
指定当主从复制环境是多源复制时需要进行归档哪个主库的数据,适用于多源复制中多个主库对应一个从库的情形。
--charset,-A
指定连接字符集。
--[no]check-charset
默认值:yes
指定检查确保数据库连接时字符集和表字符集相同。
--[no]check-columns
默认值:yes
指定检查确保选项'--source'指定的源端表和'--dest'指定的目标表具有相同的字段。
不检查字段在表的排序和字段类型,只检查字段是否在源端表和目标表当中都存在,如果有不相同的字段差异,则工具报错退出。如果需要禁用该检查,则指定'--no-check-columns'。
--check-slave-lag
指定主从复制延迟大于选项'--max-lag'指定的值之后暂停归档操作。默认情况下,工具会检查所有的从库,但该选项只作用于指定的从库(通过DSN连接方式)。
--check-interval
默认值:1s
如果同时指定了选项'--check-slave-lag',则该选项指定的时间为工具发现主从复制延迟时暂停的时间。每进行操作100行时进行一次检查。
--columns,-c
指定需要归档的表字段,如有多个则用','(逗号)隔开。
--commit-each
指定按每次获取和归档的行数进行提交,该选项会禁用选项'--txn-size'。
在每次获取表数据并进行归档之后,在获取下一次数据和选项'--sleep'指定的休眠时间之前,进行事务提交和刷新选项'--file'指定的文件,通过选项'--limit'控制事务的大小。
--host,-h
指定连接的数据库IP地址。
--port,-P
指定连接的数据库Port端口。
--user,-u
指定连接的数据库用户。
--password,-p
指定连接的数据库用户密码。
--socket,-S
指定使用SOCKET文件连接。
--databases,-d
指定连接的数据库
--source
指定需要进行归档操作的表,该选项是必须指定的选项,使用DSN方式表示。
--dest
指定要归档到的目标端表,使用DSN方式表示。
如果该选项没有指定的话,则默认与选项'--source'指定源端表为相同表。
--where
指定通过WHERE条件语句指定需要归档的数据,该选项是必须指定的选项。不需要加上'WHERE'关键字,如果确实不需要WHERE条件进行限制,则指定'--where 1=1'。
--file
指定表数据需要归档到的文件。使用类似MySQL DATE_FORMAT()格式化命名方式。
文件内容与MySQL中SELECT INTO OUTFILE语句使用相同的格式,文件命名选项如下所示:
%Y:年,4位数(Year, numeric, four digits)
%m:月,2位数(Month, numeric (01..12))
%d:日,2位数(Day of the month, numeric (01..31))
%H:小时(Hour (00..23))
%i:分钟(Minutes, numeric (00..59))
%s:秒(Seconds (00..59))
%D:数据库名(Database name)
%t:表名(Table name)
例如:--file '/var/log/archive/%Y-%m-%d-%D.%t'
--output-format
指定选项'--file'文件内容输出的格式。
默认不指定该选项是以制表符进行字段的分隔符,如果指定该选项,则使用','(逗号)作为字段分隔符,使用'"'(双引号)将字段括起。用法示例:'--output-format=dump'。
--for-update
指定为每次归档执行的SELECT语句添加FOR UPDATE子句。--share-lock
指定为每次归档执行的SELECT语句添加LOCK IN SHARE MODE子句。
--header
指定在文件中第一行写入字段名称作为标题。
--ignore
指定为INSERT语句添加IGNORE选项。
--limit
默认值:1
指定每条语句获取表和归档表的行数。
--local
指定不将OPTIMIZE和ANALYZE语句写入binlog。
--max-lag
默认值:1s
指定允许主从复制延迟时长的最大值,单位秒。如果在每次获取行数据之后主从延迟超过指定的值,则归档操作将暂停执行,暂停休眠时间为选项'--check-interval'指定的值。待休眠时间结束之后再次检查主从延迟时长,检查方法是通过从库查询的'Seconds_Behind_Master'值来确定。如果主从复制延迟一直大于该参数指定值或者从库停止复制,则操作将一直等待直到从库重新启动并且延迟小于该参数指定值。
--no-delete
指定不删除已被归档的表数据。
--optimize
指定工具完成数据归档后对表执行'OPTIMIZE TABLE'操作。指定方法如'--analyze=ds',s代表源端表,d代表目标端表,也可以单独指定。
--primary-key-only
指定只归档主键字段,是选项'--columns=主键'的简写。
如果工具归档的操作是进行DELETE清除时最有效,因为只需读取主键一个字段而无需读取行所有字段。
--progress
指定每多少行打印进度信息,打印当前时间,已用时间以及多少行进行归档。
--purge
指定执行的清除操作而不是归档操作。允许忽略选项'--dest'和'--file'进行操作,如果只是清除操作可以结合选项'--primary-key-only'会更高效。
--quiet,-q
指定工具静默执行,不输出任何的执行信息。
--replace
指定写入选项'--dest'指定目标端表时改写INSERT语句为REPLACE语句。
--retries
默认值:1
指定归档操作遇到死锁或超时的重试次数。当重试次数超过该选项指定的值时,工具将报错退出。
--run-time
指定工具归档操作在退出之前需要运行的时间。允许的时间后缀名为s=秒,m=分,h=小时,d=天,如果没指定,默认为s。
--[no]safe-auto-increment
默认值:yes
指定不使用自增列(AUTO_INCREMENT)最大值对应的行进行归档。
该选项在进行归档清除时会额外添加一条WHERE子句以防止工具删除单列升序字段具有的具有AUTO_INCREMENT属性最大值的数据行,为了在数据库重启之后还能使用到AUTO_INCREMENT对应的值,但这会引起无法归档或清除字段对应最大值的行。
--set-vars
默认:
wait_timeout=10000
innodb_lock_wait_timeout=1
lock_wait_timeout=60
工具归档时指定参数值,如有多个用','(逗号)分隔。如'--set-vars=wait_timeout=5000'。
--skip-foreign-key-checks
指定使用语句SET FOREIGN_KEY_CHECKS = 0禁用外键检查。
--sleep
指定工具在通过SELECT语句获取归档数据需要休眠的时间,默认值是不进行休眠。在休眠之前事务并不会提交,并且选项'--file'指定的文件不会被刷新。如果指定选项'--commit-each',则在休眠之前会进行事务提交和文件刷新。
--statistics
指定工具收集并打印操作的时间统计信息。
统计信息示例如下:
'
Started at 2008-07-18T07:18:53, ended at 2008-07-18T07:18:53
Source: D=db,t=table
SELECT 4
INSERT 4
DELETE 4
Action Count Time Pct
commit 10 0.1079 88.27
select 5 0.0047 3.87
deleting 4 0.0028 2.29
inserting 4 0.0028 2.28
other 0 0.0040 3.29
--txn-size
默认:1
指定每个事务处理的行数。如果是0则禁用事务功能。
--version
显示工具的版本并退出。
--[no]version-check
默认值:yes
检查Percona Toolkit、MySQL和其他程序的最新版本。
--why-quit
指定工具打印当非因完成归档行数退出的原因。
在执行一个自动归档任务时该选项与选项'--run-time'一起使用非常方便,这样可以确定归档任务是否在指定的时间内完成。如果同时指定了选项'--statistics',则会打印所有退出的原因。
二、原理解析
根据general log的输出,我们整理出时序表格如下
三、其他说明
咋一看这个过程貌似也没有什么问题,但是,假如在原表扫描出数据,插入到新表的过程中,旧数据发生了变化怎么办?
带着这个疑问,我们进行了源码的跟踪,我们在pt-archiver的6839行打上了断点
然后我分别在几个session窗口做了如下动作
最后pt-archiver输出如下:
# A software update is available:
TIME ELAPSED COUNT
2020-04-08T09:13:21 0 0
2020-04-08T09:13:21 0 1
Started at 2020-04-08T09:13:21, ended at 2020-04-08T09:13:51
Source: A=utf8mb4,D=xucl,P=3306,h=127.0.0.1,p=...,t=t1,u=xucl
Dest: A=utf8mb4,D=xucl_archive,P=3306,h=127.0.0.1,p=...,t=t1,u=xucl
SELECT 1
INSERT 1
DELETE 1
Action Count Time Pct
sleep 1 30.0002 99.89
inserting 1 0.0213 0.07
commit 2 0.0080 0.03
select 2 0.0017 0.01
deleting 1 0.0005 0.00
other 0 0.0008 0.00
很明显,id=3这条记录并没有进行归档(我们这里是改了条件列,实际生产中可能是更改了其他列,造成归档数据不准确)
那么如何来解决这种情况的发生呢?
显然,数据库在数据库中可以通过加排它锁来防止其他程序修改对应的数据,pt-archiver其实早就已经帮我们考虑到了这样的情况,pt-archiver提供了两种选择
--for-update:Adds the FOR UPDATE modifier to SELECT statements
--share-lock:Adds the LOCK IN SHARE MODE modifier to SELECT statements
四、总结
pt-archiver作为归档工具无疑是MySQL DBA日常运维的大利器之一,在使用过程中在知道如何使用的基础上也能够知晓其原理
归档过程中最好能对归档记录进行加锁操作,以免造成归档数据不准确
在主从环境中,归档过程最好控制速度,以免造成主从延迟
尽量控制好chunk的大小,不要过大,造成大事务 参考技术A 在每次获取表数据并进行归档之后,在获取下一次数据和选项'--sleep'指定的休眠时间之前,进行事务提交和刷新选项'--file'指定的文件,通过选项
Excel函数计算:成绩表数据统计
期末考试结束后,老师们要开始紧张的阅卷和成绩统计,如何使用Excel快捷的进行成绩统计呢,可以使用函数和公式计算功能。
选择成绩存放单元格,输入“=83.4+76+85”,其中“=”为函数调用命令,“83.4+76+85”为运算对象及运算符
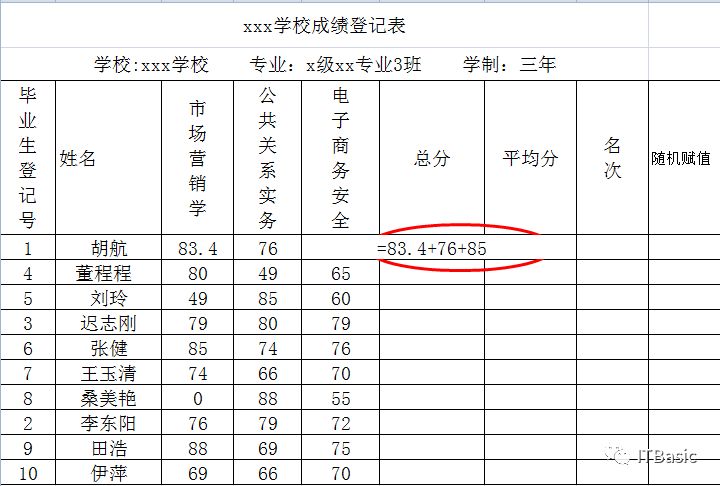
回车后,运算结果呈现在单元格内

我们可以用单元格名称替换实际数值,进行“相对引用”,做“相对引用”后更改某一数值,运算结果自动修正

我们可以用函数代替运算符,将公式编辑为
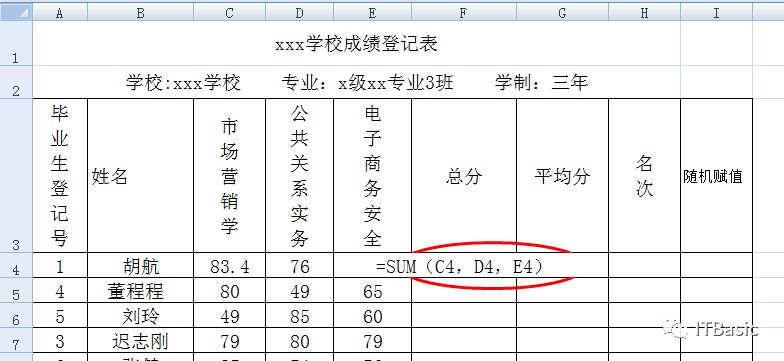
运算对象较多时,可使用“:”表示范围,如“C4,D4,E4”可表示为“C4:E4”,如图所示公式可编辑为:

进行“相对引用”方式进行运算,除了可以自动修正结果,还有利于使用填充柄快捷进行其他相似运算。
鼠标移动到单元格右下角时,光标变为实心十字,此时拖拽即可一键生成其他人的总分。

计算平均分时,可使用“AVERAGE”函数,方法不再赘述。
除手动输入函数公式外,还可使用“函数”选项

选定总分存放单元格后点击“自动求和”函数,系统自动完成函数输入,并自动识别求和对象
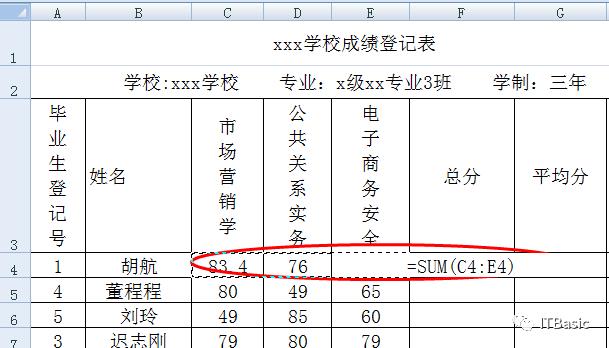
当自动识别的求和对象不恰当时,可通过鼠标左键单击拖选重新确定,虚线框选范围即为求和对象。
你学会了吗
以上是关于数据库表数据归档后,统计的功能怎么办的主要内容,如果未能解决你的问题,请参考以下文章
oracle数据库手动删除数据文件前没有将表空间offline,没有开启归档