如何近似计算回归方程的预测区间?
Posted 麦哲思科技任甲林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何近似计算回归方程的预测区间?相关的知识,希望对你有一定的参考价值。
1 预测区间与置信区间的差别
预测区间估计(prediction interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的一个个别值的估计区间。变量的估计叫预测区间,预测区间反映了单个数值的不确定性;
置信区间估计(confidence interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的平均值的估计区间。参数的估计叫置信区间,置信区间反映了预测均值的不确定性。
例如,有回归方程:
工作量=2*规模+3,
当规模=10, 预测的y值的平均值为23,但是工作量的实际值可以有无数个,如(23.01,23.2,22.1,22.34,…..),这些实际值会在一个区间内浮动,该区间即为预测区间。如果随机抽多个样本,比如样本1(23.01,23.2,22.1),样本2(23.2,22.1,22.34),每个样本的均值会在一个区间内浮动,该区间即为置信区间。
2 预测区间与置信区间谁窄谁宽?
平均值的预测仅存在抽样误差。单个值的预测除了抽样误差外,还有其他干扰因素,所以预测区间PI总是要比对应的置信区间CI大。
针对均值的置信区间肯定要窄一些,而具体想预测某一个体值,那区间肯定要宽,因为误差会很大。
比如,让你预测一个公司中项目的平均生产率,与让你预测一个项目的生产率,你觉得哪个误差更大呢?对于一个公司的均值,即使你什么信息都不知道,估计预测的也差不到哪儿去,而让你预测某个项目的生产率,那你可能就不知所措了。
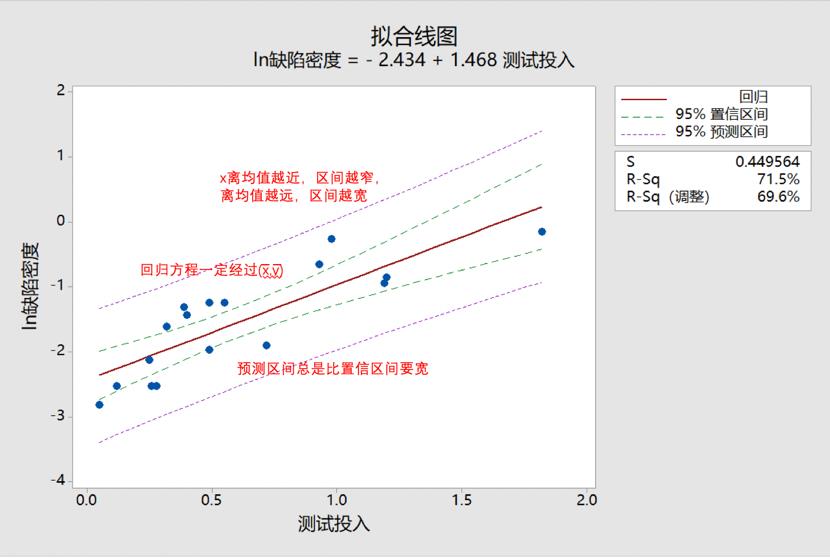
3 如何近似计算预测区间?
3.1 预测区间的简单计算公式
如果准确计算预测区间,公式是比较复杂的,而且需要建立方程的所有样本的数据,在实践中并不推荐这么做。所以通常我们都是近似计算预测区间。
预测区间的上限=预测值+1.96 残差的标准差;
预测区间的下限=预测值-1.96 残差的标准差;
上述公式是基于回归方程的理论假设推理出来的:
线性回归中,我们假定,对于每一特定的x值,其对应的y值应该是来自一个服从某一均值和标准差的分布,y是服从正态分布的。
在建立方程之前我们对此做了假设检验。
1.96倍标准差对应的区间,就是置信度为95%的区间。
残差的标准差在我们进行回归分析时,minitab的计算结果已经给出来了:

3.2 当对Y做了变换时,预测区间如何计算
在实际建模时,如果对y做了对数变换,比如:
lny=ax+b
则此时得到的残差标准差是lny的,不是y的,所以计算lny的预测区间为:
lny预测区间上限=ax+b+1.96S
则y的预测区间上限应该是:
y=exp(ax+b+1.96S)
y的预测区间下限应该是:
y=exp(ax+b-1.96S)
如果对y做了其他变化,道理类似。
以上是关于如何近似计算回归方程的预测区间?的主要内容,如果未能解决你的问题,请参考以下文章