STARKs, Part I: 多项式证明
Posted liuchengxu_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STARKs, Part I: 多项式证明相关的知识,希望对你有一定的参考价值。
相信很多人都听过 ZK-SNARKS,一个通用而简洁的零知识证明技术,从可验证计算到需要隐私保护的加密货币,它可以被应用于各类场景。不过,可能你还不知道现在 ZK-SNARKs 有了一个新兄弟:ZK-STARKs. 这里的 T 表示 “transparent”,“透明的”,ZK-STARKs 解决了 ZK-SNARKs 的一个主要的缺点,即 ZK-SNARKs 依赖于“可信启动(trusted setup)”。ZK-STARKs 也带来了更加简单的密码学假设,避免了使用椭圆曲线,配对和指数知识的假设(the knowledge-of-exponent assumption),并且完全地基于哈希和信息论。这也意味着,即使是面对使用量子计算机的攻击者,它仍然是安全的。
当然,这也是有代价的:一个证明的大小将从 288 字节(b)上升到几百 千字节(kb)。尽管在某些情况下,这些代价可能并不十分划得来,不过在另一些场景下,尤其对于需要高度的信任最小化的区块链应用,它可能是物有所值。而一旦椭圆曲线被破解,或者量子计算机真的到来的话,那么它必然是非常值得的。
那么,这种新的零知识证明到底是如何工作的呢?在这之前,先让我们来回顾一下,简洁通用的零知识证明做的是什么事情。假设你现在有一个(公开,public)函数 f,一个(私有,private)输入 x,和一个(公开,public)输入 y。在不透露 x 是什么的情况下,你想要证明你知道有一个 x 能够使得 f(x) = y(译者注:比如有一个保险箱,你要在不透漏密码具体是什么的情况下,证明你确实知道这个保险箱的密码)。此外,为了这个证明具有一定的简洁性,相比于通过计算 f 本身,你希望它能够通过一种更快的方式进行验证。

让我们来讨论几个案例:
f是一个计算,它需要在一台普通计算机上运行两周,但是一个数据中心只需要两小时即可完成。你可以把计算任务(也就是运行f的代码)发送给数据中心,数据中心执行计算,然后返回答案,也就是y证明。在几毫秒之内你就可以完成验证,并且可以确信y就是真实的答案。你有一笔经过加密的交易,形式为 “X1 是我旧的余额。X2 是你旧的余额。X3 是我新的余额。X4 是你新的余额”。你想要构建一个证明,证明这笔交易是有效的(具体来说,证明旧的和新的余额都是非负的,并且我的余额减少量刚好是你的余额增加量)。
x可能是一对加密密钥,f可能是一个函数,这个函数包含了一个内置公开输入的交易,输入密钥,解密交易,执行检查,如果通过的话返回 1,否则返回 0。y必然是 1 了。你有一个像以太坊一样的区块链,并下载了最新的块。你想要构造一个证明,证明这个块是有效的,并且它是链上最新的块,同时这个链里面的每个块都是有效的。你向一个已知的全节点询问来提供这样一个证明。
x是整个(全部?或者是部分)的区块链,f是一个按块处理它的函数,验证有效性并输出上一个块的哈希,而y就是你刚刚下载的块哈希。

那么,对于所有这些案例,其困难之处在哪儿呢?事实证明,零知识(也就是隐私)保证是(相对!)容易提供的。有多种方式可以将任何计算转换成一个类似三色图问题的一种,图的三着色与原始问题的解决方案有关,然后在不透露具体方案的情况下,使用一个传统的零知识证明协议,来证明你有一个有效的图色方案。这篇来自 Matthew Green 2014 年很棒的文章 对其中细节做了阐释。
更加困难的一件事情是 简洁性。直观来讲,简洁地证明计算相关的事情十分困难,因为计算 极其脆弱。如果你有一个很长很复杂的计算,并且假设你有一种能够在计算中间将任何一位(bit)从 0 变为 1 的能力,那么在很多情况下,即使是仅仅改变其中某一位,也足够使得计算产生一个完全不同的结果。因此,很难看出如何才能通过一些手段判定其正确性,比如随机采样一个计算轨迹,因为非常容易就会错过那“邪恶的一位(one evil bit)”。不过,通过一些花哨的数学方法,可以证明其实你是可以做到的。
一般高层次的直觉是协议可以实现这一点,类似 擦除编码 中使用的数学,它经常被用于使得数据具有容错性。如果你有一些数据,并且将这些数据编码为一条线,然后你可以从这条线上选出四个点。这四个点中的任意两个都可以重建这条线,因此也会给你另外两个点。进一步地,即使你对这些数据做出极微小的改变,然后保证这四个点的至少三个。你可以将这些数据编码为一个 1,000,000 次多项式,然后在这个多项式上选出 2,000,000 个点,任意一个 1,000,001 个点都会恢复原始数据,继而恢复其他点,原始数据的任何一点偏离都会改变至少 1,000,000 个点。这里展示的算法,大量通过这个途径利用了多项式来进行错误放大。

一个简单的例子
假设,你想要证明你有一个多项式 P,对于从 1 到 1 百万之间的所有 x,P(x) 是一个整数且 0 <= P(x) <= 9。这是十分常见的 “范围检查” 的一个简单示例。你可以把这种检查想象成某种验证,比如,在执行一些交易以后,一些账户余额仍然是正数。如果 1 <= P(x) <= 9,这就可能是检测一个正确的数独解的一部分。
证明这个问题的“传统” 方法是,遍历所有的 1,000,000 点,逐个对值进行校验来进行验证。但是,我们想要知道是否我们能够构造一个证明,它可以在小于 1,000,000 步的情况下得到验证。简单地随机对 P 进行求值校验无法做到这一点;总是有可能出现一个恶意证明者,他会想出一个 P,这个 P 满足在 999,999 位置内的限制,但是不满足最后一个,那么随机采样仅有的几个值,将会总是错过那个正确的值。那么,我们可以做什么呢?

让我们从数学上对这个问题进行一下转化。让 C(x) 为一个 约束检查多项式(constraint checking polynomial),如果 0 <= x <= 9,C(x) = 0 否则为非 0。构造 C(x) 有一个简单的方式: x * (x-1) * (x-2) * ... * (x-9)。
现在,问题变成了:证明你知道 P,对于从 1 到 1,000,000 的所有 x,都有 C(P(x)) = 0。让 Z(x) = (x-1) * (x-2) * ... (x-1000000)。这是一个已知的数学事实,对于从 1 到 1,000,000 的所有 x,任何等于零的多项式都是 Z(x) 的一个乘积。因而,问题可以被再次转化:对于所有的 x ,证明你知道 P 和 D, 满足 C(P(x)) = Z(x) * D(x) (注意,如果你知道一个合适的 C(P(x))),然后除以 Z(x) 来计算 D(x) 并不太难;你使用 多项式长除法 ,或基于 快速傅里叶变换 更具有实际意义更快的算法)。现在,我们已经将原始命题转化为一个看起来数学上更清晰,也更可证的一个问题。
那么,要如何证明呢?我们可以把证明过程想象成证明者和验证者之间一个三步的交流过程:
- 证明者发送一些信息
- 然后验证者发送一些请求
- 然后证明者再发送一些信息
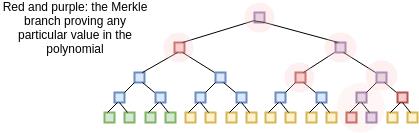
首先,证明者提交(也就是,生成一个 Merkle 树并且将根哈希发送给验证者)对于从 1 到 10 亿(是的,10 亿)之间的所有 x, P(x) 和 D(x) 的值. 这包含了 1 百万个点,而 0 <= P(x) <= 9 且 9.99 亿个(可能)是状况外的点。

我们假设验证者已经知道了 Z(x) 在所有这些点上的值;在这个方案中,Z(x) 就像是一个 公开验证密钥,每个人都必须提前知道(客户端没有存储 Z(x) 的空间,因为它整个可能只是简单地存储了 Z(x) 的 Merkle 根,并需要证明者同时提供验证者需要查询的每个 Z(x) 值的分支;又或者,对于某个 x ,有一些在 Z(x) 之上非常容易计算的数字)。在获得提交(也就是 Merkle 根)后,验证者在 1 和 10 亿之间随机选择 16 个 x 的值,并要求证明者提供这些值上 P(x) 和 D(x) 的 Merkle 分支。证明者提供这些值,验证者检查:
- 分支与之前提供的 Merkle 根相匹配
C(P(x))在所有 16 种情况下都等于Z(x) * D(x)
我们知道这个证明改善了完备性 – 如果你真的知道一个合适的 P(x),然后如果你计算 D(x) 并且正确地构造出证明,那么这 16 个检查都将顺利通过。但是 可靠性 怎么样呢? – 也就是,如果一个恶意证明者提供了一个坏的 P(x),他们被发现的最小概率是多少?我们可以进行如下分析:因为 C(P(x)) 是一个 1,000,000 次多项式,它的次数至多是 10,000,000。通常来说,我们知道两个不同的 N 次多项式至多相交 N 个点。因此,对于某个 x,一个 1,000,000 次多项式,一个总是等于 Z(x) * D(x) 的任意多项式,这两个多项式若不同,那么将会必然在至少 990,000,000 个点上都不同。故而,即使是只检查一次,一个坏的 p(x) 被发现的概率已经是 99%,再加上有 16 次检查,被发现的概率会上升到 1- 10 ^ -32。也就是说,该方案与计算哈希冲突一样难以欺骗。
所以,我们刚刚到底分析了些什么?我们使用多项式“增强”了在任何不好的解决方案中的错误,也就是将原始问题糟糕的解决方案,即需要直接执行一百万次检查,变成了一个验证协议的方案,该防范即使进行一次检查,就能够 99% 地标识出错误。
我们可以将这个三步的机制转化为一个非交互式证明,也就是在利用 Fiat Shamir heuristic 的基础上,一个证明者可以将它进行广播,然后被所有人进行验证。证明者首先构建一棵 P(x) 和 D(x) 值的 Merkle 树,然后计算树的根哈希。根自身随后被用作是熵的来源,熵决定了证明者需要提供树的哪个分支。证明者然后一起广播 Merkle 树根和分支作为证明。计算全部在证明者一端完成。从数据中计算 Merkle 树根,然后用它来挑选要审计的分支,高效地取代了一个交互式验证者的需要。
对于一个没有有效 P(x) 的恶意证明者,他能做的唯一事情是进入尽力不断地构造一个有效证明,直到他们最终足够幸运的话,找到了他们选择计算的 Merkle 树根分支。不过鉴于可靠性是 1 - 10 ^ -32(也就是,对于一个给定的假证明,至少有 1-10^-32 的概率无法通过检查),这可能会耗费恶意证明者数十亿年的时间来找到一个可通过检查的证明。

进一步探究
为了阐释这个技术的强大之处,让我们来用它做一点不寻常的事情:证明你知道第一百万个斐波那契数。为此,我们会证明你知道一个表示一个计算带的多项式,而 P(x) 表示第 x 个斐波那契数。约束检验多项式现在会跨越 3 个 x 坐标:C(x1, x2, x3) = x3 - x2 - x1(注意,对于所有的 x, P(x) 表示一个斐波那契额序列,如果 C(P(x), P(x+1), P(x+2)) = 0 会怎样)。

转换后的问题变成了:验证你知道 P 和 D 使得 C(P(x), P(x+1), P(x+2)) = Z(x) * D(x)。对于证明审计的 16 中情况中的每一个,证明者需要提供用于 P(x),P(x+1),P(x+2) 和 D(x) 的 Merkle 分支。证明者额外还需要提供 Merkle 分支来表明 P(0) = P(1) = 1。否则,整个过程都是一样的。
现在,要想在现实中实现它,还需要解决两个问题。第一个问题是,如果想要实际应用于普通数字,这个方案不够高效,因为数字本身非常容易变的极大。比如,第一百万个斐波那契数有 208988 位。如果我们真的想要在实践中达到简洁的要求,不是在普通数字上计算多项式,而是需要使用有限域(finite field) – 即仍然遵循同样数学规则的数字系统,比如 a * (b+c) = (a*b) + (a*c) 和 (a^2 - b^2) = (a-b) * (a+b),但是这个数字系统中的每一个数字都保证只占据常量空间。证明第一百万个斐波那契数将会需要一个更加复杂的设计,这个设计在这个有限域数学之上实现大数算术。
最简单最可能的有限域是模块化数学。也就是,对于某个质数 N,使用 a + b mod N 替换每一个 a + b 。将同时的操作应用与减法和乘法,对于除法,使用 modular inverses(比如,如果 n = 7,那么 3 + 4 = 0,2 + 6 = 1,3 * 4 = 5,4 / 2 = 2 ,5 / 2 = 6)。你可以 这里 (在页面上搜索 “prime field”)了解更多关于这类数字系统,在里面我对质数域做了一些介绍。或者从有关模块化数学的 维基百科(在文章内直接搜索 “finite fields” 和 “prime fields”,可能看起来非常复杂,与抽象代数直接相关,但是不要在意这些)了解更多。
第二,你可能已经注意到,在我上面的可靠性证明梗概中,我忽略了一种攻击:不用似然的 1,000,000 次 P(x) 和 9,000,000 次 D(x),攻击者提交另一些值,这些值不来源与任何相对低次的多项式?然后,一个无效 C(P(x)) 的参数,必须在至少 990 百万不适用的点上不同于任何有效 C(P(x)),所以也就可能出现更多的这种有效攻击。比如,一个攻击者可以为每一个 x 生成一个随机值 p,然后计算 d = C(p) / Z(x) ,然后提交这些值替换 P(x) 和 D(x)。这些值不会是基于任何一种低次多项式,但是它们会通过测试。
事实证明,尽管用到的工具可能相当复杂,但上面这种可能性仍然可以进行有效地防范,现在你可以非常负责任地说,它们确实填补了 STARKs 中数学创新的空缺。不过,这个解决方法也有一个限制:虽然你可能会剔除与 1,000,000 次多项式相差甚远(比如,你会需要改变所有值的 20% ,使它成为一个 1,000,000 次多项式)的一些数据保证(commiment to data),但是你无法排除仅在于只有一两个坐标不同的多项式数据。因此,这些工具将提供临近证明(proof of proximity) – 证明 P 和 D 上的大多数点都与那类多项式相关。
因此,尽管有两个“意外情况(catches)”,但是构建一个证明仍然是足够的。首先,验证者需要再多检查一些情况,为其局限性所引入的错误留一些余地。第二,如果我们正在做“边界约束检查(boundary constraint checking)”(比如,证明上面斐波那契案例中的 P(0) = P(1) = 1 ),然后,我们需要扩展临近证明,不仅证明大多数点都在同一个多项式上,而且证明这两个(或你想要检查的任何点数)特定点都在这个多项式上。
在这个系列的下一部分,我会继续解读临近检查问题的解决方案。
原文:STARKs, Part I: Proofs with Polynomials
以上是关于STARKs, Part I: 多项式证明的主要内容,如果未能解决你的问题,请参考以下文章