一文详解人工智能分类方面的KPI评价标准:混淆矩阵TPFPFNTNP-R曲线图ROC曲线图
Posted 17岁boy想当攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文详解人工智能分类方面的KPI评价标准:混淆矩阵TPFPFNTNP-R曲线图ROC曲线图相关的知识,希望对你有一定的参考价值。
目录
样本概念
在深度学习过程中我们会用数据集来做训练,如我们做人脸识别时需要不同的人脸特征作为数据集,这些数据集可以也可以叫做样本,样本也分为两种类型,分别是正样本与负样本,正样本就是我们要识别的人脸特征,被我们打标记的数据集,而负样本就是没有被打标记的样本,主要负责给模型提供参考点,增强模型的强壮性。
负样本有一定要求,不能是与正样本毫无联系的数据集,如我们训练人脸,那么首先我们需要考虑人会出现在哪种场景下,一般有人的场景周围都有什么,例如:凳子,电脑,空荡荡的房间,床,水杯,空调,街道等这些可能出现人的地方,或者穿在人身上的衣服,这些都可以算是负样本,供机器学习来学习作为参考点,一旦图片中出现负样本的特征则猜测图片中具有人,然后对图像做深度卷积找到人脸特征,其次是当图像中出现多个特征时忽略接近负样本的特征。
混淆矩阵理论知识
混淆矩阵(Confusion Matrix)又称误差矩阵,在深度学习方面被称为可能性表格,它的作用是对一组分类数据进行指标评价的矩阵,它由N行N列组成,也就是二维数组,每行都是一个分类输入源,每列里记录了分类,它就是一个记录分类结构的矩阵。
概念
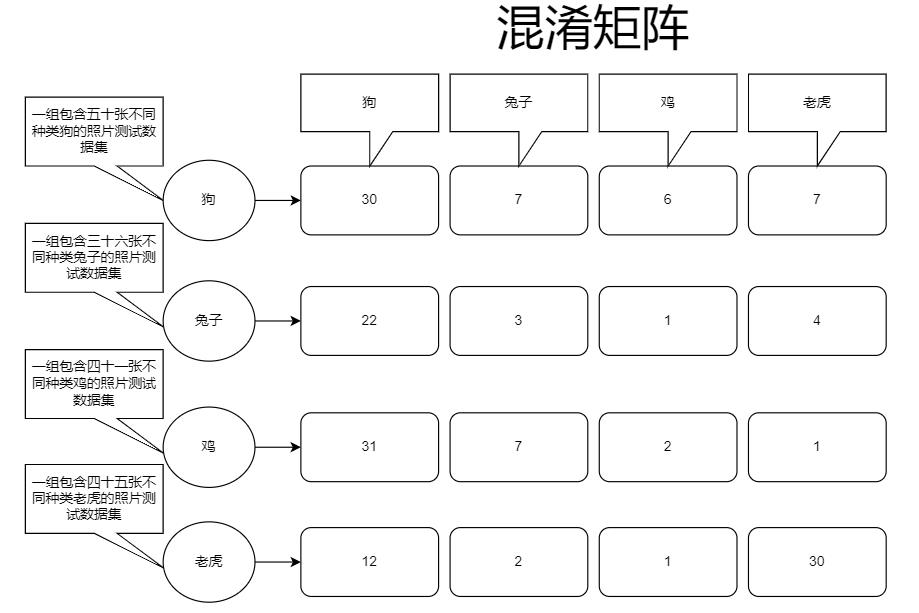
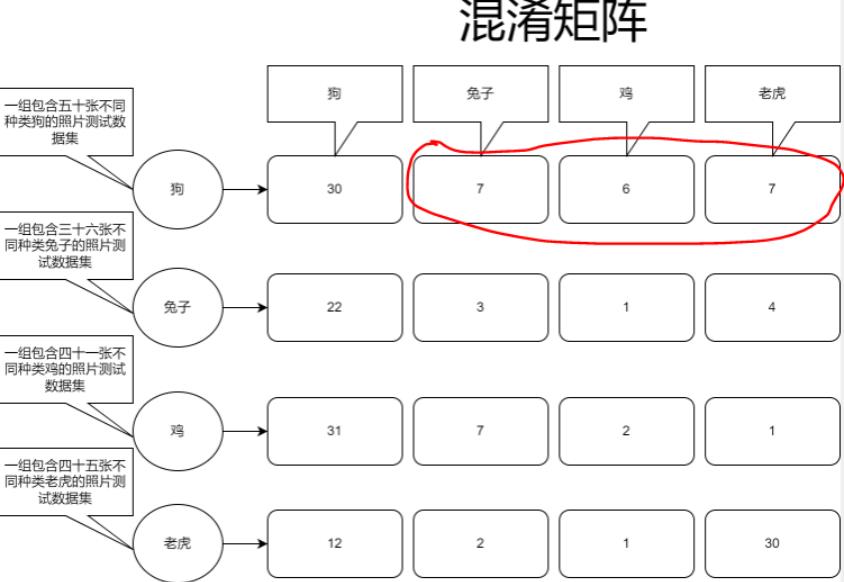
如我们有这样一个模型,它是由“狗、兔子、鸡、老虎”这些训练集特征训练而成的一个模型,那么我们需要对这个模型进行批判来确定模型的准确率,来确定它的好坏以及分类结果这样才能对模型进行调整,如下图:
我们可以看到输入源,第一组输入是五十张不同狗的照片,对模型里分类全连接层进行预测时的结果是:30张为狗的照片,7张被识别成了兔子,6张被识别成了鸡,还有7张被识别成了老虎,混淆矩阵主要作用就是记录这个,通过混淆矩阵的记录值我们就能明确看出当前训练情况,可以看出训练还不是特别优越,所以还需要进行训练集调整或算法上的调整,或者将训练次数增多等等,来优化模型。
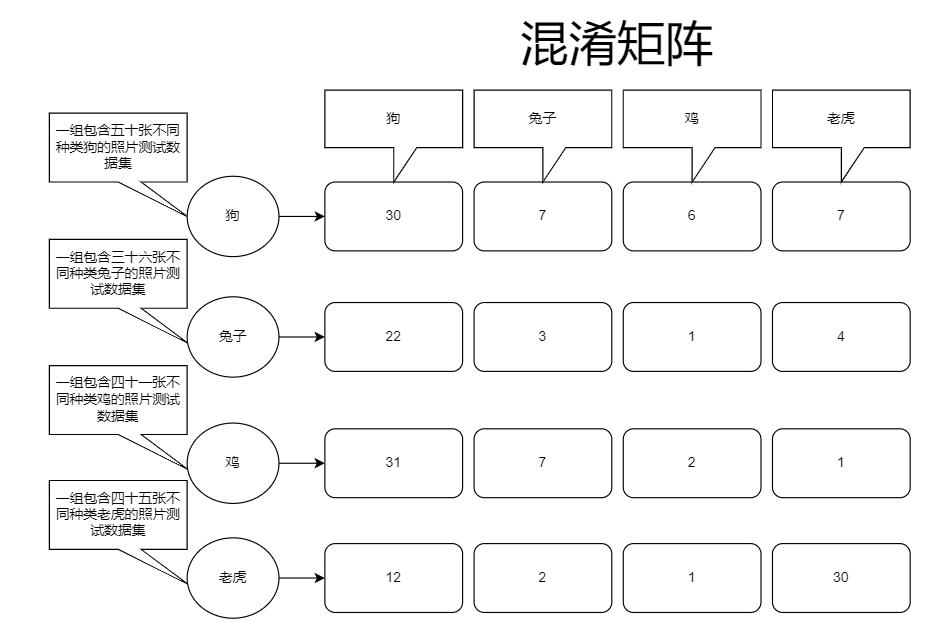
在经历N次迭代之后变成了这样:
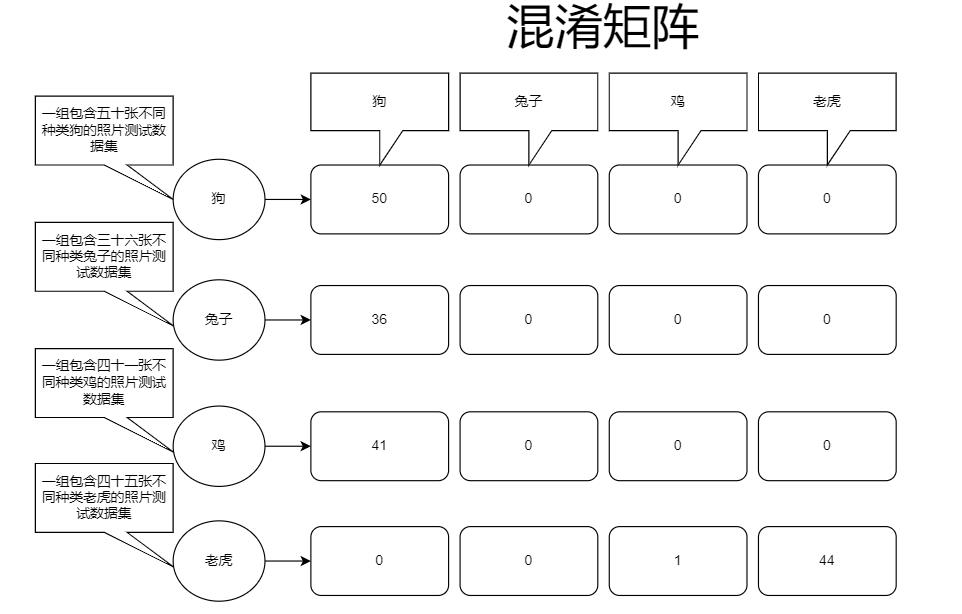
虽然还是有一点瑕疵,因为老虎这组数据预测上,有一张被预测成了鸡,所以我们可以通过找到那张照片来分析为什么会被识别成鸡,也可以直接调整算法或继续训练直到混淆矩阵变得非常可观。
TP、FP、FN、TN介绍
概念
这里以理论知识里的一组混淆矩阵数据做示例
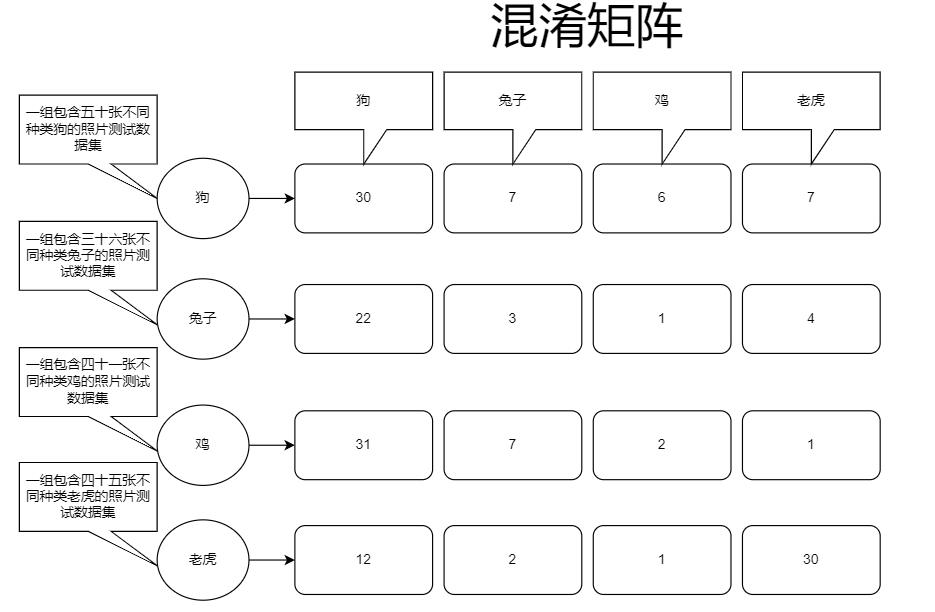
这是混淆矩阵的输出,我们将上图狗的实际识别成功的数据进行统计分析,得到这样一组数据:
这里解释一下这组数据是什么意思,在解释之前需要了解几个名词:
TP
TP全称True Postive(真阳性)
概念角度
预测结果是真,实际结果也是真
样本角度
表示把正样本预测为正样本;
FP
FP全称False Positive(假阳性)
概念角度
预测结果为真,实际为假
样本角度
表示把负样本预测为正样本
FN
FN全称False Negative(假阴性)
概念角度
预测为假,实际上为真
样本角度
表示把正样本预测为负样本
TN
TN全称True Negative(真阴性)
概念角度
预测结果为假,实际上也为假
样本角度
表示把负样本预测为负样本;
备注
TP、FP、FN、TN都是分类统计的指标,用来计算准确率的因子值
关系解释
上图的数据与TP、FP、FN、TN是对应关系
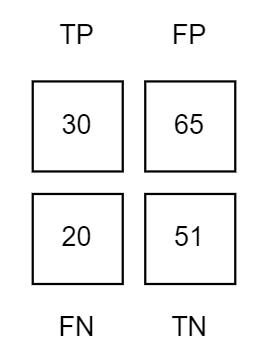
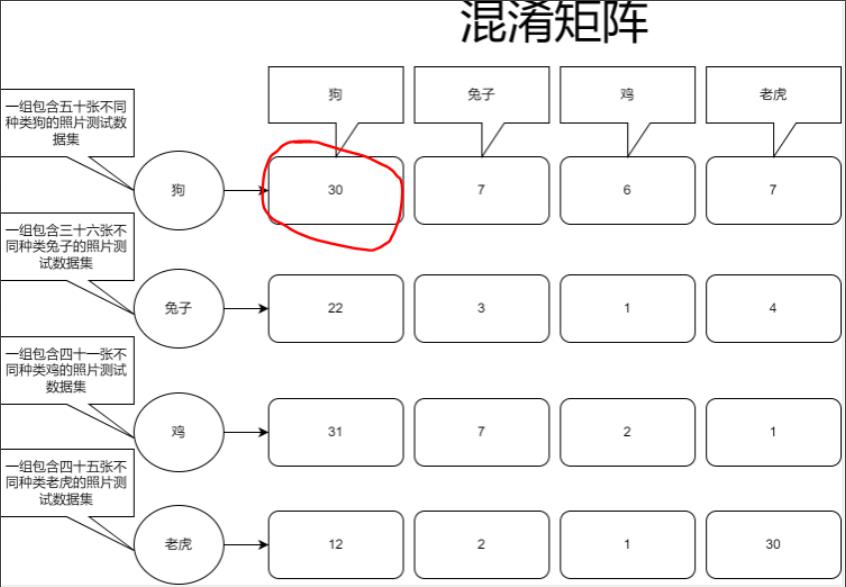
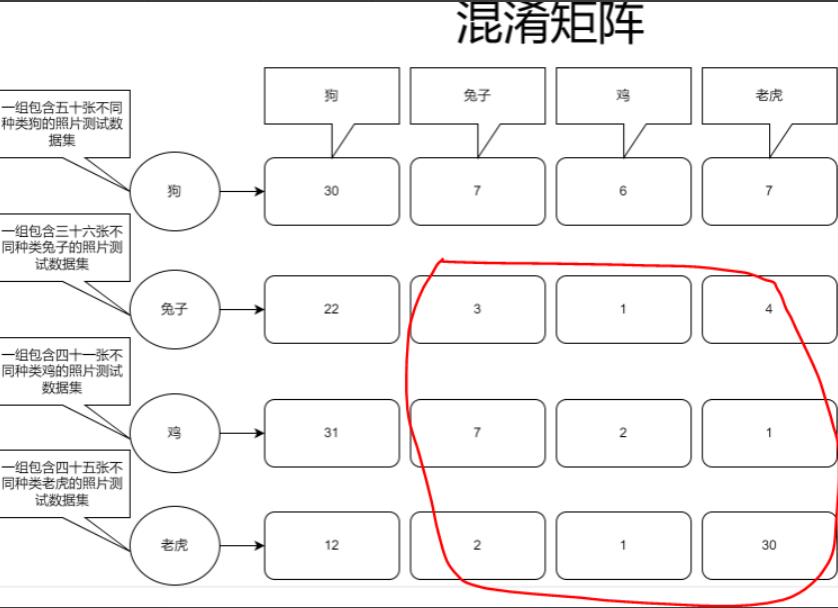
这里解释一下这些数据是怎么统计来的,刚开始说的计算狗的精确度,我们的混淆矩阵数据输出如下:
TP即预测结果为真实际结果也为真,那么可以看到狗的分类里是30,所以它也就是30
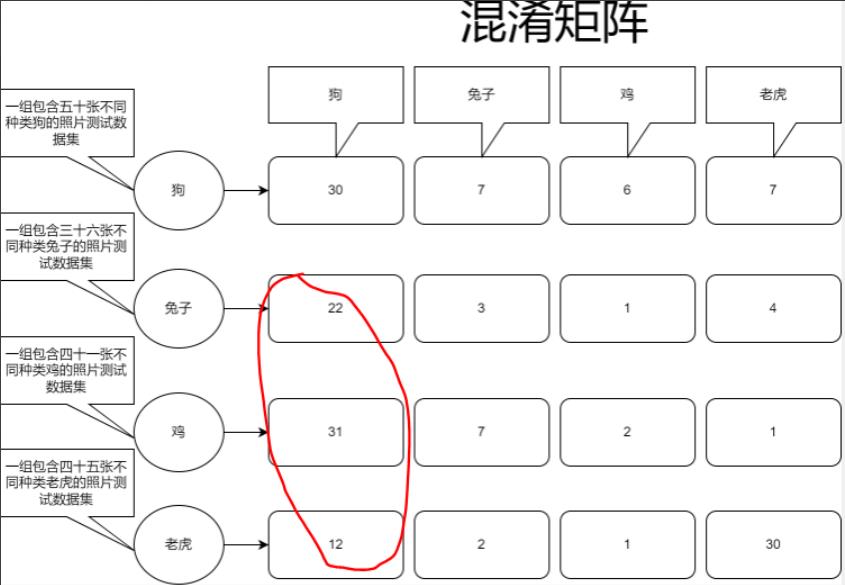
FP预测结果为真实际上为假,我们可以看到兔子这组训练集里22张被预测为了狗,鸡31,老虎12,所以加起来是:65,因为这些数据集虽然被预测为真,但实际上它们并不是狗
FN预测为假实际上为真,我们从第一列数据就可以得出我们输入了50张狗的照片,只有30张被识别成了狗,其它的20张被识别其它的,所以预测结果是假的,但是实际上这几种照片是狗
 TN就是预测结果为假,实际上也是假,我们直接把其它训练集预测不是狗的总数加起来就可以了,因为这些数据没有被识别成狗,它们被识别成了其它的,也的的确确是假的
TN就是预测结果为假,实际上也是假,我们直接把其它训练集预测不是狗的总数加起来就可以了,因为这些数据没有被识别成狗,它们被识别成了其它的,也的的确确是假的
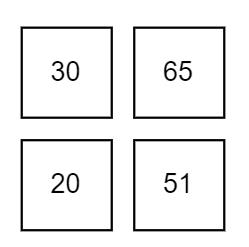
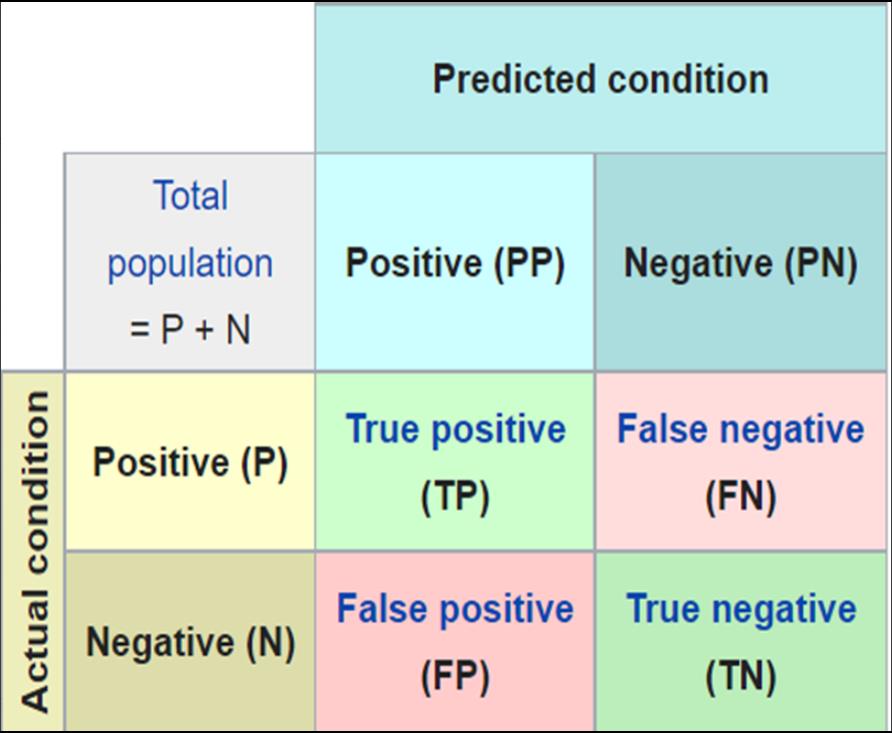
一般我们经过上面的分析计算后可以得到这样的一组格式数据:
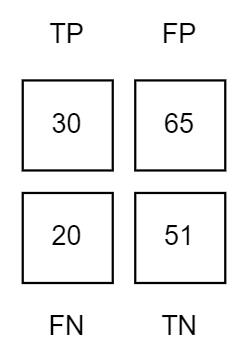
将我们的真实数据填写上去就变成了这样:
PP(预测结果为正样本的数量合集),PN(预测结果为负样本的结果合集)
| 166 | 95 | 71 |
|---|---|---|
| 70 | 30 | 20 |
| 116 | 65 | 51 |
Key Performance Indicator
Key Performance Indicator简称KPI即关键绩效指标
下面是在深度学习方面的KPI的几个指标
有了上面的数据因子,我们就可以拿这些因子来评价我们的模型,如我们评价预测狗的指标
Precision
标准介绍
精准率,查准率
概念介绍
预测的数据集中有多少张样本图片是狗
样本概念介绍
预测为正的样本中有多少是真正的正样本
公式
预测为真阳性/所有预测结果都为真阳性的样本,包括即便结果是错的 Precision=TPTP+FP
实际计算
我们用刚刚统计预测狗的混淆矩阵数据:
Precision=30/30+65
Precision=0.31578947
在做一个百分比计算
0.31578947*100=31%
所以预测狗的精准率达到31%
Recall
标准介绍
召回率,查全率
概念介绍
预测数据集中有多少样本图片被正确预测成狗了,这个样本指的是单一狗的样本,不包括非狗的样本
样本概念介绍
即表示样本中有多少正样本被正确预测了
公式
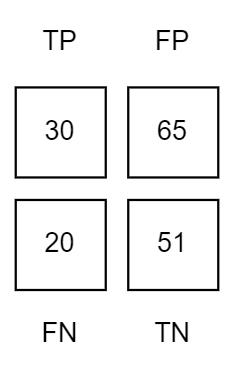
(预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN) Recall=TPTP+FN
实际计算

Recall=30/30+20
Recall=0.6
百分比:0.6*100=60%
召回率=60%
F1 Score
标准介绍
精准率和召回率的调和平均数,主要应用于加权重方面,类似平均误差函数
公式
实际计算
我们用刚刚统计预测狗的混淆矩阵数据:
Precision=30/30+65
Precision=0.31578947
在做一个百分比计算
0.31578947*100=31%
所以预测狗的精准率达到31%
Recall
标准介绍
召回率,查全率
概念介绍
预测数据集中有多少样本图片被正确预测成狗了,这个样本指的是单一狗的样本,不包括非狗的样本
样本概念介绍
即表示样本中有多少正样本被正确预测了
公式
(预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN)
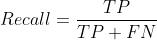
实际计算
Recall=30/30+20
Recall=0.6
百分比:0.6*100=60%
召回率=60%
F1 Score
标准介绍
精准率和召回率的调和平均数,主要应用于加权重方面,类似平均误差函数
公式
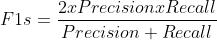
实际计算
用我们上面的数据:
Precision=0.31
Recall=0.6
F1s=2*0.31*0.6/0.31+0.6=1.8
调和平均数不能做百分比运算,它的主要作用是用于加权,类似误差函数,用于补偿
Accuracy介绍
标准介绍
精确率,准确率
概念介绍
所有样本中,被正确预测的样本数量,这个样本里包括狗和其它的样本,所有样本的数量里被成功识别为狗的数量
样本概念介绍
被正确预测的样本占所有预测样本的比例
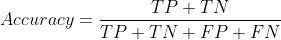
实际计算
Accuracy = 30+51/30+51+65+20
Accuracy = 0.48795181
百分比:0.48795181*100=48%
精确率为48%
最终结果
经过上面的计算统计,我们预测狗的最终数据如下:
| Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|
| 31% | 60% | 1.8 | 48% |
备注
从识别狗时我们会出现其它图片,非狗的图片,这些在这次训练集中可以算是负样本,只有狗的图片才是正样本
P-R曲线图
在上述指标中我们会期望两个标准越高越好:Precision(精准率:样本中有多少是正样本),Recall(召回率:正样本中有多少被正确识别了),这两个标准可以衡量出正样本的正确率,如果它非常高则代表你的正样本都被识别了。
这里说一下为什么不用Accuracy,因为Accuray是代表着所有样本中被正确识别的样本,它的值是属于总和样本的,包括负样本也参与运算了数值比较广泛,而Precision和Recall会相结合会更加精确,这个方法也叫置信度,就是判断输入样本被识别为正样本的概率是多少。
所以这两个指标被称为P-R标准,一般用于绘制曲线图,也称为P-R曲线图,
我们可以使用Python的Matplotlib库来画曲线图
绘图也非常简单,在P-R曲线图中,Precision代表Y,Recall代表X,就拿本篇的数据来说,测试数据集狗的P和R分别是:0.31和0.6,分别对应Y:0.32,X:0.6
代码如下:
import numpy as np
import matplotlib.pyplot as plt
x=[0,0.6]
y=[0,0.31]
plt.figure()
plt.plot(x,y)
plt.savefig("test.jpg")运行之后本地就会生成一个test.jpg的图像文件,打开之后显示如下:
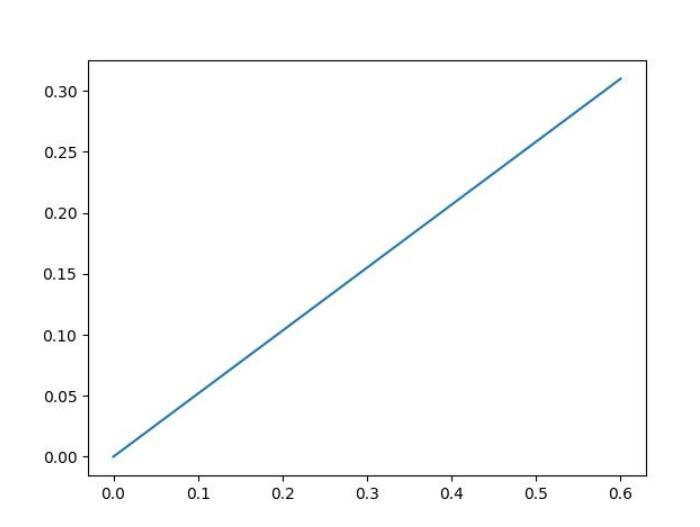
曲线非常平滑,这个原因是因为我们的样本数据非常少,就一个,所以非常平滑,通常情况下越平滑意味着模型置信度越好,准确率越高。
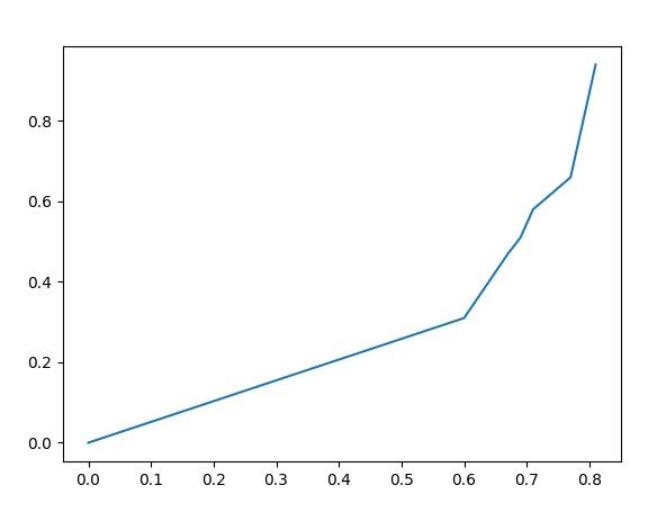
我们尝试增加更多的数据集:
import numpy as np
import matplotlib.pyplot as plt
x=[0,0.6,0.67,0.69,0.71,0.77,0.81]
y=[0,0.31,0.47,0.51,0.58,0.66,0.94]
plt.figure()
plt.plot(x,y)
plt.savefig("test.jpg") 运行输出如下: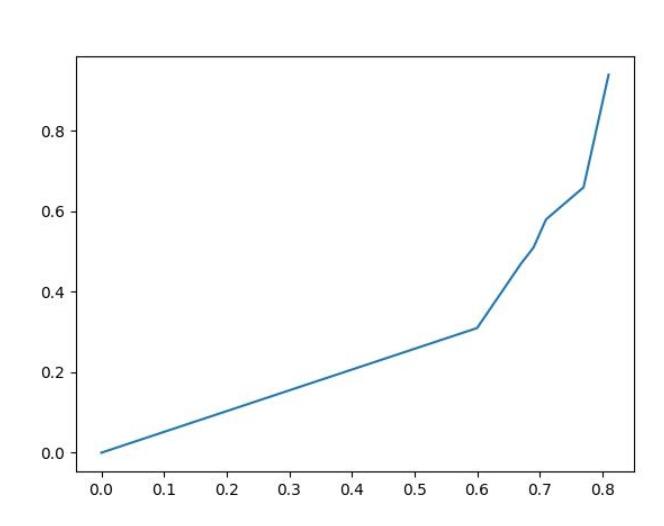
在输入数据时记得从大到小排序,因为曲线图其实是趋势图,如果你的数据不是从小到大排序的看起来就会非常的乱,逐步增长代表我们的预测结果逐步变好,代表我们的模型置信度越来越高,理论上来说P与R都应增长为(0,1),平滑增长没有折线的,因为这样的模型置信度是最高的。
ROC曲线图
ROC曲线全称Receiver Operating Characteristic Curve(接受者操作特性曲线),又称感受性曲线(sensitivity curve),在解释ROC曲线之前需要先了解两个概念:TPR(True Positive Rate 真阳性率)、FPR(False Positive Rate 真、假阳性率),它们俩是构建ROC的主要变量,ROC曲线图主要思路是利用构图的方式来表示敏感性和特异性,ROC最早起源于医学上,用于表示医学诊断结果,其中敏感性和特异性是统计学上的名词,它俩的代表的含义分别如下:
敏感性
敏感性也称敏感度
医学角度
敏感性即肿瘤化验组中化验结果阳性比例,敏感性越接近100%就越表明该肿瘤能被检测出真阳性的肿瘤患者。
深度学习角度
预测样本中,为正样本的比例,比率越接近100%代表能正确预测的概率越大
特异性
特异性也称特异度,它与敏感度相反
医学角度
特异性即肿瘤化验组中化验结果阴性比例,特意性越接近100%就越表明该肿瘤能被检测出假阳性的患者。
深度学习角度
预测样本中,为负样本的比例,比率越接近100%代表样本被错误预测的概率越大
在深度学习上敏捷性与特异性对应是TPR与FPR,它俩的概念如下:
TPR
TPR全称True Positive Rate即真阳性率,即表示预测样本中所有被认为是正样本的数据,即预测是正样本实际也是正样本(TP)和预测为负样本实际上是正样本(FN)的数量,在曲线中它代表Y轴
它的算法公式如下:
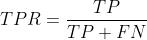
FPR
FPR全称Flase Positive Rate假阳性率,即预测结果为正样本实际上为负样本(FP)和预测结果为负样本实际上也是负样本(TN)的集合,在曲线中它代表X轴
它的算法公式如下: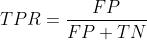
总的来说ROC曲线图就是统计一组数据的正负比率然后用曲线的方式显示出来,用于表示预测正负的概率。
我们使用Python进行绘制:
import numpy as np
import matplotlib.pyplot as plt
x=[0,0.15,0.17,0.24,0.37,0.47,0.50]
y=[0,0.70,0.77,0.79,0.81,0.85,0.90]
plt.figure()
plt.plot(x,y)
plt.savefig("test.jpg")运行结果:
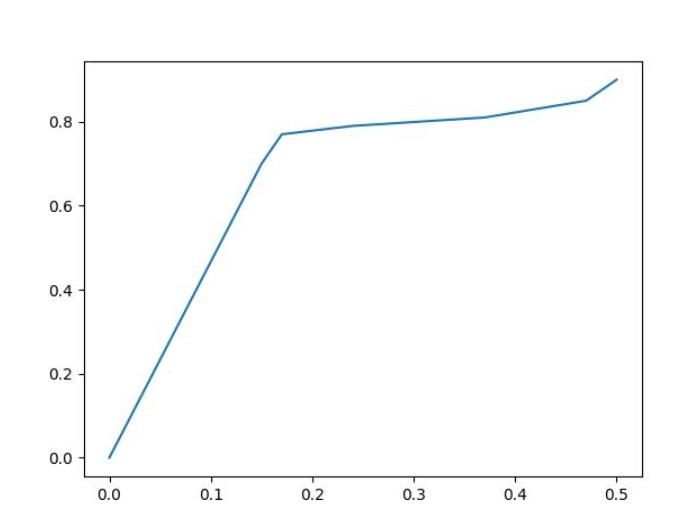
结尾
可以把本文中的正样本与负样本理解为真或假,0/1
一般情况下我们训练好模型之后都会使用上述KPI进行评价之后可以得到如下一个表格与曲线图:
PPV=精确度
ACC=精准度
TPR=真阳率
FPR=假阳率

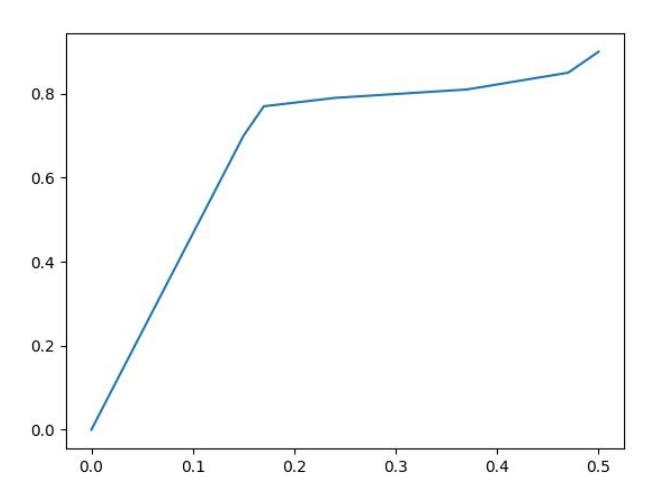
有了上图这组数据后我们进行P-R曲线图绘与ROC曲线图用来表示置信度与预测概率,它们俩的曲线应相似,因为它们所表示的结果都偏向于预测正确的角度。
P-R曲线
ROC曲线
以上是关于一文详解人工智能分类方面的KPI评价标准:混淆矩阵TPFPFNTNP-R曲线图ROC曲线图的主要内容,如果未能解决你的问题,请参考以下文章