一步步学Metal图形引擎3-《MTLVertexDescriptor》
Posted Mr_厚厚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一步步学Metal图形引擎3-《MTLVertexDescriptor》相关的知识,希望对你有一定的参考价值。
教程 3
MTLVertexDescriptor
教程源码下载地址: https://github.com/jiangxh1992/MetalTutorialDemos
CSDN完整版专栏: https://blog.csdn.net/cordova/category_9734156.html
一、知识点
- MTLVertexDescriptor
- AOS & SOA
- attribute语义绑定
二、MTLVertexDescriptor顶点结构描述
2.1 MTLVertexDescriptor是什么
官方对MTLVertexDescriptor的解释:
MTLVertexDescriptor是用来描述如何组织顶点数据以及如何映射到shader中顶点着色函数的对象。
一个MTLVertexDescriptor对象用来配置顶点数据如何在内存中存储,以及映射到vertex shader中的attribute属性上。
一个pipeline state表示图形渲染管线的状态,包括shaders,混合,多采样和可见性测试。对于每一个pipeline state,只会对应一个MTLVertexDescriptor对象。在创建pipeline state在时如果配置了MTLRenderPipelineDescriptor对象到pipeline state的vertexDescriptor属性上,那么这个MTLRenderPipelineDescriptor对象构建的顶点layout组织结构就会应用于和这个pipeline相关的函数。
总之,每个渲染管线只会设置一个MTLVertexDescriptor,来组织顶点结构,而MTLVertexDescriptor的设置时取决于我们的模型数据的,例如我们加载一个obj模型,它的顶点数据可能有position,normal,uv,tangent等,我们需要设置与之对应的MTLVertexDescriptor结构来正确解析和接受模型数据,并将数据映射传到vertex shader中进行计算。可以说MTLVertexDescriptor是模型数据在CPU代码中的表示到GPU shader函数中属性数据的映射粘合剂。
PLUS:但MTLVertexDescriptor并不是必须使用的,因为将顶点缓冲VB传送给vertex shader的方式除了用MTLVertexDescriptor描述顶点结构然后在顶点着色函数中用[[stage_in]]属性接收,还可以直接通过设置顶点buffer传给顶点着色函数[[buffer(id)]],并根据[[ vertex_id]]属性定位当前顶点的数据。
2.2 着色函数和顶点数据
我们知道函数本质上是用来转换数据的,将输入的数据转换成输出的数据,shader中的着色函数也一样。例如:vertex function将模型空间的顶点数据转换成裁剪空间的顶点数据,fragment function将光栅化的数据转换成片段最终的颜色数据。
但我们要处理的数据,例如模型数据,一般都是外部数据,因此我们的函数要有参数,将外部数据通过参数传递给函数内部进行处理。而着色函数是由GPU调用的,我们在CPU上写的逻辑代码不能直接将数据传送给着色函数。下面就解析我们是如何通过MTLVertexDescriptor配置等方式将模型数据传送给着色函数的。
2.2.1 顶点数据结构以及数据获取
这里举例子设计一个非常简单的顶点数据结构如下:
typedef struct
vector_float2 pos;
vector_float2 uv;
AAPLVertex;
就假设我们的模型顶点数据只有顶点位置和纹理坐标这两个属性,当然实际上一般模型还会有法线、切线等属性。
然后我们利用这个数据结构简单自定义一个对应的模型数据如下:
static const Vertex vert[] =
0,1.0, 0.5,0,
1.0,-1.0, 1.0,1.0,
-1.0,-1.0, 0,1.0
;
这个模型定义的是一个三角形模型,一共3个顶点。
然后我们需要将模型数据拷贝到我们程序的buffer中,这里是在Objective-C环境下,我们将数据放到准备好的MTLBuffer中,拷贝方式有下面两种:
id<MTLBuffer> _quadBuffer;
// 第一种直接在创建buffer时使用顶点数据初始化:
_quadBuffer = [_device newBufferWithBytes:verts length:sizeof(verts) options:MTLResourceStorageModeShared];
// 第二种先创建buffer,之后在合适的时机把数据拷贝进去
_quadBuffer = [_device newBufferWithLength:1024 options: MTLResourceStorageModeShared];
//...
memcpy(_quadBuffer.contents, verts, sizeof(AAPLVertex) * 6);
2.2.2 将数据buffer从CPU传送给GPU中的着色函数
Metal将数据传给GPU的方式比较灵活,可以使用传统的Argument Table直接setBuffer给着色函数,也可以通过这里讲的使用MTLVertexDescriptor配置走stage流程传送顶点数据,另外还可以使用最新的特性Argument Buffer封装数据进行统一传送。
这里先介绍通过定义和配置MTLVertexDescriptor对象,来自动传送数据到管线各阶段的方式。
CPU传送数据给GPU
根据上面的顶点的数据结构,我们应该定义MTLVertexDescriptor对象并按如下进行配置。
vertexDescriptor = [[MTLVertexDescriptor alloc] init];
// pos
vertexDescriptor.attributes[0].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[0].offset = 0;
vertexDescriptor.attributes[0].bufferIndex = 0;
// uv
vertexDescriptor.attributes[1].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[1].offset = 8;
vertexDescriptor.attributes[1].bufferIndex = 0;
// layout
vertexDescriptor.layouts[0].stride = 16;
vertexDescriptor.layouts[0].stepRate = 1;
vertexDescriptor.layouts[0].stepFunction = MTLVertexStepFunctionPerVertex;
可见由于我们的顶点数据只有pos和uv两个属性,因此MTLVertexDescriptor只配置了两个属性,pos和uv都只有2个浮点数,因此他们的属性格式format为MTLVertexFormatFloat2。这里同一个顶点的不同属性是连续定义在同一个buffer上的所以需要设置offset,pos的2个浮点数占用4*2=8个字节,所以uv的offset为8。然后需要注意MTLVertexDescriptor的layouts配置,由于是连续定义在同一个buffer中所以这里只配置了一个layouts[0],stride属性表示每次去取一个顶点数据的数据跨度,这里每个顶点数据占16字节,所以stride设置为16。
另外关于stepRate和stepFunction的含义和作用,此处不展开讨论,主要用在Instance rendering和Tessellating等技术中。
现在看下MTLVertexDescriptor在管线结构中的位置:
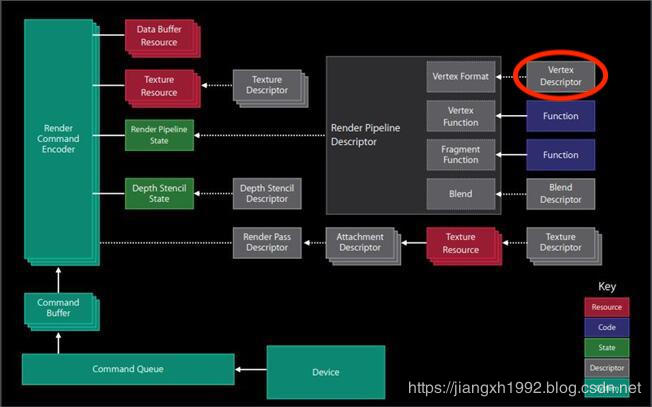
可以看到MTLVertexDescriptor是服务于RenderPipelineDescriptor用来配置Vertex Format顶点结构的,而RenderPipelineDescriptor用来创建我们的pipeline状态对象。于是它们的用途和关系如下:
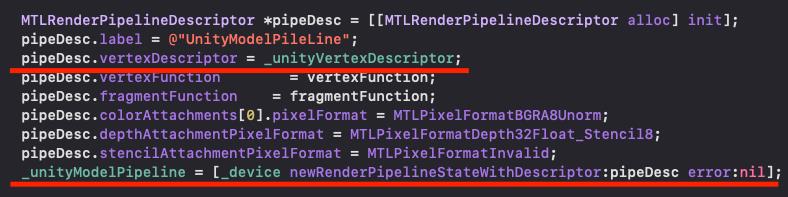
顶点结构配置好了之后,在绘制模型之间要记得将顶点数据buffer传送给默认的buffer(0):
[_myRenderEncoder setVertexBuffer: _quadBuffer offset:0 atIndex:0];
这样在指令提交后数据就会按照指定格式往GPU传送了。
上面说到代码中MTLVertexDescriptor是将数据连续存储在同一个buffer上,实际上也可以将数据分别并行放到多个buffer上,例如上面position数据放到第一个buffer,uv放到第二个buffer上。下面介绍这种方式下该如何配置MTLVertexDescriptor以及两种方式的区别和目的是什么。
介绍两种方式的区别之前先引入OpenGL中的两个概念:SOA和AOS。

看到图示应该很容易理解,AOS(Array Of Structure)就是我们上面例子中MTLVertexDescriptor的组织方式了,同一个顶点的所有属性在同一个buffer依次排列存储,然后继续排列存储下一个顶点数据,如此类推,这样的好处是符合面向对象的布局思路。而SOA(Structure Of Array)是AOS的一个变换,不同于之前一些属性结构的集合组成的结构数组,现在我们有一个结构来包含多个数组,每个数组只包含一个属性,这样GPU可以使用同一个index索引去读取每个数组中的属性,GPU读取比较整齐,这种方法对于某一些3D文件格式尤其合适。
再放一个国外友人的解释:
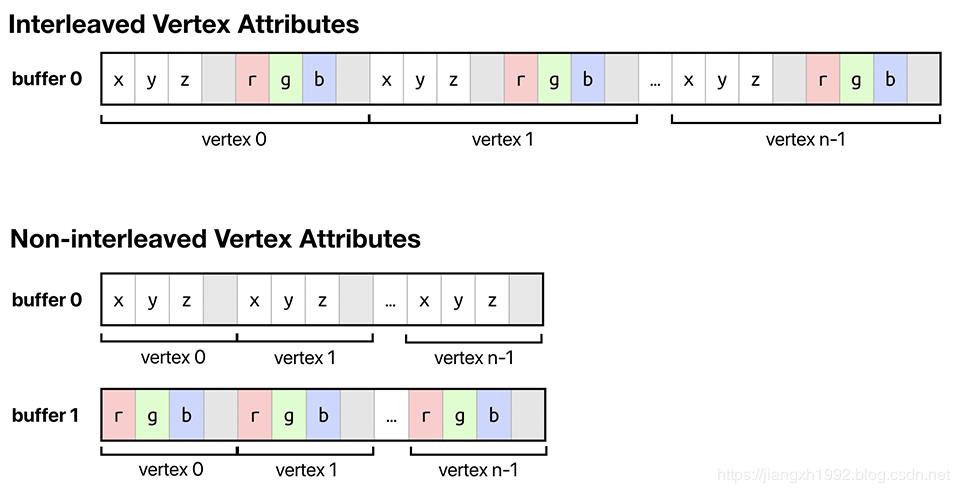
他解释这两种组织结构为重叠顶点属性和非重叠顶点属性。原理类似。
理解了两种组织结构的原理,那么现在看在非重叠顶点属性的SOA组织结构下应该如何定义和配置我们的MTLVertexDescriptor对象:
vertexDescriptor = [[MTLVertexDescriptor alloc] init];
// Positions.
vertexDescriptor.attributes[0].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[0].offset = 0;
vertexDescriptor.attributes[0].bufferIndex = 0;
// Texture coordinates.
vertexDescriptor.attributes[1].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[1].offset = 0;
vertexDescriptor.attributes[1].bufferIndex = 1;
// Position Buffer Layout
vertexDescriptor.layouts[0].stride = 8;
vertexDescriptor.layouts[0].stepRate = 1;
vertexDescriptor.layouts[0].stepFunction = MTLVertexStepFunctionPerVertex;
vertexDescriptor.layouts[1].stride = 8;
vertexDescriptor.layouts[1].stepRate = 1;
vertexDescriptor.layouts[1].stepFunction = MTLVertexStepFunctionPerVertex;
可见由于我们的顶点有两个属性,因此我们可以将顶点数据放到两个buffer上,一个保存position数据,一个保存uv数据。因此这里MTLVertexDescriptor对象的layouts需要定义两个,分别对应两个buffer,每个属性有2个float数据,因此GPU取数据的stride步长都为8。另外现在每个属性占用一个buffer,所以attributes的offset都为0了。
在着色函数中接收并使用顶点数据
上面介绍中GPU已经取到了数据,现在我们要在着色函数中进行接收。无论是采用的上面的哪种数据组织方式,对于在着色函数中的数据接收都是一样的,组织结构不同只是GPU取数据和存储数据方式不同而已。
根据顶点数据结构,在shader中定义的顶点属性结构应该如下:
struct Vertex
float2 pos [[attribute(0)]];
float2 uv [[attribute(1)]];
;
可见数据是通过[[attribute(id)]]属性映射的,属性的命名无所谓,这样pos属性和uv属性就映射到了shader中的这两个属性变量中。并在vertex function中以属性参数[[stage_in]]自动传送给着色函数内部:
vertex VSOutput vertexMain(Vertex input [[stage_in]])
// ...
注意[[stage_in]]是自动接收来自buffer(0)的顶点数据的,因此这种方式下CPU中要将顶点数据传给buffer(0)。
2.2.3 Argument Tables传送数据
除了顶点数据,我们还需要往shader中传送一些其他数据资源,例如:材质、其他数据缓冲、采样器等等。这些数据是可以直接调用renderEncoder的API往里面传送的。
Argument Tables就是各种资源的列表,每个vertex function和fragment function都对应一个这样的资源列表,通过setVertexBuffer,setFragmentBuffer,setFragmentTexture等函数传入。
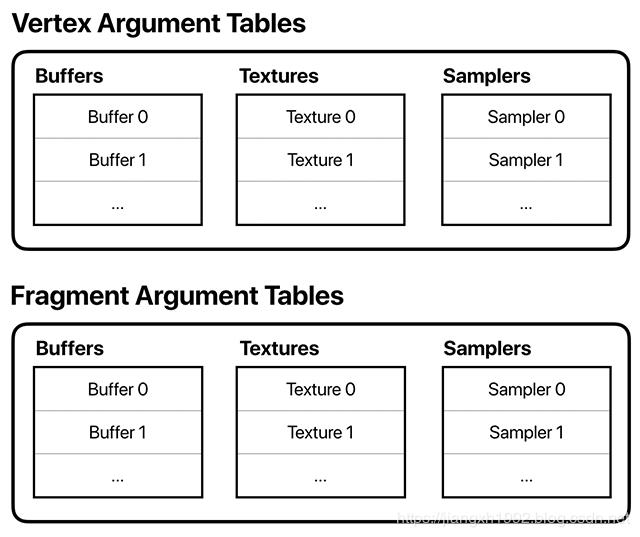
table中buffer、texture、sampler的数量取决于硬件设备,但是开发中可以认为至少可以传入31个buffer和texture,和16个sampler。
了解了Argument Tables后现在介绍第二种往着色函数传送顶点数据的方式,即通过setBuffer将顶点数据以普通资源的方式传给vertex function,并根据vertex_id手动定位当前的顶点数据。
这总方式下就不需要定义和使用MTLVertexDescriptor对象了。模型数据结构的定义要和模型中的数据对应好,然后同样拷贝到MTLTBuffer中,然后将要绘制时使用renderEncoder传入buffer:
[_myRenderEncoder setVertexBuffer:_quadBuffer offset:0 atIndex:0]; // 这里atIndex参数不一定为0,只要在shader vertex function中对应好即可
shader中在vertex function接收顶点数组:
vertex VSOutput vertexQuadMain(uint vertexID [[ vertex_id]],
constant AAPLVertex *vertexAttr [[buffer(0)]])
VSOutput out;
out.pos = float4(vertexArr[vertexID].position,0.0,1.0);
out.texcoord = vertexArr[vertexID].uv;
return out;
可见在此之前的教程中我们是使用了第二种传送顶点数据的方式,现在则可以使用MTLVertexDescriptor来配置顶点数据流,进行数据的传输和映射。
三、源码分析
3.1 Render.m
vertexDescriptor = [[MTLVertexDescriptor alloc] init];
// pos
vertexDescriptor.attributes[0].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[0].offset = 0;
vertexDescriptor.attributes[0].bufferIndex = 0;
// uv
vertexDescriptor.attributes[1].format = MTLVertexFormatFloat2;
vertexDescriptor.attributes[1].offset = 8;
vertexDescriptor.attributes[1].bufferIndex = 0;
// layout
vertexDescriptor.layouts[0].stride = 16;
vertexDescriptor.layouts[0].stepRate = 1;
vertexDescriptor.layouts[0].stepFunction = MTLVertexStepFunctionPerVertex;
// ...
pipelineStateDescriptor.vertexDescriptor = vertexDescriptor;
相比于之前的demo,我们添加了一个自定义的vertexDescriptor,并设置到了pipelineStateDescriptor上面。
[renderEncoder setVertexBuffer:vertexBuffer offset:0 atIndex:0];
还是和之前一样设置顶点buffer,但是这里的bufferIndex默认必须为0。
3.2 着色器
vertex ColorInOut vertexShader(VertexAttr in [[stage_in]])
ColorInOut out;
float4 position = vector_float4(in.pos, 0 , 1.0);
out.position = position;
out.texCoord = in.uv;
return out;
着色器代码我们只修改了顶点着色函数,[[stage_in]]语义绑定接受我们使用MTLVertexDescriptor配置的顶点数据流,这里传进来的就是当前顶点的数据,不再是完整的顶点数组。其他代码没有更改。
四、运行效果
在教程二的基础上这里Demo中改用了MTLVertexDescriptor来映射顶点数据流,得到同样的效果。

以上是关于一步步学Metal图形引擎3-《MTLVertexDescriptor》的主要内容,如果未能解决你的问题,请参考以下文章