总结
Posted alruddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了总结相关的知识,希望对你有一定的参考价值。
[toc]
计算机软件体系结构
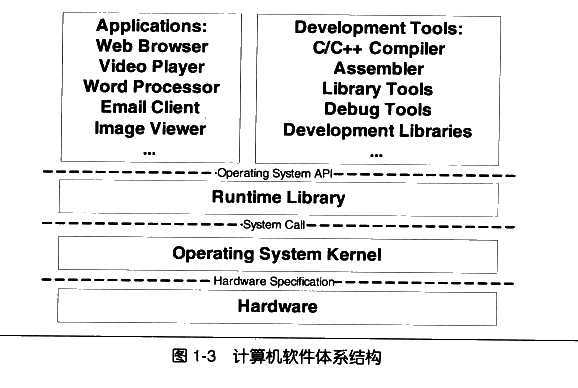
每个层次之间的通信的协议叫做接口(Interface)。
开发工具和应用程序在同一层,称之为操作系统应用程序接口(API: Application Programming Interface)。API由运行库来提供,什么样的运行库提供什么样的API。Linux下的glibc提供POSIX的API, Windows提供Windows的API。
运行库使用操作系统提供的系统调用接口。系统调用常常使用软件中断来实现。Linux常常使用0x80号中断。
操作系统的硬件接口的使用者,操作系统与硬件进行通信的协议称之为硬件规格。
操作系统
操作系统的官方解释:操作系统 是一组控制和管理计算机系统中所有资源的程序的集合。
操作系统的功能:
处理机(CPU)管理
单道程序、 多道程序调度
因为CPU处理速度与I/O速度的极大差距,所以产生了多种CPU调度方式,比如分时系统,多任务系统。
存储管理
设备管理
文件管理
网络管理
内存问题
程序简单装入内存: 分配连续的程序需要的全部的物理内存。
例如: PA 需要内存10M, PB需要内存100M, PC需要20M
将前10M分配给A, 10~110M分配给B,这样可以同时运行。
存在问题:
- 地址空间不隔离
- 内存使用效率低
- 程序运行地址不确定
解决办法:
分段: 设置虚拟地址机制,将程序的段通过映射函数映射到物理内存中 - 分段优点: 分段解决了地址空间不隔离,和程序运行地址重定位的问题,他通过映射使得物理地址对于程序来说的透明的
- 分段存在问题:但是并没有解决内存使用效率低的问题,因为大块内存的出现会使得出现类似内存碎片得东西。
分页:使用更小得粒度来进行内存分割和映射。
一般来说,4KB作为页大小。
线程和进程
线程定义
线程, 轻量级进程, 是程序执行流的最小单元。由线程ID,当前指令指针、寄存器集合和堆栈组成。
进程和线程之间的关系
一个进程由一个或者多个线程组成,各个线程之间共享进程级资源(打开的文件或者信号)和程序的内存空间(代码段、数据段、堆)。
为什么使用多线程:
- 单线程存在阻塞等待,利用多线程来避免,利用等待时间进行其他操作
- 逻辑本身要求多线程,多段通信下载
- 多核计算机成为单线程程序的效率上限
数据共享方面的优势
线程的访问权限

线程调度
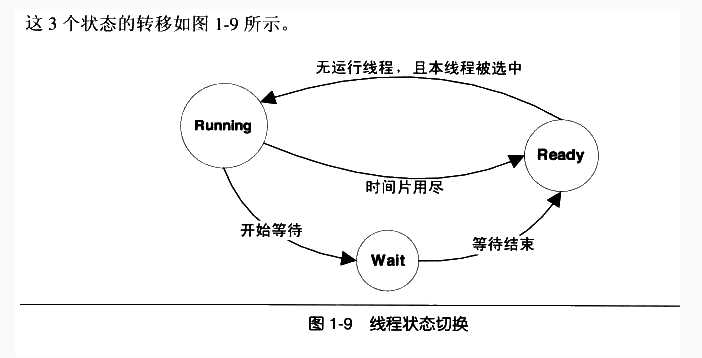
线程调度方式: 优先级调度、轮转法
优先级调度中的几个概念:
频繁等待的线程称为IO密集型线程
很少等待的线程称为CPU密集型线程
一般来说,IO密集型的线程的优先级较之CPU密集型的线程的优先级要高。
线程优先级变更的方式:
- 用户使用函数来进行指定setThreadPriority
- 根据进入等待状态的频繁程度来进行优先级的提升和降低
- 长时间得不到执行而提升
可抢占线程和不可抢占线程
所谓抢占就是在某个线程在时间片没有用完的前提下,强制从执行状态进入就绪状态。
不可抢占线程中也有线程主动放弃执行的情况:
- 主动放弃时间片
- 试图等待某事件发生的时候
Linux的多线程
不同于Windows系统, Linux系统对于多线程的支持并不是那么完善。
Linux对于每一个执行实体都称之为任务,这是一个单线程的进程,具有内存空间,执行实体。
具有着共享同一个内存空间的多任务构成了一个进程,这些任务也就成了进程的线程。
Linux创建线程的方式:
fork()函数产生一个与当前进程一样的新进程,产生的新进程与主进程之间共享着写时复制的内存空间。
exec()系列函数是使用一个新的可执行文件映像。
利用fork产生新进程,然后再新进程中使用exec来产生新任务。
还有一个函数是clone(),产生新任务,并从指定位置执行,可以继承父进程的某些可选资源。
线程安全
多进程中对于非原子性操作,出现操作竞争,会出现重复写入,延迟读的情况。
原子性操作: 对于CPU来说是单指令操作。
提高线程安全性的方法:
- 使用操作系统提供的原子性的操作
- 使用同步和锁机制
同步和锁
同步(synchronization): 在当前进程没有完成数据访问之前,其他线程不能够对该数据进行访问。
锁(Lock): 在访问资源之前首先试图获得锁,在访问结束后释放锁。如果在访问之前获得锁失败,线程会等待,直到锁重新可用。
常见的锁:
二元信号量: 只有两种状态, 占用和非占用。
多元信号量: n元信号量,如果获得该锁后,信号量减一, 释放锁后,信号量加一,当信号量为负数时就进入等待状态。
互斥量(mutex) 与二元信号量很像。但是不同的是,信号量可以有其他线程获取并释放。但是互斥量要求哪个线程获得的互斥量,哪个线程就需要释放, 其他线程无法释放。
临界区 比互斥量更加严格的手段。与互斥量的区别是:临界区的范围仅仅限制与本进程,其他进程无法获得该锁。
读写锁 对某一个资源的锁有两种共享S锁和都独占X锁

可重入的概念:
过度优化问题:编译器对于程序的优化,使得并不能让程序按照我们想象的方式来进行。
例如单例模式:
volatile T *pInst = 0;
T *getInstance() {
if (pInst == NULL) {
lock();
if (pInst == NULL) {
pInst = new T;
}
unlock();
}
return pInst;
}这个单例模式其实是有问题的,问题来源与CPU乱序执行。
C++中new包含两个步骤:
- 分配内存
- 调用构造函数
所以那个pInst=new T;包含三个步骤: - 分配内存
- 调用构造函数
将内存首地址赋值给pInst
其中第二步和第三步是可以颠倒顺序的。
线程A 在先给pInst赋值后并没有完成构造,线程B这个时候调用getInstance会返回一个没有构造完成的T给用户使用。
解决办法:#define barrier() __asm__ volatile ("lwsync") volatile T *pInst = 0; T *getInstance() { if (pInst == NULL) { lock(); if (pInst == NULL) { T *temp = new T; barrier(); pInst = temp; } unlock(); } return pInst; }
三种线程模型
- 一对一,每一个用户态的线程都对应一个内核里的线程,反之不成立
- 多对一, 多个用户态的线程对应一个内核里的线程, 存在问题:如果一个用户态线程阻塞,那么对应于同一内核线程的所有用户态线程都会阻塞。
- 多对多, 以上两种方式的结合,利用调度算法, 效率上不如一对一。
以上是关于总结的主要内容,如果未能解决你的问题,请参考以下文章