pandas一些常用函数以及操作的使用和理解(持续更新)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas一些常用函数以及操作的使用和理解(持续更新)相关的知识,希望对你有一定的参考价值。
pandas库的一些用法
- 1.创建DataFrame(下面都缩写为df)
- 2.df.columns(更改列名)
- 3.df[]列索引、df.loc[]行索引、df.iloc[]、df[]布尔索引、df.at[行索引, 列索引]
- 4.pd.read_csv()、df.to_csv()
- 5.df.sort_value()
- 6.df.describe()
- 7.df.applymap(), df.astype()数据类型转换
- 8.df.列名.str.split(分隔符,expand=True)、df.groupby().size()
- 9.df.drop()
- 10.df.dropna()
- 10.df.apply() (无敌神器)
- 11.df.isnull()
- 12.df.value_counts()
- 13.df.append()用于df增加一行
- 14.df.drop_duplicates()删除重复数据
- 15.df.groupyby()分组处理数据
- 16.遍历df(df.iterrows())
- 17.dataframe.groupy和agg的配合使用进行特征衍生
- 18.pd.get_dummies
- 19.series.str.contains()
1.创建DataFrame(下面都缩写为df)
import pandas as pd
import numpy as np
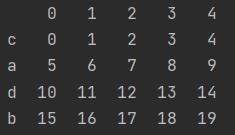
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
print(f)
结果
2.df.columns(更改列名)
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
print(f)
结果

3.df[]列索引、df.loc[]行索引、df.iloc[]、df[]布尔索引、df.at[行索引, 列索引]
列索引和行索引
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
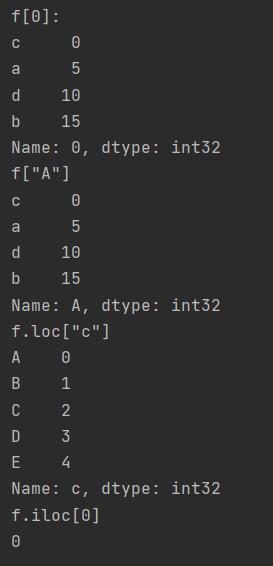
print("f[0]:")
print(f[0])
f.columns = ["A", "B", "C", "D", "E"]
print('f["A"]')
print(f["A"])
print('f.loc["c"]')
print(f.loc["c"]) # 用列名行名取
print('f.iloc[0]')
print(f.iloc[0][0]) # 用index取
结果
布尔索引
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
print(f[f["A"] % 10 == 5]) # 选择A列值mod 10 = 5的数据
结果

取出除第一列的所有列
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
print(f)
f = f.loc[:, list(f.columns)[1:]]
print(f)
结果

df.at能够进行特定位置赋值
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
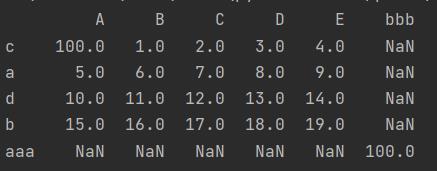
f.at["c", "A"] = 100
f.at["aaa", "bbb"] = 100
print(f)
结果
删除全为0的列
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
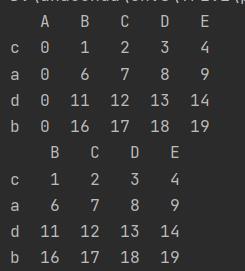
f.iloc[1][0] = 0
f.at["d", "A"] = 0
f.loc["b"]["A"] = 0
print(f)
f = f.loc[:, (f != 0).any(axis=0)]
print(f)
结果
4.pd.read_csv()、df.to_csv()
读存取csv文件,十分方便
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f.to_csv("a.csv", index=0, encoding="utf-8") # 行索引不保存
# f.to_csv("a.csv", encoding="utf_8_sig") # 这个保存用excel打开中文不会乱码
ff = pd.read_csv("a.csv", encoding="utf-8", sep=",") # 默认就是逗号相隔,sep="\\t"就可以读tsv了
print(ff)
csv文件

5.df.sort_value()
对列值进行排序,ascending=False表示降序排
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f.iloc[0][1] = 20
f = f.sort_values(by=["A", "B"], ascending=False) # 首先按A列降序,其次按B列降序
print(f)
结果

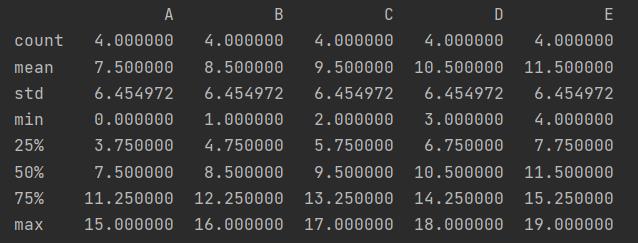
6.df.describe()
用于计算一些常用的统计数
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f = f.describe()
print(f)
结果
7.df.applymap(), df.astype()数据类型转换
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
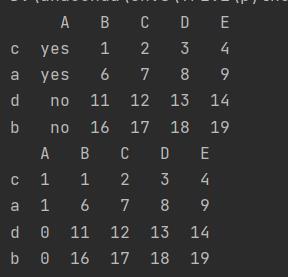
f = f.applymap(str) # 全部转换为字符型
f.iloc[0][0] = "Yes"
f.iloc[1][0] = "yES"
f.iloc[2][0] = "No"
f.iloc[3][0] = "nO"
f["A"] = f["A"].str.lower() # 全都转换成小写
print(f)
f["A"] = (f["A"] == "yes").astype("int") # yes为1,其他为0
print(f)
结果
8.df.列名.str.split(分隔符,expand=True)、df.groupby().size()
拆列成多列、分组求和
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f = f.applymap(str) # 全部转换为字符型
f.iloc[0][0] = "浙江 嘉兴"
f.iloc[1][0] = "浙江 杭州"
f.iloc[2][0] = "福建 泉州"
f.iloc[3][0] = "浙江 温州"
print(f)
print("-------------")
shen_shi = f.A.str.split(" ", expand=True) # 以空格切分
print(shen_shi)
print("------------")
group_by = shen_shi.groupby(shen_shi[0]).size()
print(group_by)
结果

9.df.drop()
删除某列数据
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f = f.drop(columns=["A"])
print(f)
结果

10.df.dropna()
删除含有缺失值的列
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f.at["e", "A"] = 0
print(f)
f = f.dropna()
print(f)
结果

10.df.apply() (无敌神器)
apply函数可以说是最灵活的函数了,我感觉是相干啥都行,只要你能写出对于操作的函数就可以
import pandas as pd
import numpy as np
import re
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f = f.applymap(str) # 全部转换为字符型
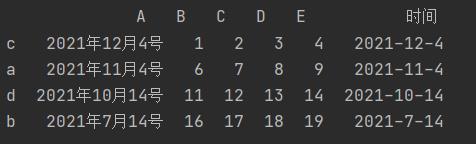
f.iloc[0][0] = "2021年12月4号"
f.iloc[1][0] = "2021年11月4号"
f.iloc[2][0] = "2021年10月14号"
f.iloc[3][0] = "2021年7月14号"
f["时间"] = f.apply(lambda x: "-".join([t for t in re.findall(r"(.*)年(.*)月(.*)号", x[0])[0]]), axis=1)
print(f)
这个示例的思想就是先通过re正则表达式将A列中的时间(年、月、日各自提取出来 即re.findall(r"(.)年(.)月(.*)号", x[0], x[0]就代表是这一行的第一个元素,因为后面axis=1表示对每行各自进行操作),时间提取出来之后在用-连接起来,形成一个新的时间,最后赋值给时间那列。
运行结果
这里有一些小细节值得注意,如果是对Dataframe进行apply操作那么,Dataframe.apply(lambda x:fun(x[col_name]), axis=1)也是可以的,即可以用x[0…]来索引对应数值也可以用对应列名来索引,但是如果Series使用时,例如df[col].apply(lambda x:fun(x[0]), axis=1)就是不正确的,因为这里已经确定传入是指定的列了,df[col].apply(lambda x:fun(x), axis=1)这样才能运行成功。
11.df.isnull()
查找缺失值
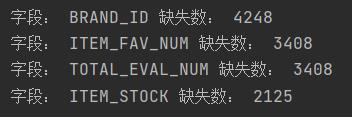
下面以tsv文件为例写了一个检查缺失情况的函数,只需要把tsv的文件名输入就可展示缺失字段以及数量。
def check(file):
f = pd.read_csv(file, sep="\\t", encoding="utf-8")
col = f.columns
null_col = [] # 有缺失值的列
for c in col:
if len(f[f[c].isnull()][c]) != 0:
null_col.append(c)
print("字段:", c, "缺失数:", len(f[f[c].isnull()][c]))
file = "文件名"
check(file)
我自己随便一个文件的运行结果
# 查看数据每一行的缺失值个数的频次
f.isnull().sum(axis=1).value_counts()
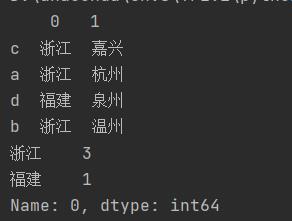
12.df.value_counts()
用于查看数据的频次分布
df.value_counts(normalize=True)能够查看相对频率(概率密度)
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=["c", "a", "d", "b"])
f.columns = ["A", "B", "C", "D", "E"]
f = f.applymap(str) # 全部转换为字符型
f.iloc[0][0] = "浙江 嘉兴"
f.iloc[1][0] = "浙江 杭州"
f.iloc[2][0] = "福建 泉州"
f.iloc[3][0] = "浙江 温州"
shen_shi = f.A.str.split(" ", expand=True) # 以空格切分
print(shen_shi)
print(shen_shi[0].value_counts())
结果
13.df.append()用于df增加一行
import pandas as pd
f = pd.DataFrame()
t = pd.Series([5, 2, 5, 5])
f = f.append(t, ignore_index=True)
print(f)
结果

14.df.drop_duplicates()删除重复数据
import pandas as pd
import numpy as np
f = pd.DataFrame(np.arange(20).reshape(4, 5), index=