论文阅读|浅读RolX: Structural Role Extraction & Mining in Large Graphs
Posted 海轰Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|浅读RolX: Structural Role Extraction & Mining in Large Graphs相关的知识,希望对你有一定的参考价值。
目录
- 前言
- 简介
- ABSTRACT
- 1. INTRODUCTION
- 2. PROPOSED METHOD
- 3. ROLE GENERALIZATION / TRANSFERLEARNING
- 4. STRUCTURAL SIMILARITY
- 5. SENSE-MAKING
- 6. RELATED WORK
- 读后总结
- 结语

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
知其然 知其所以然!
本文仅记录自己感兴趣的内容
简介
原文链接:https://dl.acm.org/doi/10.1145/2339530.2339723
会议:KDD '12: Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining (CCF A类)
年度:2012/08/12
ABSTRACT
给定一个网络,如果两个节点具有相似的结构行为,则直觉上它们属于同一角色
角色应该从数据中自动确定,并且可以是例如“集团成员”、“外围节点”等
角色使许多新颖和有用的网络挖掘任务成为可能,例如意义形成、搜索相似节点和对节点进行分类
本文解决的问题是:给定一个图,我们如何自动发现节点的角色?
我们提出了RolX(角色提取),这是一种可伸缩的(在边数中线性的)无监督学习方法,用于从一般网络数据中自动提取结构角色
我们展示了RolX在几种网络挖掘任务上的效率:从探索性数据分析到网络迁移学习
此外,我们比较了网络角色发现和网络社区发现,强调了两者之间的根本区别(例如,角色在不连通的网络上泛化,而社区不是)
并表明这两种方法本质上是互补的
1. INTRODUCTION
给定一个网络,我们希望通过角色自动捕获节点的结构行为(或功能)
可能的角色包括:明星中心、集团成员、外围节点等
为此,我们提出了一种新的方法,称为RolX(角色提取),它自动地、直接地总结大图中节点的行为
更准确地说,RolX实现了以下两个目标
- 首先,在不知道可能存在的角色种类的情况下,它自动确定网络中的底层角色
- 其次,它适当地将这些角色的混合成员分配给网络中的每个节点
RolX很重要,因为它的角色构成了许多新颖和有趣的网络数据分析任务的基础,例如网络迁移学习、测量结构相似性、意义形成(即理解网络中的潜在行为)和网络可视化
例如,给定两个来自企业网络的IP通信图,我们可以使用一个图中提取的角色来构建一个关系分类器,用于在另一个图中执行分类任务,即在图上执行跨网络分类或迁移学习
RolX是一种无监督的学习方法,用于从一般网络数据集中自动提取结构角色
通过大量的实验,我们证明了派生的角色在探索性数据分析任务(如意义构建和节点相似性)和预测任务(如跨网络迁移学习)中是有效的
在后一种情况下,我们使用角色跨网络泛化行为的能力作为一种执行网络学习的方式,而不依赖同质性或目标图中类别标签的可用性
在我们的框架中,角色是由结构特征派生的
在缺乏任何其他信息的情况下,从网络数据集中提取角色的问题是模糊定义的,因为可以从数据中派生出无限数量的结构特征
一旦我们选择了一组这样的特征,角色提取的问题就可以很好地表达出来
在给定数据集的一组结构特征的情况下,我们将角色提取问题定义为
- (1)在该结构特征空间中寻找基础向量(其中基础向量的数量由模型选择来确定)
- (2)确定每个网络节点属于每个角色的多少
用于角色提取的结构特征是域相关的
例如,对于社交网络,我们提出了一组符合社会学家领域知识的结构特征
我们的工作贡献如下:
- 有效性:RolX支持多种图形挖掘任务,包括
- 角色泛化/迁移学习:RolX的结构角色在不连续的网络中泛化
- 结构相似性:RolX提供了一种通过比较节点的角色分布来确定节点之间相似性的自然方法
- 意义形成:通过总结它们的特征(NodeSense)和它们的邻居(NeighborSense),可以直观地理解RolX的结构角色
- 自动化:RolX经过精心设计,完全自动化,无需用户指定的参数
- 可伸缩性:RolX的运行时复杂性与边数呈线性关系
我们要强调的是,RolX作为一种角色发现方法从根本上不同于(和补充)社区检测:
- 前者将行为相似的节点分组
- 后者将彼此连接良好的节点分组
图1描述了加权合作网络的最大连接部分的角色发现和社区发现之间的差异[25]

角色发现和社区发现是网络分析的互补方法
- 左:RolX在网络科学作者图最大的连接组件上发现的4个角色:“桥”节点(红色钻石),“主流”节点(灰色方块)
- 右:Fast module[6]在同一个合著图上发现的22个社区
角色捕获节点级的行为并跨网络一般化,而社区不能
RolX自动发现4个角色,而不是流行的快速模块化[6]社区发现算法发现的22个社区
- RolX是一种混合成员方法,它为每个节点分配一个在已发现的结构化角色集上的分布
- RolX的节点颜色对应于节点的主要角色,而Fast模块化的节点颜色对应于节点的社区
我们发现的四个角色代表了这些行为:
- “桥”节点(红色方块)代表中心作者和多产作者
- “主流”节点(灰色正方形)代表桥节点的邻域
- “病态”节点(绿色三角形)代表较高权重的边缘作者
- 以及“紧密”节点(蓝色圆圈)代表有许多合著者和友善的邻居的作者
2. PROPOSED METHOD
在给定网络的情况下,RolX的目标是自动发现一组潜在的(潜在)角色
这些角色总结了网络中节点的结构行为
RolX由三个部分组成
- 特征提取
- 特征分组
- 模型选择
2.1 Feature Extraction
在其第一步中,RolX将每个节点描述为特征向量
节点特征的例子有节点的邻域数目、节点参与的三角形数目等
RolX可以使用任何一组被认为重要的特征
在从图中提取特征的众多选择中,我们选择了[15]中描述的结构特征发现算法(Refex),因为它是可伸缩的,并且在许多任务中表现出了良好的性能
- 对于给定的节点 V V V,它基于与 V V V相邻的链路的计数(加权的和未加权的)来提取本地和EFONET特征
- 并且它还以递归的方式聚集基于EFONET的特征,直到不能添加信息性特征
- 这些递归特征的例子包括网内边的度和数目,以及诸如“平均邻接度”和“最大邻接度”之类的集合
另外,RolX在特征发现算法方面是灵活的,因此RolX的主要结果也适用于其他结构特征提取技术
2.2 Feature Grouping
在特征提取之后,我们有 n n n个向量(每个节点一个),每个向量包含 f f f个数字条目
我们应该如何创建具有相似结构行为/功能的节点组?
我们如何才能使其完全自动化,而不需要用户输入?
我们建议在结构特征空间中使用软聚类(其中每个节点在不同发现的角色之间具有混合成员资格)
具体地说,是矩阵因式分解的自动版本
给定节点特征矩阵 V n × f V_n \\times f Vn×f,RolX算法的下一步是生成rank r r r近似 G F ≈ V GF \\approx V GF≈V,
- 其中 G n × r G_n\\times r Gn×r的每一行表示每个角色中的节点的成员资格
- 并且 F r × f F_r\\times f Fr×f的每一列指定特定角色中的成员资格如何对估计的特征值做出贡献
有许多方法来生成这种近似(例如,SVD、谱分解),并且RolX不依赖于任何特定的方法
在这项研究中,我们使用非负矩阵因式分解(NMF)
因为它是公认的,非负因素简化了对角色和成员关系的解释
形式上,我们寻找两个非负的低秩阵
G
G
G和
F
F
F来满足:
a
r
g
m
i
n
G
,
F
∣
∣
V
−
G
F
∣
∣
f
r
o
s
.
t
.
G
≥
0
,
F
≥
0
argmin_G,F||V-GF||_fro\\quad s.t. G \\geq 0, F \\geq 0
argminG,F∣∣V−GF∣∣fros.t.G≥0,F≥0
其中
- ∣ ∣ ⋅ ∣ ∣ f r o ||·||_fro ∣∣⋅∣∣fro是Frobenius范数
非负约束通常导致原始数据集的稀疏、基于部分的表示,这通常比其他因式分解方法在语义上更有意义
虽然由于目标函数的非凸性,很难找到矩阵的最优分解,但有几种有效的近似算法(例如,乘法更新[18]和投影梯度下降[20])
RolX使用乘性更新,因为它很简单
值得指出的是,RolX可以自然地包含矩阵因式分解的其他变量,例如通过在目标函数中包含一些正则化项来对F和/或G施加稀疏约束
RolX还可以使用一般的Bregman散度[8]来衡量近似精度,而不是使用Frobenius范数
这使得RolX能够使用在某些情况下可能更合适的其他散度函数(例如,KL散度)
特征分组算法的一个实际问题是必须预先指定模型大小(即角色的数量)
一般来说,期望从业者为该参数手动选择适当的值是不现实的
因此,我们探索了几种自动模型选择的方法
2.3 Automating the Method: Model Selection
由于角色总结了行为,因此可以使用它们来压缩特征矩阵 V V V
我们建议使用最小描述长度准则[27]来选择产生最佳压缩的模型大小 r r r
对于给定的模型,我们可以分两部分计算得到的描述长度:
- (1)描述模型本身所需的比特数
- (2)在 V − G F V-GF V−GF中描述重建错误的成本(以实现无损压缩)
选择的模型是使描述长度 L L L最小的模型,描述长度 L L L是模型描述成本 M M M和编码成本(通常是纠正模型错误的成本) E E E之和,即 L = M + E L=M+E L=M+E。
假设 G G G和 F F F不是稀疏的,则使用每值 b b b比特来描述模型的成本为 M = b r ( n + f ) M=br(n+f) M=br(n+f)
我们应该如何确定重建中纠正错误的表示成本?
也就是说,我们如何计算给定模型的对数似然?
从图2可以看出, V − G F V-GF V−GF的误差不是正态分布的
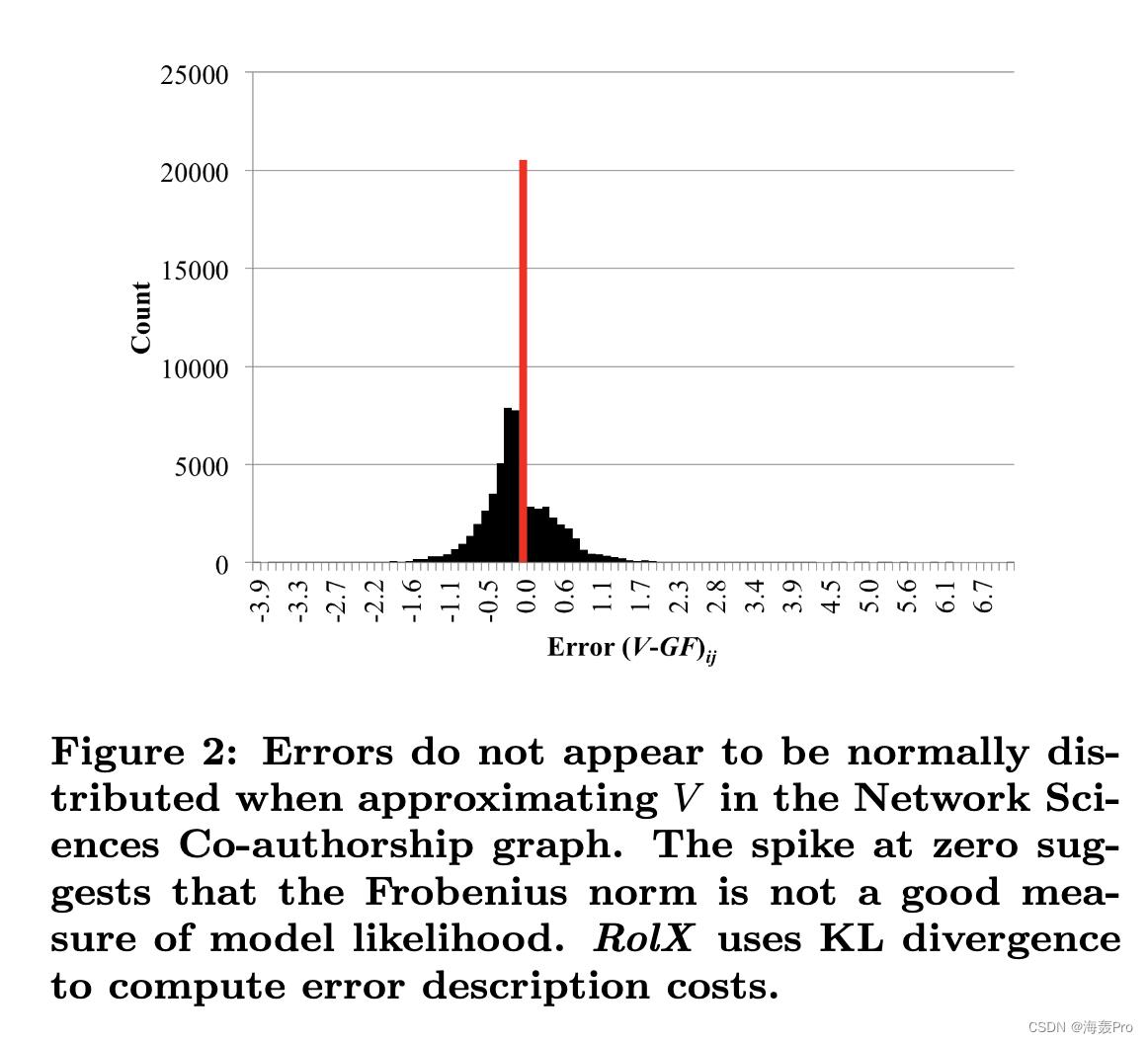
因此标准Frobenius范数是一个较差的选择
相反,我们用KL散度来计算误差描述代价:
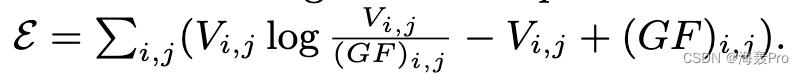
由于模型可以包含高精度的浮点值,我们将Lloyd-Max量化[22,21]与Human code[17]结合起来以增加压缩
注意,对于人工代码,编码模型的成本更改为 b ˉ r ( n + f ) \\bar br(n + f) bˉr(n+f),
- 其中 b ˉ \\bar b bˉ是每个值所需的平均位数
- 默认情况下,我们选择 l o g 2 ( n ) log_2 (n) log2(n)个量化箱
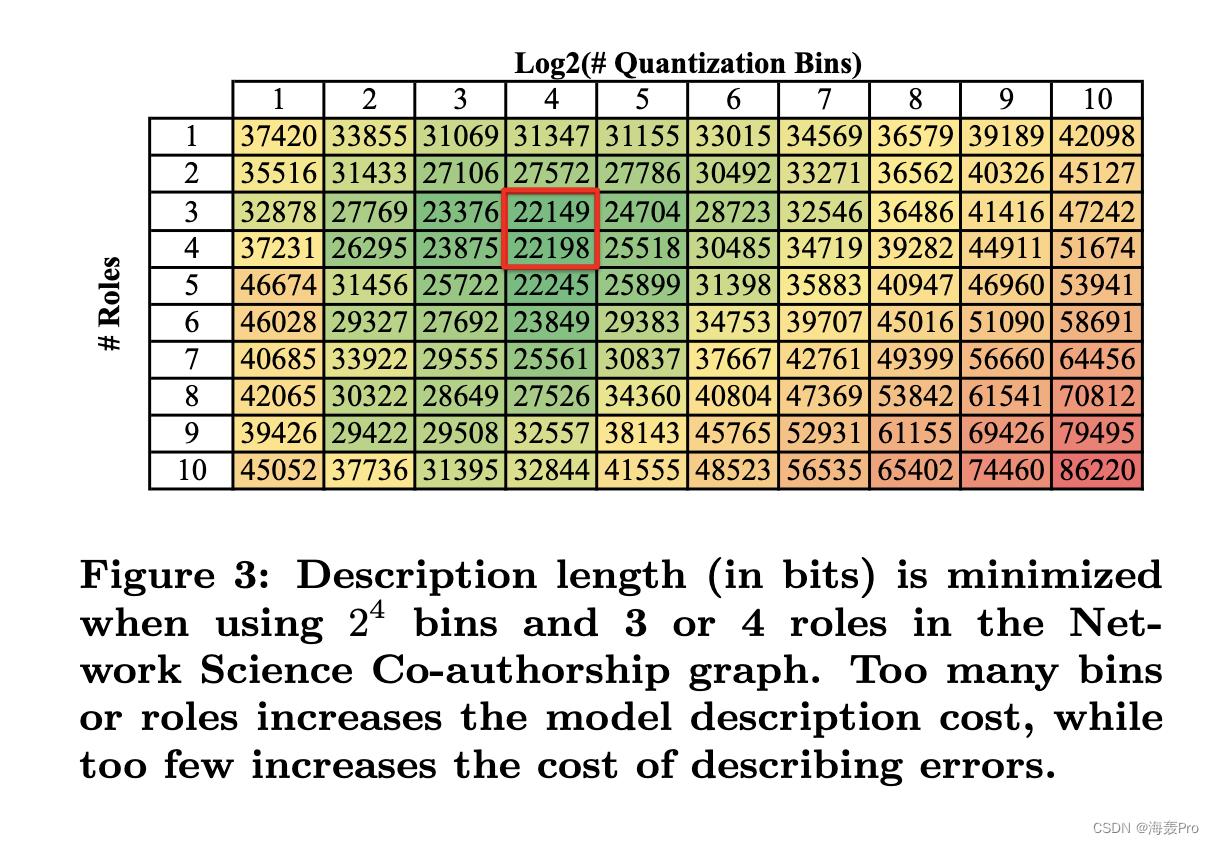
但是,可以通过选择描述长度最小的容器数量和角色的参数选择来选择容器的数量
图3显示,对于网络科学合著图(Network Science Co-authorship graph),当我们使用 2 4 = 16 2^4 = 16 24=16个量化桶和3或4个角色时,描述长度最小
2.4 Computational Complexity

2.5 Remarks
我们对聚类、模型大小标准和压缩的其他几个选项进行了实验
例如,Akaike (AIC)[1]提出的信息准则可以代替压缩
RolX可以使用任何其他矩阵分解方法作为drop- replacement,无论是通常的形式或稀疏对应(例如,[10])
类似地,压缩浮点数也有几种表示选择
我们尝试了许多这样的选择,但为了简单起见,我们省略了细节
因此,除非另有说明,RolX使用[15]中描述的特征提取算法,非负矩阵分解用于聚类,MDL用于模型选择, K L KL KL散度用于度量似然
3. ROLE GENERALIZATION / TRANSFERLEARNING
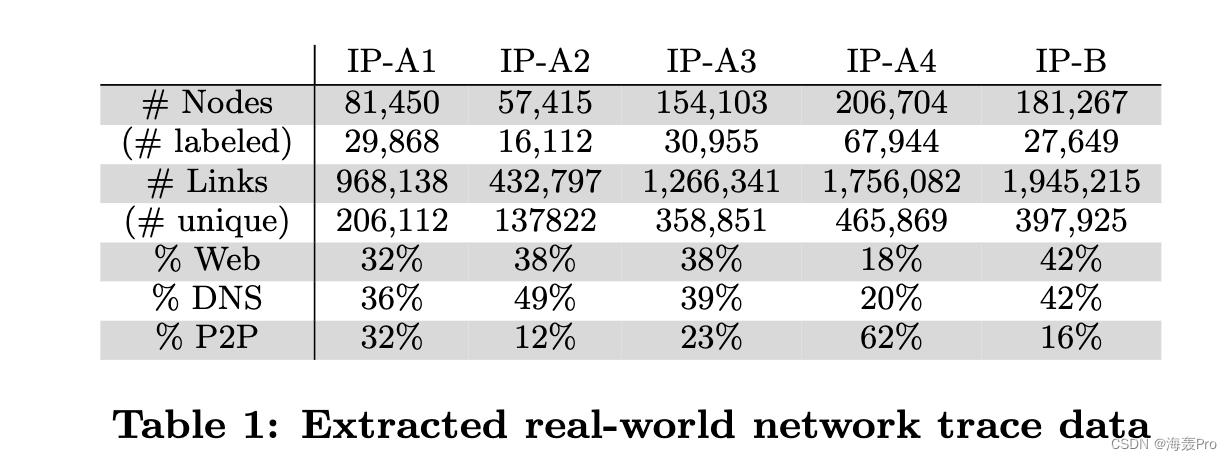
在本节中,我们提出跨网络分类任务(即网络迁移学习)的角色有效性实验。
数据,我们在两个真实的数据集上进行实验:IP通信网络和蓝牙邻近网络
- IP communication networks
- bluetooth proximitynetworks

4. STRUCTURAL SIMILARITY
…
5. SENSE-MAKING
…
6. RELATED WORK
相关研究可分为三个部分
- (1)图特征
- (2)角色发现
- (3)迁移学习
Graph Features
在一些数据挖掘任务中,已经从图中提取了特征
- 在[19]中,作者提出提取节点对的拓扑特征用于链路预测
- 在[14]中,作者开发了一个多层次的框架,基于图、子图和节点级特征来检测时变图中的异
- 他们的方法依赖于提取图形级(全局)特征,并随着时间的推移跟踪这些指标
- 在[2]中,作者提出了基于egonet的特征和模式从加权图中检测异常节点
- 利用局部和全局结构特征来提高网络分类器[12]的性能也有研究
- 一些特征提取的方法显式地保留了数据[4]中的多集群结构
- 我们的工作建立在递归特征提取方法[15]的基础上
Role discovery
我们建议使用递归图特征来发现节点的角色。角色发现的任务已经在不同类型的图中进行了研究(例如,社交网络工程[23])。
角色发现采用了不同的方法,包括贝叶斯框架使用MCMC采样算法学习多个角色的数据点[28],半监督语义角色标记[11]等
这些方法不能扩展到处理大型图。
在角色挖掘中还有另一组相关的工作,Molloy等人[24]对此做了一个很好的概述
角色挖掘与本文讨论的角色发现问题有所不同
它为访问控制系统中不同角色的不同用户解决了每个任务的访问
然而,角色挖掘算法使用类似于角色发现的技术来推断图中节点的角色(例如,分层聚类)。
除了使用推断角色进行探索图挖掘(例如结构相似性和意义构建任务),我们还使用推断角色改进分类
以前的方法包括使用簇结构来预测图[16]上的类标签,以及使用簇核来进行半监督分类
RolX是可伸缩的
RolX比一般用于社会网络分析的通用块建模[26]要简单得多, 具体来说,
- (1)RolX角色可以跨网络一般化
- (2) RolX具有可规模性
- (3) RolX除了常规等效性外,还合并了本地结构,并且在节点属性可用时原生支持它们
Transfer learning
我们工作的另一个方面是有效的图迁移学习
在图数据环境下,针对集体链路预测任务[5],提出了迁移学习的非参数模型
特征迁移的一般框架构造了一个图来表示源-目标迁移学习任务[7],而对于迁移学习[29]则探索了混合图的相似矩阵近似
为了提高聚类算法[3]的性能,也跨域转移了相关的监管
在所有现有的工作中,特性都是给定的,目标是利用给定的特性来提高目标领域的性能
读后总结
首先使用refex提取原图的特征矩阵 V V V
然后使用NMF分解矩阵 G F ≈ V GF \\approx V GF≈V
其中
- G : n × r G: n \\times r G:n×r
- F : r × f F: r \\times f F:r×f
分解前需要确定 r r r的大小
最小描述长度准则[27]来选择产生最佳压缩的模型大小 r r r
最后利用得到的 G G G和 F F F来进行实验
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

以上是关于论文阅读|浅读RolX: Structural Role Extraction & Mining in Large Graphs的主要内容,如果未能解决你的问题,请参考以下文章