数据系统分区设计 - 请求路由
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据系统分区设计 - 请求路由相关的知识,希望对你有一定的参考价值。
现已将数据集分布多个节点,但当客户端要发送请求时,如何知道应该连接哪个节点?若分区再平衡,分区和节点的映射也随之变化。
对此,需要有一段逻辑知晓这些变化并负责客户端的连接:如若我想读/写K “foo”,需连接哪个IP地址和端口号?
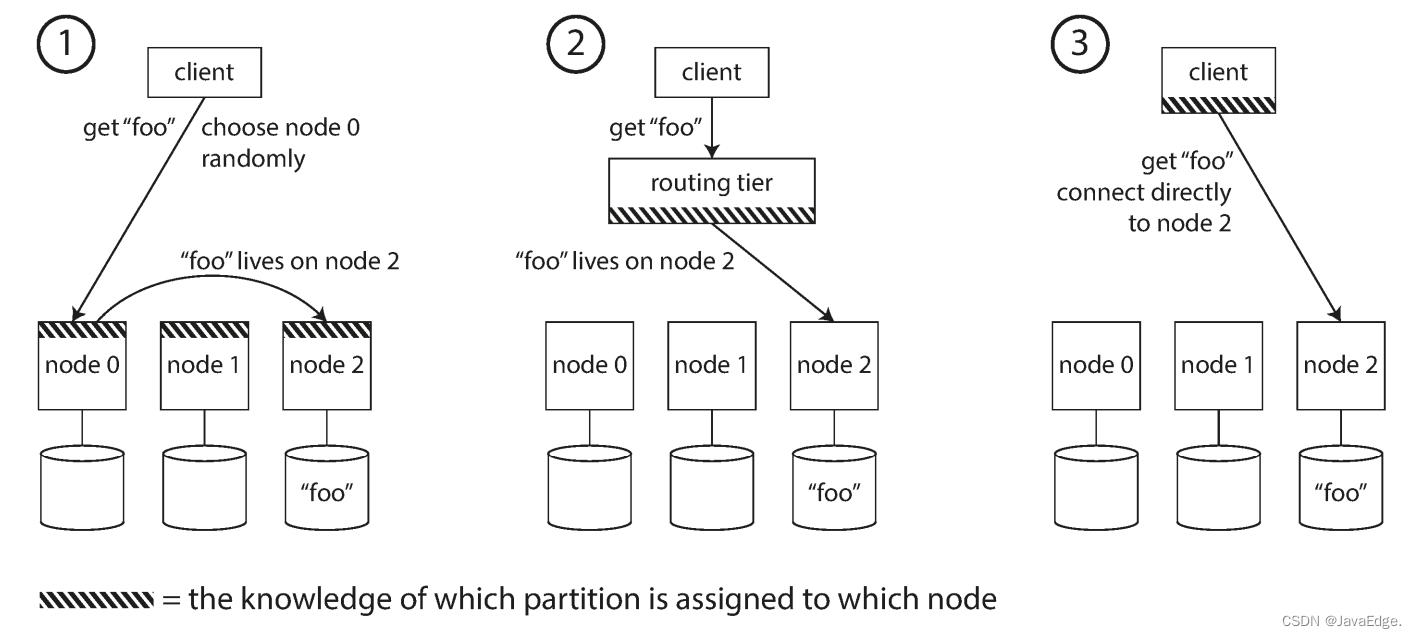
这其实就是服务发现,任何通过网络访问的系统都有此问题,特别是当其目标高可用(在多台机器上有冗余配置)。该问题有多种方案,如图-7:
- 允许客户端连接任一节点(如采用循环策略的负载均衡)。若该节点恰有请求的分区,则直接处理该请求;否则,将请求转发到下一个合适的节点,接收回复,并返回给客户端
- 将所有客户端请求都发送到路由层,负责将请求转发到对应分区节点。路由层本身不处理任何请求,仅负责分区的负载均衡
- 客户端感知分区和节点的分配关系。此时,客户端可直接连接到目标节点,而无需任何中介
不管啥方案,关键问题:作出路由决策的组件(可能是某个节点,路由层或客户端)如何知道分区和节点之间的对应关系及变化?
这是个有挑战的问题,所有参与者都要达成共识,否则请求可能被发送到错误节点。 在分布式系统的共识协议,通常都难以正确实现。
许多分布式数据系统依赖独立的协调服务(如zk),跟踪集群内的元数据,如图-8: 每个节点在zk中注册,zk维护分区到节点的映射关系。其他参与者(如路由层或分区感知的客户端)可以向zk订阅此信息。 一旦分区发生变化或添加、删除节点,zk就会主动通知路由层,使路由信息保持最新状态。
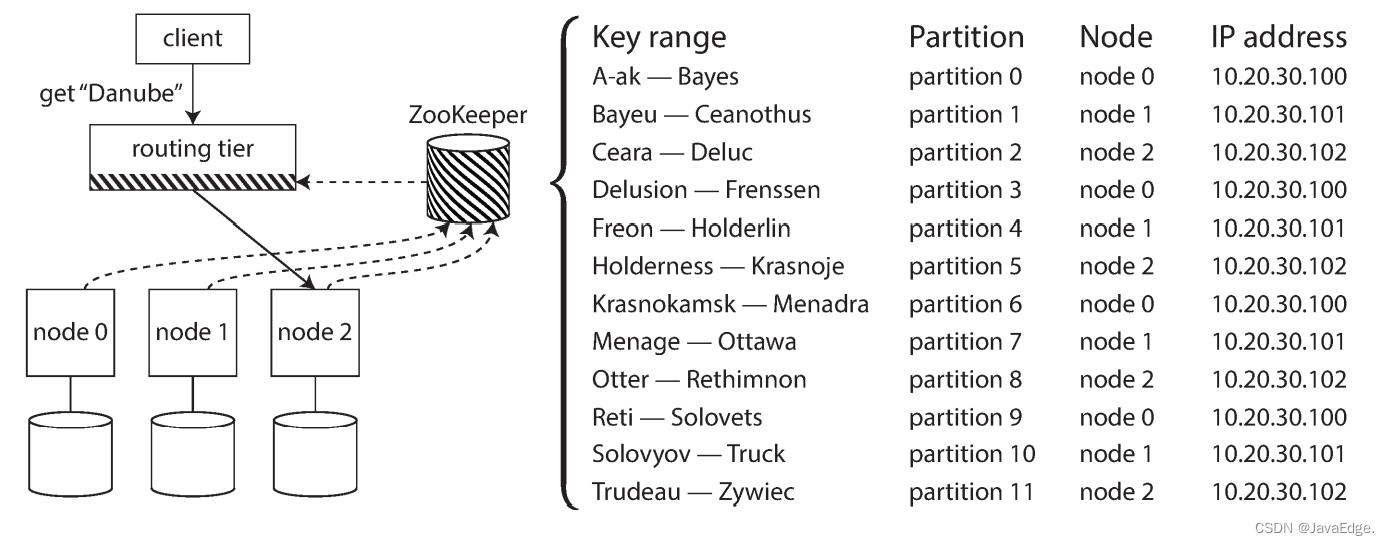
如LinkedIn的Espresso使用Helix进行集群管理(底层就是zk),实现如图-8所示的请求路由层。 HBase、Kafka也使用zk跟踪分区分配。MongoDB有类似设计,但它依赖自己的配置服务器(config server)实现和mongos守护进程作为路由层。
Cassandra采取不同方法:他在节点之间使用gossip协议同步集群状态的变化。请求可以发送到任意节点,该节点负责将其转发到包含所请求的分区的目标节点([图-7中的方法1)。该方案增加了DB节点的复杂性,但避免了对zk这样的外部协调服务的强依赖。
Couchbase不支持自动再平衡,这简化了设计。通过配置一个moxi路由选择层,向集群节点学习最新的路由变化。
当使用路由层或向随机节点发送请求时,客户端仍需知道目标节点的 IP 地址。IP地址一般没有分区-节点变化那么频繁,采用DNS通常就够了。
5.1 执行并行查询
至此,只关注了读/写入单K的简单查询(对文档分区的二级索引,要求分散/聚集查询)。这也是大多数NoSQL分布式数据存储所支持的访问类型。
但对大规模并行处理(MPP, Massively parallel processing)这类主要用于数据分析的关系型数据库,在查询类型方面要复杂多了。典型的数仓查询包含多个连接,过滤,分组和聚合操作。 MPP查询优化器将复杂的查询分解成许多执行阶段和分区,以便在DB集群的不同节点上并行执行。尤其是涉及全表扫描的查询,很受益于这种并行执行。
数仓查询的快速并行执行查询是个专门话题,分析业务日渐重要,可以带来很多利益。后文再详解。
以上是关于数据系统分区设计 - 请求路由的主要内容,如果未能解决你的问题,请参考以下文章