Concrete bridge surface damage detection using a single-stage detector-论文阅读笔记
Posted wyypersist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Concrete bridge surface damage detection using a single-stage detector-论文阅读笔记相关的知识,希望对你有一定的参考价值。
Concrete bridge surface damage detection using a single-stage detector
采用单级检测器的混凝土桥梁表面损伤检测说
//2022.7.8 上午8:46开始阅读笔记
论文地址
论文贡献
在本研究中,基于实时物体检测技术,提出了一种更快、更简单的单级检测器,用于检测多个混凝土桥梁损伤。使用标有四种混凝土损伤类型(裂缝、弹出、剥落和外露钢筋)的现场检查图像数据集对YOLOv3进行培训和测试。为了提高检测精度,通过引入一种新的转移学习方法,从几何相似的数据集中引入完全预训练权重,进一步改进了原始YOLOv3。为了提高精度,还引入了批量重正化和Focal loss损失函数。
本文所提出的三种改进模型建议:
-
选择和目标任务数据集尺度比例等相似的预训练数据集进行预训练;
-
为了缓解类别不平衡问题以及单张图片中背景和待检测目标所占整张图片比例差异过大问题,引入了BN批量正则化和Focal loss损失函数;
-
使用数据增强程序扩充了训练数据集以使得模型能够较好的泛化;
论文内容
1.介绍
公路桥梁是构成现代大都市主干的交通系统的组成部分。这些桥梁的功能性、可靠性和安全性对社会福祉至关重要。因此,有必要尽早检测这些桥梁上可能出现的缺陷,以防止其结构能力和耐久性进一步损失。在所有可用于识别和监测缺陷的无损评估技术中,尽管结构元件的内部条件不能通过仅仅使用目视检查技术和其他深入方法来做一个更加全面的评估,但目视检查仍然是最常用的方法。此外,表面缺陷是最明显的结构退化或损坏迹象。得出的结论是,表面缺陷是结构构件一般状况的良好指标,也是许多视觉状况评估手册的关键部分(Koch、Georgieva、Kasireddy、Akinci和Fieguth,2015)。
尽管人工目视检查很受欢迎,但在可接近性低的位置,对桥梁进行人工目视检查可能会耗费大量人力,而且很危险。目视检查的结果也是主观且不可靠。这些缺点导致需要开发更客观和自主的方法,这些方法几乎不需要或不需要直接的人为干预。在这种情况下,提出了基于计算机视觉的检测技术,该技术利用从无人机获取的图像来实现(Ellenberg、Kontsos、Bartoli和Pradhan,2014;H.Kim、Sim和Cho,2015)。一旦从桥梁收集到图像,就可以使用大量图像处理技术提取相关信息,用于缺陷检测、分类和评估(Koch等人,2015)。这些技术的复杂程度和处理图像的方式各不相同。其中,机器学习方法是更先进的工具,它利用提取的图像特征来执行特定任务,如分类、回归、聚类等。这些基于机器学习的方法已用于检测各种类型的缺陷,包括裂纹(Nishikawa、Yoshida、Sugiyama和Fujino,2012;Prasanna、Dana、Gucunski和Basily,2012;Zalama、Gómez GarcíaBermejo、Medina和Llamas,2014)、剥落(Dawood、Zhu和Zayed,2017;German、Brilakis和DesRoches,2012)和腐蚀(O'Byrne、Schoefs、Ghosh和Pakrashi,2013)。尽管与传统的图像处理技术相比,机器学习技术在效率和鲁棒性方面有了显著的提高,但这些方法仍然基于手工制作的低级特征,需要进行预处理和后处理。这一过程很难推广,可能不适用于变化较大的实际图像,例如从机器人平台获取的图像。
近年来,深度学习方法受到了广泛关注,并被应用于科学和工程的各个领域。深度学习利用大规模数据库,允许由多个处理层组成的计算模型学习数据表示(LeCun、Bengio和Hinton,2015)。由于这种出色的能力,各种数据形式被用于基于深度学习的结构健康监测(Cha、Choi和Büyüköztürk,2017;Dai和Cao,2017;Rafiei和Adeli,2017、2018)。特别是在使用深度学习技术的图像处理领域,近年来最重要的进步之一是卷积神经网络的发展(CNN;Krizhevsky,Sutskever,&Hinton,2012)。CNN可以增强图像处理技术的目标检测和分类能力,因为它们可以从训练数据中自动学习适当的特征,而无需事先进行图像处理或特征提取。CNN通过将每个像素分类为受损或完整来进行裂纹分割(X.Yang,Li等,2018;A.Zhang等,2017)。为了找出大图像中缺陷的程度,原始方法是使用固定大小的滑动窗口对图像进行光栅扫描,然后在每个小窗口面片上应用训练好的CNN。根据这一想法,Cha等人(2017)提出了一个深度CNN模型对每个图像块中是否出现混凝土裂缝进行分类。五十、 杨等人(2017)对VGG-16模型进行了微调(Simonyan和Zisserman,2014),将缺陷分为两类:裂纹和剥落。然而,这种基于滑动窗口的方法的挑战是在处理各种尺度的缺陷时找到合适的窗口大小。此外,这种方法具有较高的计算成本,因为CNN分类器必须对每个图像中的每个窗口应用多次。
为了提高检测和定位多个对象的效率,可以通过直接预测对象区域来增强基于CNN的对象检测器。就网络架构而言,这些对象检测器可分为两大类:两级和单级检测器。基于区域的CNN(R-CNN)是一种两阶段架构,使用区域建议而不是滑动窗口来查找图像中的对象(Girshick、Donahue、Darrell和Malik,2014)。R-CNN方法使用选择性搜索方法(Uijlings、Van De Sande、Gevers和Smelders,2013)生成区域建议,然后分别提取每个潜在边界框的特征,用于分类和框回归。然而,使用选择性搜索的区域建议生成步骤仍然很慢,并且精度有限(任,何,Girshick,&孙,2015)。此外,由于重叠区域的大量重复计算,R-CNN方法可能效率低下且耗时。为了克服这个问题,任等人(2015)提出了FasterR-CNN,用区域提案网络(RPN)代替传统的手工提案生成步骤。这两级探测器最近已用于检测结构缺陷。例如,I.Kim、Jeon、Baek、Hong和Jung(2018)将R-CNN与形态学后处理相结合,以检测和量化混凝土桥梁中的裂缝。然而,从RCNN中检测到的裂纹区域是零碎的,检测精度受到提取的潜在裂纹区域的影响。Cha、Choi、Suh、Mahmoudkhani和Büyüköztürk(2018)使用FasterR-CNN架构来检测混凝土和钢结构中的五种表面损伤。他们表明,对于具有鲜明特征的图像数据集,可以实现高精度。李、袁、张和袁(2018)还使用改进的快速R-CNN网络,使用包含各种背景信息和相对较小缺陷的数据集识别三种类型的混凝土缺陷。尽管上述研究证明了两级检测器的适当精度,但由于将区域建议作为中间步骤,它们的检测速度不是很快。随着图像数量的增加,检测过程的速度变得非常重要。对于检查视频来说尤其如此,在那里处理每一帧都可能变得极其缓慢。另一方面,在更广泛的范围内,高速检测对于开发实时机器人检测系统至关重要,这似乎是该行业未来的发展方向(Lattanzi&Miller,2017)。
由于上述局限性,提出了将单级检测器作为端到端网络,将目标分类和定位结合在一个卷积网络中。这一类别中有两种流行的型号:单点多盒探测器(SSD)(Liu等人,2016)和You Only Look One(YOLO)(Redmon、Divvala、Girshick和Farhadi,2016)。SSD和YOLO都删除了ProposalGeneration步骤,同时预测了多个边界盒和类概率。因此,它们的处理速度比两阶段方法快得多。前田、Sekimoto、Seto、Kashiyama和Omata(2018)应用SSD实时检测路面缺陷。他们证明,SSD可以对某些类型的缺陷获得相对较高的精度。然而,一些研究人员发现,使用这种单级探测器直接定位物体可能会影响检测的准确性(李等,2018;王等,2017)。特别是,最早版本的YOLO几乎无法检测到具有异常纵横比或配置的物体(Redmon等人,2016)。为了弥补这一缺陷,Redmon和Farhadi(2017、2018)引入了几项改进,以提高单级检测器的性能,包括应用批量归一化(BN)(Ioffe和Szegedy,2015),使用良好的候选锚预测YOLOv2中的边界盒,以及在YOLOv3中使用特征金字塔网络(FPN)(Lin等人,2017)和Darknet-53主干。结果表明,最新版本的YOLO(即YOLOv3)可以在不牺牲计算效率的情况下实现与两级检测器相当的精度,FasterRCNN。
除了开发网络架构外,许多研究致力于改进训练和测试过程,使深度学习方法更适用于不同的场景。首先,训练深度网络需要大量带注释的图像数据集来实现高预测精度。然而,对于一些应用,例如识别和分类结构损伤,获取相关图像并对其进行注释以进行训练并不容易。在这种情况下,通常在非常大的公共对象数据集上预训练CNN模型,然后将预训练的权重用作感兴趣任务的初始化或固定特征提取器(Oquab、Bottou、Laptev和Sivic,2014;Yosinski、Clune、Bengio和Lipson,2014)。该过程被称为转移学习(迁移学习),广泛用于基于深度学习的结构损伤识别(Gao和Mosalam,2018;Gopalakrishnan,Khaitan,Choudhary和Agrawal,2017;Kucuksubasi和Sorguc,2018;Li等人,2018)。此外,众所周知,归一化输入数据可以加快训练速度,并使深度网络能够收敛(LeCun、Bottou、Orr和Müller,2012),因为层输入分布的变化带来了层需要不断适应新分布的问题。为了解决这个问题,在深度网络中开发并采用了不同的归一化层以简化优化,例如BN(Ioffe&Szegedy,2015)、层归一化(Ba、Kiros和Hinton,2016)和实例归一化(Ulyanov、Vedaldi和Lempitsky,2016)。此外,在对象检测器训练期间遇到的类不平衡会降低模型性能,因为大量易于分类的示例可能会淹没训练过程。提出了几种有效的方法来解决类别不平衡问题,包括重新抽样训练示例(Ren等人,2015;Shrivastava、Gupta和Girshick,2016)和重新加权不同类别的损失(Lin、Goyal、Girshick、He和Dollár,2018)。此外,许多其他工作有助于优化特定任务的算法(Molina Cabello、Luque Baena、López Rubio和Thurnhoferehmsi,2018;Torres、Galicia、Troncoso和Martínez-Álvarez,2018;P.Wang和Bai,2018)和减少模型的内存和计算成本(Ortega Zamorano、Jerez、Gómez和Franco,2017;Sandler、Howard、Zhu Moginov和Chen,2018)。
本研究的目的是研究最先进的单级检测器YOLOv3在识别混凝土桥梁多类缺陷方面的适用性,并提高其检测精度。原始YOLOv3首先使用图像数据集进行配置和训练,该数据集由2206个实际图像组成,其中包含四种主要类型的混凝土桥梁缺陷。然后,提出了一种新的迁移学习方法,该方法具有来自几何相似数据集的完全预训练权重,以缓解与训练数据不足和定位精度低相关的一些问题。此外,还采用了其他技术,包括批量重整化(BR)和焦损(FL),以进一步提高检测精度。验证了改进的YOLOv3的性能,并将其与原始YOLOv3和具有代表性的两级检测器如FasterR-CNN和ResNet-101进行了性能比较。本文的其余部分组织如下。第2节概述了YOLOv3体系结构。第3节讨论了生成数据库的过程和初步的网络性能。第4节详细介绍了YOLOv3的提议改进。交叉验证和测试结果见第5节,第6节为结论。
2.YOLO V3架构
YOLOv3是一个单级CNN,由一个主干网和一个头部子网组成(图1)。YOLOv3的主干称为Darknet-53,包含23个残差单元(何、张、任和孙,2016),负责计算整个输入图像上的卷积特征图。每个剩余单元包含一个3×3和一个1×1卷积层,其中每个卷积层由三个顺序操作组成:卷积、BN(Ioffe和Szegedy,2015)和泄漏ReLU激活(Maas,Hannun和Ng,2013)。在每个残差单元的末尾,在输入和输出向量之间执行元素相加。残差单元简化了深度网络的训练,可以有效地解决消失梯度问题。此外,在五个单独的卷积层中以2的步长执行下采样操作,主要是为了降低特征映射维数(宽度和高度),以提高计算效率。主干Darknet-53使用ImageNet数据集进行预训练(Deng等人,2009),其性能与最先进的分类器相当,但计算成本较低(Redmon和Farhadi,2018)。
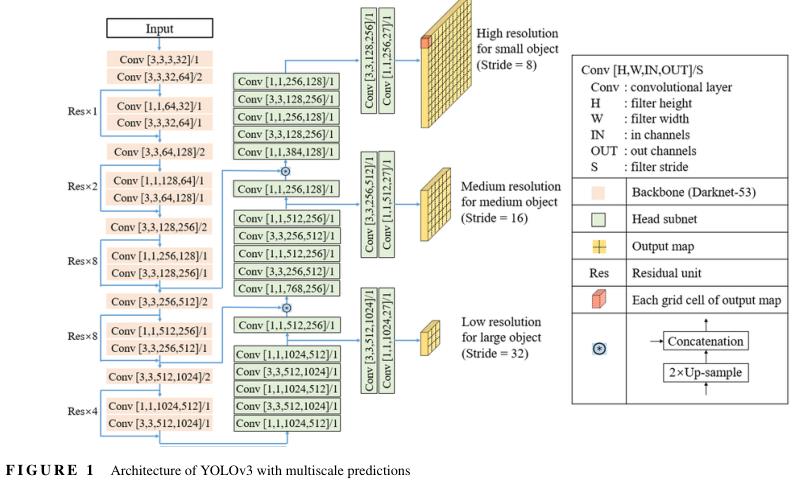
YOLOv3的头子网构建在主干之上,并采用FPN(Lin等人,2017)在三个不同的尺度上检测对象。FPN通过自顶向下的路径和横向连接来增强标准卷积网络。通过这样做,它可以有效地从单分辨率输入图像中构建多尺度特征金字塔,在各个级别上具有丰富的特征。YOLOv3结合了FPN,构建了一个三级金字塔,下采样步长为32、16和8。金字塔的每一层都可以用于检测不同比例的对象。具有较大步长的低分辨率特征图产生输入图像的非常粗略的表示,并可用于大对象检测。另一方面,更高分辨率的特征图具有更细粒度的特征,可以用于检测较小的对象。在从这三个不同尺度提取特征后,YOLOv3通过添加更多卷积层来预测每个尺度下对象的位置和类型。
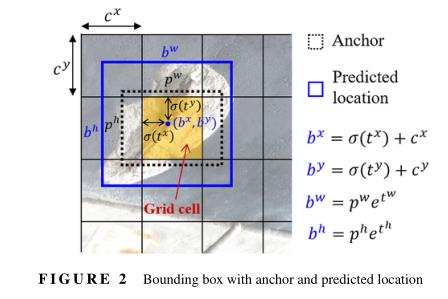
YOLOv3在三个不同分辨率的输出特征图上预测每个网格单元的三个边界框。每个预测框有一个置信变量(
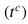
), 四类变量( , = 1、2、3、4)和四个坐标变量 . 这些预测变量分别转换为对象的置信度、类概率和位置,以生成预测结果。对象置信度퐶 反映包含对象的长方体的概率,并使用S形函数计算 :
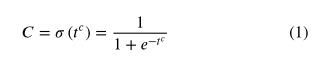
由于损伤类别在桥梁损伤数据集中是互斥的,因此使用softmax分类器在多类概率分布中转换输出类别变量(Bishop,2006)。每种损伤类型的概率
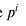
对应于
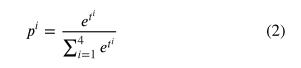
对于位置预测,YOLOv3以中心坐标在0到1之间的方式预测相对于网格单元位置的边界框的中心坐标。如图2所示,如果网格单元从图像的左上角偏移
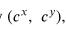
,然后,预测的边界框具有中心坐标 . 预测边界框的宽度 和高度 是从一组称为锚的预定义参考框回归生成的。对于具有宽度 和高度 的相应锚点框,预测对象的宽度 和高度 ,如图2所示。
根据这些定义,YOLOv3最小化了一个目标函数,该目标函数是置信度损失、分类损失和定位损失的加权和。交叉熵(CE)损失(Goodfello、Bengio和Courville,2016)用于测量置信度和类预测的性能,其输出是介于0和1之间的概率值。对于定位损失,使用平方和损失,因为预测值需要回归到不一定在0和1之间的特定目标值。在训练期间,YOLOv3为每个地面实况框指定一个特定的锚。换句话说,只有在地面真实框中具有最高IoU的锚点才负责预测对象。因此,如果锚负责地面真值箱,损失函数仅惩罚分类错误和定位错误。这导致边界框预测因子之间的专业化(Redmon等人,2016)。
3. 数据集和初始评估
3.1 数据集
本研究建立了一个包含香港2206张公路混凝土桥梁检查图像的图像数据集。其中,75%的分辨率为1280×960像素的图像来自香港路政署,其余分辨率为4000×3000像素的图像由作者拍摄。图形图像注释工具LabelImg(Lin,2015)用于标记损伤对象,包括其损伤类型并且边界框坐标。本研究考虑了四种不同类型的损伤:裂纹、弹出、剥落和外露钢筋。剥落是指混凝土表面剥落但钢筋未暴露的损坏类型,而弹出是指混凝土保护层仍然存在的损坏类型。为了评估网络性能,数据集被随机分成训练数据和测试数据,比例分别为8:2。图3显示了具有不同类型损伤的注释图像的一些示例。

为了确定锚定维度,YOLOv3对训练数据中的地面真值框进行k均值聚类,以自动找到锚定的良好候选。好的候选者是导致锚和地面真值框之间最大重叠的锚的尺寸。锚(簇)的数量可以调整,更多的锚似乎使预测框的任务更容易,但需要更大的计算成本。在本研究中,根据Redmon和Farhadi(2018)的建议,使用了九个锚,并根据其面积均匀分为三组。可以将每个锚点组分配到金字塔网络中的特定级别,其中具有较小比例的锚点被分配到具有较高分辨率的特征地图。通过这种方式,特定特征地图可以学习对对象的特定比例做出响应。执行具有七种图像大小的多尺度训练:MS=416,448,480,512,544,576,608,使网络能够很好地预测各种输入维度。为了获得良好的候选锚,还考虑了对这七种不同输入大小的k均值聚类。对于桥梁损伤数据集,计算的九个簇(宽度×高度)分别为:(29×22)、(30×95)、(97×37)、(39×267)、(105×101)、(290×59)、(227×139)、(126×282)和(411×209)。这九个锚可以提供平均0.583的IoU和地面实况框,70.4%的地面实况框的锚的IoU大于0.5。
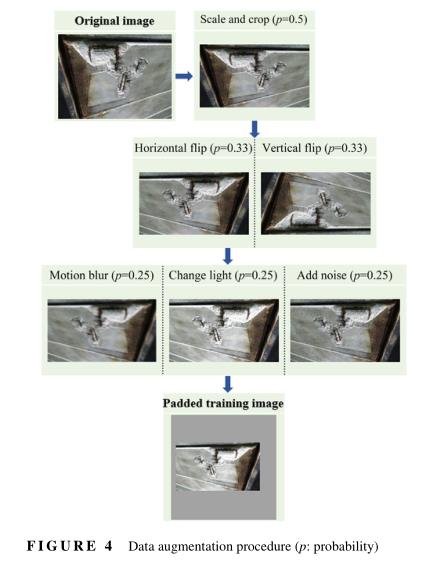
数据增强是一种提高对象检测器性能的方法,可以降低在小数据集上过度拟合的概率。考虑到桥梁检测的实际操作,考虑了以下四个方面的数据扩充。首先,在图像捕获过程中,由于摄像机的移动,图像会模糊或退化。由于风的影响,安装在飞行系统(如无人机)上的摄像机的运动模糊更为严重。图像中的偏移可以通过具有给定运动方向和长度的线性运动模糊函数来模拟(Hallermann和Morgenthal,2014;Moghadam和Jamzad,2006)。其次,由于场景的随机照明,实际检查图像的亮度变化较大。这种效果可以通过改变HSL(色调、饱和度、亮度)颜色空间中“亮度”的像素值来模拟。第三,椒盐噪声用于模拟电荷耦合器件图像传感器或图像传输中的缺陷(Koziarski和Cyganek,2017)。最后,由于在现实世界中的应用中的视角变化和摄像机损坏距离,损伤物体的尺度和纵横比变化很大。
为此,随机缩放和裁剪图像可以使模型对各种损伤大小和形状更具鲁棒性。这四个方面有助于生成涵盖图像变化范围的训练样本,并帮助网络对这些属性的变化不那么敏感。总之,每个训练图像通过以下序列(图4)进行增强:(a)随机缩放和裁剪,概率为1/2;(b) 以1/3的概率水平或垂直翻转图像;(c) 通过应用运动模糊、更改亮度或添加概率为1/4的椒盐噪声来随机操作图像;和(d)向网络输入填充训练图像。注意,数据扩充是在训练过程中进行的,原始图像用于验证和测试。同时,根据图4所示的等概率分配每个步骤中增强效应的概率。
3.2 训练YOLO V3
为了评估YOLOv3的性能和潜在应用,使用训练数据和提议的数据增强程序对模型进行训练,并根据测试数据评估其准确性。培训和测试是在运行Ubuntu 17.04操作系统的PC上进行的,该操作系统配有Intel®CoreTM i7-7700 CPU和GeForce GTX 1060 6GB GPU。实验研究使用了解释的高级编程语言Python和开源软件库TensorFlow。使用Adam优化器(Kingma&Ba,2014)对YOLOv3网络进行训练,批量大小为2,权重衰减为0.0001。训练总次数设置为80个epoch,学习率为10^-3对于前25个epoch,10^-4对于第二个25epoch,10^-5和10^-6对于剩下的每15epoch。一个类别置信度阈值设置为0.25(C类别的可能性为p^i)被用来给出预测结果。平均精确度(AP)和AP的平均(mAP)被用来评估检测性能,其中AP总结了精确度和召回率对于一个被给定的类通过计算曲线下面的面积,并mAP是计算所有类别AP的平均数。
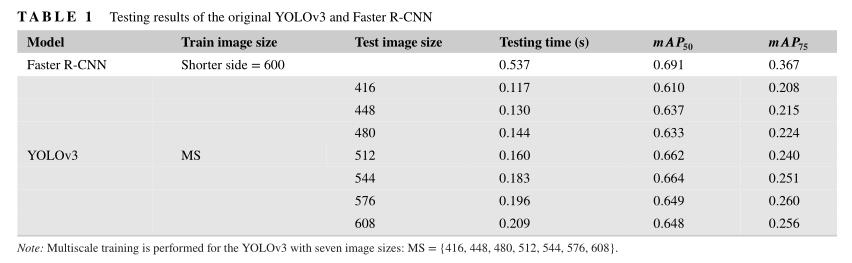
相对于从头开始训练,迁移学习采用微调的手段训练YOLO V3,其中骨干网络使用在ImageNet数据集上进行预训练的DarkNet-53网络权重进行初始化。与无预训练权重的头子网相关的卷积层通过Xavier初始化进行初始化(Glorot&Bengio,2010)。从作者之前的工作来看,在IoU=0.5的平均精度方面,在上述数据集上,带迁移学习的训练YOLOv3模型比不带迁移学习的模型具有更好的性能(C.Zhang&Chang,2019)。在本研究中,两个IoU的平均精度均为0.5(mAP,50)和IoU=0.75(mAP,75)用于评估检测精度。对于需要更精确定位的特殊任务,使用更严格的IoU度量0.75进行计数(Lin等人,2014)。对于需要在检测区域内进行损伤分割或量化的任务,更高的定位精度尤为重要(I.Kim等人,2018)。测试结果在不同的输入图像大小上进行了评估,与多尺度训练中使用的图像大小相同。表1总结了不同测试图像尺寸下,在IoU=0.5和IoU=0.75时的平均精度。如图所示,两者之间存在三倍的差距mAP,50和mAP,75适用于所有图像尺寸。这表明大多数预测和相应的地面实况框之间的重叠刚刚超过0.5,这可能是后续任务(如损伤分割)的问题。还应提及的是,实现的检测速度远低于原始YOLOv3论文中的报告值(Redmon&Farhadi,2018),这主要是由于GPU性能的差异。
3.3 与Faster RCNN进行对比
为了更好地了解YOLOv3在桥梁损伤检测中的性能和适用性,将其准确性和检测速度与结构检测领域最常用的目标检测器——FasterRCNN进行了比较(Cha等人,2018;程和王,2018;李等人,2018;梁,2018)。FasterR-CNN包括两个步骤:(a)RPN将图像作为输入,并输出一组矩形对象建议;和(b)快速R-CNN检测器从RPN及其相应的特征向量中获取提议区域集,以预测类概率和边界框的偏移值。在快速R-CNN中,RPN和快速R-CNN共享用于特征提取的基本卷积层。在本实验中,选择ResNet-101(He等人,2016)作为共享基础层,在ImageNet数据集上进行预训练。为了微调FasterRCNN,将RPN和快速R-CNN网络合并为一个网络,并使用端到端联合训练方法,如Huang等人(2017)所述。
为了训练FasterR-CNN,将输入图像的短边缩放到600像素,并应用与训练YOLOv3相同的数据增强过程。对于锚,使用了三种具有箱形区域的比例:462、1092和2352,以及三种纵横比:1:1、1:3和3:1。这些锚定尺寸是根据物体比例的分布精心选择的,物体百分比分别为16.7%、50%和83.3%。这九个锚可以提供0.572的平均IoU和地面实况框,67.4%的地面实况框的锚的IoU大于0.5。使用Adam优化器,将训练epoch设置为120。前60个时代的学习率是10−4,在剩下的60个时代中,每30个时代除以10。注意,使用300个RPN方案获得了Faster R-CNN的测试结果。
表1总结了YOLOv3和更快的R-CNN之间的测试性能比较。观察当在具有上述规格的PC上测试时,Faster R-CNN的测试速度大约是YOLO v3的3到5倍。在检测精度方面mAP,50和mAP,75在输入图像大小为512时,Faster R-CNN分别比YOLOv3高出约2.9%和12.7%。尽管在COCO数据集上测试时,YOLOv3显示出与Faster R-CNN相似的准确性(Redmon&Farhadi,2018),但mAP,75在桥梁损伤数据集上,Faster R-CNN远高于YOLOv3。这可能是由于小损伤数据集,这使得传输的特征层对准确性影响更大。对于Faster R-CNN,只初始化RPN的最终完全连接层和一个小的头部子网,而不需要预训练权重,其权重参数比YOLOv3的头部部分更少。此外,更快的RCNN受益于边界盒回归的两个阶段,这比YOLOv3提供了更准确的预测位置。接下来,我们研究了一些改进,以提高YOLOv3的检测精度,尤其是定位精度。
4.对于使用的YOLO V3框架进行改进
影响迁移学习性能的因素有很多,在对相对较小和不同的数据集(如结构检查图像)进行微调时,将迁移学习应用于物体检测器的常见做法可能表现不佳。另一个问题是在网络训练期间背景(即没有损坏)和前景之间的不平衡。这也可能是训练数据集中不同损伤类别的情况。此外,GPU内存不足可能导致训练批量较小,这可能会降低BN的有效性,并导致测试结果较差。为了缓解这些问题,本节提出了对YOLOv3的一些改进。
4.1 迁移学习
由于将ImageNet预训练CNN用于TL取得了显著的成功,人们在理解影响TL性能的因素(Huh,Agrawal和Efros,2016)。影响源任务(预训练模型)和目标任务(目标模型)之间可转移性的因素通常有两组:(a)模型属性,例如网络架构(Azizpour、Razavian、Sullivan、Maki和Carlsson,2016)和转移层的数量(Yosinski等人,2014);(b) 数据属性,例如预训练数据的大小和分布(Azizpour等人,2016;Sun、Shrivastava、Singh和Gupta,2017)以及预训练数据和目标数据之间的相似性(Cui、Song、Sun、Howard和Belongie,2018;Lim、Salakhutdinov和Torralba,2011;Yosinski等人,2014)。这些研究表明,更多传输的特征层可以实现更好的TL性能。此外,预训练数据和目标数据之间的相似性越高,目标任务的性能越好。预训练数据和目标数据之间的相似性可能来源于两个任务之间的类别重叠(Huh等人,2016;Oquab等人,2014)和不同类别之间的共享视觉属性,例如颜色、纹理和物体形状(Cui等人,2018;Lim等人,2011;G.Wang,Forsyth,&Hoiem,2013)。
在本研究中,受具有更高相似度和更多转移特征层的预训练模型可以实现更好性能这一事实的启发,提出了一种新的TL方法。微调过程分两步进行,而不是使用损伤数据集直接微调所有层。首先,从COCO数据集(Lin等人,2014)中提取与损伤数据集具有更高几何相似性的更大公共对象数据集,以微调网络。然后,使用损伤数据集恢复和微调所有层的完全预训练权重。图5说明了常用的(TL-A)和提议的(TL-B)TL方法。在TL-B的第一个微调步骤中,使用了损伤数据集k均值聚类中的锚。也就是说,因为为每个级别指定了特定比例的锚,并且特定特征地图学习对对象的特定比例作出响应。因此,这有助于使预训练权重中的对象比例和损伤数据集在每个级别的特征图方面相似。
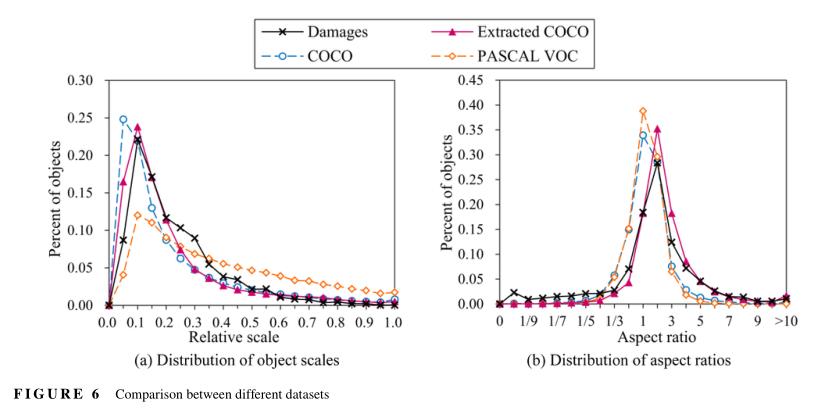
在该方法中,在预训练数据集和目标数据集之间,选择对象的几何属性(包括比例和纵横比)作为相似性度量。与其他相似性源相比,自然期望该度量与目标任务的定位精度之间具有更高的相关性。实际上,当从预训练网络进行微调时,预训练数据集和损伤数据集之间的对象比例差异可能会导致较大的域偏移。这使得优化过程变得困难(Redmon和Farhadi,2017;Singh和Davis,2018)。因此,在第一个微调步骤中,从COCO数据集中提取对象比例和纵横比分布最接近损伤数据集的类。对象比例的分布如图6a所示,表示为20个均匀分布的相对比例段中对象的百分比,其中,相对比例是由图像大小归一化的对象大小。类似地,在图6b中,对象纵横比的分布绘制为20个纵横比段0–1/10,1/10–1/9,…,9–10,>10中每个段的对象百分比。通过欧几里得距离测量和排序每个COCO类和损伤数据集之间分布的相似性。提取的四个COCO类(即,长凳、叉子、滑板和卡车)的总数据数为17952,其对象比例和纵横比的欧几里得距离之和最小。
图6显示了桥梁损伤、提取的四个COCO类、COCO和PASCAL VOC数据集之间数据分布的比较。很显然,提取的四个COCO数据集类数据中的对象尺度和纵横比与桥梁损失数据集相比具有很高的相似性,其中PASCAL VOC有最少的相似性。为了评估这种相似性对TL性能的影响,研究了另一种称为TL-C的方法,其使用完全预训练的COCO或PASCAL VOC权重初始化所有层(图5)。在随后的实验研究中,该模型从预训练的主干权重开始,并分别对完全预训练的权重进行总共80和50个epoch的训练来微调。
4.2批量正则化
YOLOv3采用BN(Ioffe&Szegedy,2015)对每层卷积输出进行归一化,有助于稳定训练,加快收敛速度,并对模型进行正则化。每个BN层中的输入向量是一个四维张量,其尺寸为:N X H X W X C,如图7所示,其中N表示采样数(也就是batch-size的大小),H和W表示高度和宽度,C是通道数。在训练期间,BN沿每个通道独立地对输入向量进行归一化,如下所示:
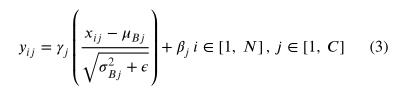
其中xij和yij表示每个BN层对i采样数据集沿着每个通道j上的输入和输出向量。
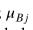
和 是每一个小批量的所有采样数据在每个通道j上的均值和偏差(如图7所示)。 和 是与原始模型参数一起学习的一对参数;且 是一个小实数,以避免被零除。在后一个测试时间,均值和方差的移动平均值(作为整个训练集统计数据的估计)用于归一化步骤:
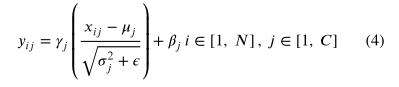
其中
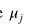
和 是移动平均值和偏差沿着每个通道j进行计算的,如图7所示。
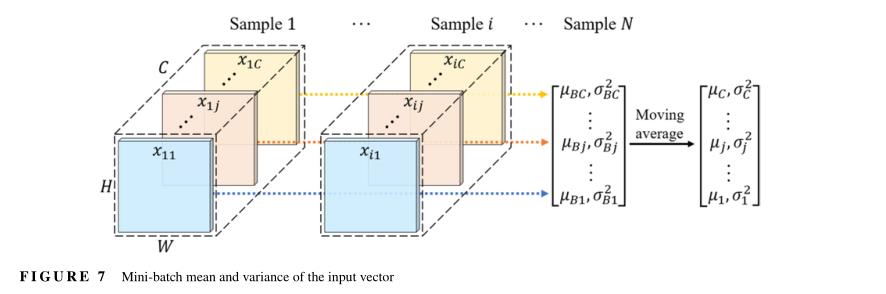
然而,在整个训练集中,小批量平均值
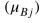
和方差 经常偏离平均值 和方差 。因此,在训练和测试期间,均值和方差不同,这可能会降低测试性能。由于GPU内存有限,当训练批大小很小时,通常会发生这种情况。对于检测和分割任务来说,这种批量限制更为严格,因为它们受益于大尺寸的输入图像(P.Luo,Ren,Peng,Zhang,&Li,2018;Wu&He,2018)。例如,在本研究中,计算机只能承受2的批量(N=2)。BR试图直接解决训练和测试时统计数据不同的问题。在测试期间,BR具有与BN相同的归一化步骤形式(等式4)。然后,在训练期间,BR通过仿射变换增加了BN的归一化步骤,如下所示:
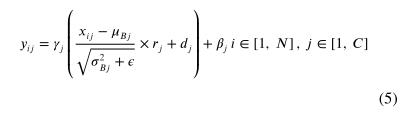
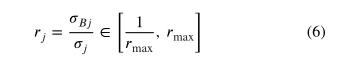
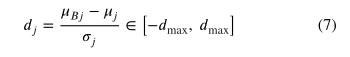
其中,
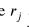
和 在梯度计算过程中被视为常数; 和 分别为当前移动均值和方差;且 和 是引入的两个超参数来控制BN和BR之间的转换(默认值在Ioffe中使用,2017)。在测试时,使用小批量统计信息 和训练时的仿射变换和移动平均 以确保BR在两个阶段的输出相同。BR最初是在分类模型上评估的,尚未应用于其他任务,如目标检测和分割。因此,有必要研究BR在目标探测器中的性能和适用性。
4.3 Focal loss
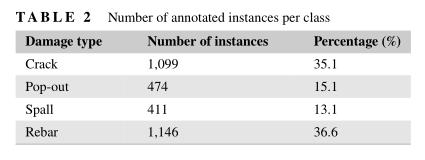
训练单级检测器的一个问题是前景和背景样本之间存在不平衡,例如,对于包含两个对象的512×512图像,约为1:8000。因此,易于分类的背景样本构成了大部分置信度损失,并主导了梯度。此外,训练数据中不同损伤之间的类别不平衡也会产生类似的影响。在我们的案例中,属于外露钢筋和裂缝的损伤实例数量(72%)远大于其他两种损伤(28%)(表2)。置信度和类不平衡导致两个问题:(a)训练不是很有效,因为大多数位置是简单的背景样本,没有提供有用的学习信号;和(b)具有大量样本的背景和损伤类别可能会压倒训练并导致退化模型。为了缓解这些不平衡问题,常用的方法是对于不同的类别损失应用不同的固定加权因子。然而,这种方法中的权重因子应该仔细选择,它们不会区分简单/困难的例子。在本研究中,FL(Lin等人,2018)应用于原始损失函数,该函数动态缩放不同类别的损失。FL使用一个调节因子来减轻简单样本的重量,通过贴现其对总损失的贡献来解决不平衡问题,即使其数量很大。换句话说,FL在稀疏的硬样本集上执行训练。FL最初用于多类预测,其中每个类都被视为具有sigmoid输出的二进制分类问题(Lin等人,2018)。然而,在YOLOv3中,置信度(前景和背景)和类预测是分开的,它们应该采用不同形式的FL。对于每个预测的置信度损失,应用于具有sigmoid输出的CE的FL如下:
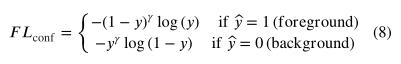
对于每个预测的分类损失,具有softmax输出的CE的FL如下所示:
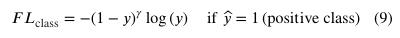
其中,
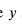
和 分别是预测值和基本真值; 和 是调制因素;且 是是一个聚焦参数,用于平滑调整简单样本的下加权率。当 时,FL和CE是等价的,且当 增加时,调制因子的降权效应同样增加(在本研究中,在所有实验中使用 )。图8展示了应用FL进行置信度损失的示例,前景和背景样本之间的比率为1:1000。在该示例中,背景样本的预测值被说明为从0.6移动到目标值0,并且假设前景预测分别为0.3和0.6。可以看出,当使用原始CE损失函数时,背景样本几乎总是承担所有置信度损失。然而,当背景样本变得易于分类(例如背景预测)时,FL显著降低了背景样本的损失≤ 0.2). 在这种情况下,FL可以更加关注硬的、错误分类的前景样本。
5.结果和讨论
为了研究在原始YOLOv3上提出的改进的性能,使用第3.2节中描述的相同训练设置进行了交叉验证和测试实验。交叉验证通常用于调整模型超参数并比较不同模型设计的性能(Brownlee,2018)。测试实验使用了测试数据,这是一种坚持数据集以提供最终模型的无偏评估(Brownlee,2017)的方法。
5.1 交叉验证结果
根据五倍交叉验证原则,将训练数据随机划分为五个大小相等的子样本。每个子样本在每个损伤类别中的比例相同。然后重复交叉验证过程五次,五个子样本中的每一个子样本恰好使用一次作为验证数据。按顺序评估了上述三项改进。为了评估提议的TL方法,进行了以下五个实验:(a)TL-a:使用预训练的Darknet-53权重初始化主干,然后使用80个时期的损伤数据集对所有层进行微调(将TL应用于对象检测器的常见做法);(b) TL-b:按照第4.1节中解释的程序,使用预训练的Darknet-53权重初始化主干,在前30个时期,首先在提取的四个COCO类上微调所有层。然后,使用剩余50个时期的损伤数据集对所有层进行再次微调;(c) TL-B*:类似于TL-B,但在第一个微调步骤中使用提取的四个COCO类的k均值聚类的锚;(d) TL-C1:使用预训练COCO权重初始化所有层,然后使用50个时期的损伤数据集对所有层进行微调;(e) TL-C2:与TL-C1类似,但使用预训练的PASCAL VOC权重。预先训练的COCO和PASCAL VOC权重可公开获取,最初分别为80和20个班进行训练。为了恢复所有层的这两个完全预训练权重,对每个尺度的最后一类预测通道进行裁剪,只保留前四类通道。此外,TL-C1和TL-C2微调的训练设置与TL-B和TL-B*的第二微调步骤(50个阶段)相同。表3总结了五个TL实验。
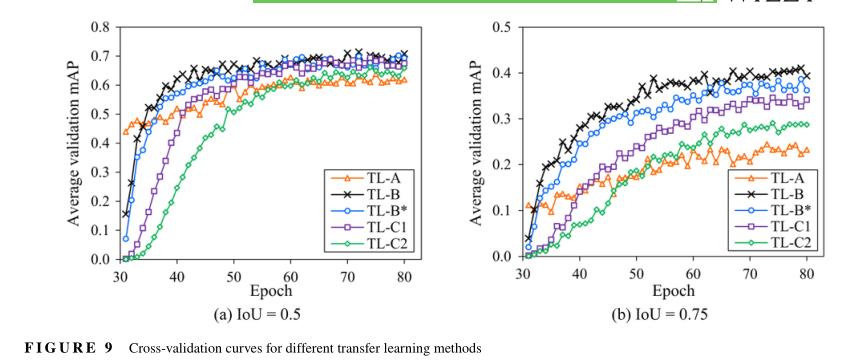
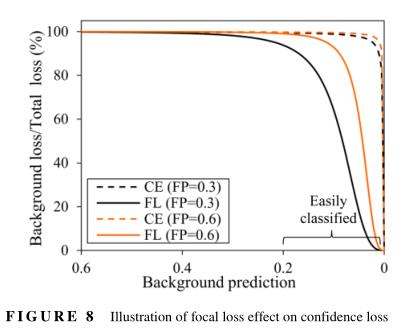
图9a、b分别显示了在过去50个训练周期中IoU=0.5和IoU=0.75时的验证精度比较。在输入图像大小为512的每个训练历元后评估验证精度,并表示为五倍交叉验证的平均值。可以看出,验证精度显示出一条噪声曲线,这种波动主要是由于Adam优化器的固有特性和小的训练批量造成的。比较五个TL实验,具有完全预训练权重(TL-B、TL-B*、TL-C1和TL-C2)的模型比仅使用预训练主干权重初始化的TL-a收敛速度更快,精度更高。TL-B使用来自相对较大且几何相似数据集的完全预训练权重,在以下方面提供了最高的精度:mAP 50=71.4%,比常用的TL-A高7.6%(表3)。对于严格的评估指标,TLB给出了一个mAP75=41.0%,比TL-A高16.6%。与TL-B和TL-B*相比,在第一个微调步骤中,使用来自损伤数据集k均值聚类的锚提供了1.2%和2.4%的精度提高分别对应于mAP50和mAP75。这可以归因于当在预训练模型和目标模型中使用相同的锚时,减少了每一级特征图中的域偏移。此外,具有完全预训练COCO权重(TL-C1)的模型的mAP50和mAP75比具有完全预训练PASCAL VOC权重(TL-C2)的模型高出约3.3%和5.7%,但比具有TL-B的模型低2.0%和6.2%。就收敛速度而言,TL-B是所有TL情况中最快的,如图9所示。这些结果表明,当使用来自几何相似数据集的完全预训练权重进行微调时,可以实现更好的TL性能,尤其是在定位精度方面。
图10和表4总结了当使用开发的TL方法TL-B进行训练时,使用BR和FL的YOLOv3的验证精度。比较了使用BN和BR的YOLOv3的验证精度,在mAP50和mAP75的情况下验证集精度分别提高了3.7%和2.3%。并且,FL方法分别得到了1.9%和3.2%的增益在mAP50和mAP75的情况下。在mAP75的情况下精度得到显著增加的原因是FL降低了来自简单样本的置信度和分类损失,因此在本地化损失上惩罚更多。此后,具有TL-B,BR和FL改善的YOLO V3模型表示为“改进的YOLO V3”且将只有TL-A表示为“原始”YOLOv3的YOLOv3。注意,无需评估三种改进的所有组合,因为最终模型始终相同,尽管不同的评估顺序可能会稍微影响每个改进的准确性值。此外,应注意的是,在本研究中,获得的精度改进仅限于桥梁检查图像数据集。因此,其他数据集可能会给出不同的精度值,需要对各种目标检测数据集进行更多实验,以充分验证改进的YOLOv3的泛化。
5 .2 测试结果
为了获得改进的YOLOv3的测试结果,使用所有训练数据对模型进行训练,并根据测试数据评估其准确性。在此,还提供了原始YOLOv3的测试性能作为参考。图11和12以及表A1总结了不同测试图像尺寸下每类的测试精度以及IoU=0.5和IoU=0.75时的平均精度。对于改进的YOLO V3,输入图像大小为512时,对于裂缝、弹出、剥落和外露钢筋的AP 50值分别为:76.5%、82.7%、73.9%和86.6%。对于相同的输入图像大小,改进YOLO V3网络的mAP50和mAP75分别为:79.9%和47.2%,分别比原始模型的值高出13.7%和23.2%。在mAP75增量较大显示了使用新的TL方法和改进的改进YOLOv3模型提供了更准确的位置预测。比较不同类别之间的平均精度(图11),当IoU=0.5时,外露钢筋的精度高于其他三个类别。除了具有相对较大的数据集之外,这可能是因为与其他损伤相比,表示外露钢筋的纹理往往更一致。裂纹和剥落的平均精度较低,这可以归因于裂纹特征不足,剥落的规模和数据集大小较小。
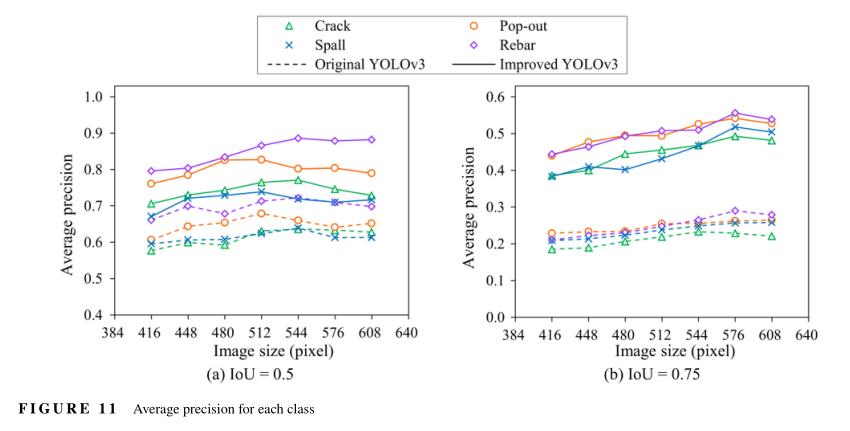
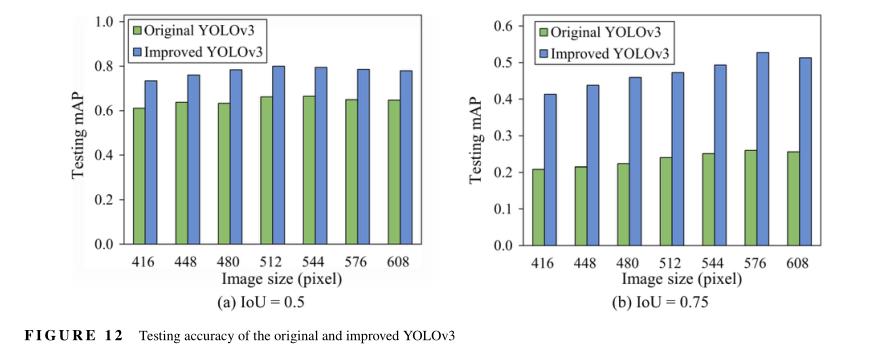
图12显示了与多个图像尺寸相比的平均精度。如图所示,不同图像尺寸之间的精度差异不是很显著。这表明多尺度训练使网络能够跨各种输入维度进行预测。然而,可以观察到,当图像大小增加时,精度会下降一些。这种现象可归因于几个因素:(a) 负责检测大型物体的最低分辨率特征图上的有效感受野(W.Luo,Li,Urtasun,&Zemel,2016)不足以预测放大的物体;(b) 当图像大小变得非常大时,图像大小和锚点大小之间存在不匹配;(c)多尺度训练可能产生的不稳定性。
图13显示了改进的YOLOv3的检测示例。测试结果表明,在各种条件下(例如,位置、视点、摄像机损坏距离、照明、模糊、背景等)拍摄的检查图像具有一致的性能。图14展示了训练模型未能检测和定位损伤的示例。在图14a中,网络无法区分剥落钢筋和外露钢筋,因为它们都具有外露混凝土骨料的相似特征。类似地,一些弹出损 以上是关于Concrete bridge surface damage detection using a single-stage detector-论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章