数据准备之日志采集发展历程
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据准备之日志采集发展历程相关的知识,希望对你有一定的参考价值。
前言
大家都听说过大数据计算,可能大家没想过大数据计算的数据来源自哪里呢?是怎么被抽取到数据仓库的呢?
实际上数仓/数据湖的数据主要来源于日志、业务数据、第三方接口、mysql 和 hbase 等其它存储。大数据这边有专门的数据集成工具(类似:datax,flinkx,seatunnel,dataflow),就像一只八爪鱼把各种数据采集到大数据的数据仓库来。
由于我们公司的日志数据在国外分散于多个可用区,采集日志也就不能使用一些开源的方案。在这里由我给大家简单介绍下我们公司大数据的数据准备之日志采集的发展历程。
日志滚动切割+CronTab

应该是在 2020 年之前,日志采集方式还是应用使用指定的 logback.xml 配置文件,该配置除了指定日志的格式外还会定期滚动日志文件。然后运维这边会在服务器上新增一个 crontab 定时任务,该定时任务会每隔三个小时将滚动的日志文件上传到对象存储并清理掉。
但是此种方式有以下弊端
- 定时服务安装在客户端,对应用有侵入性
- 日志量过大的情况下会抢占机器
CPU,对应用性能产生影响 - 实时性不足,三小时滚动成一个文件,由于上传也会占用时间,大数据离线任务通常需要延迟
4个小时开始执行 - 数据可能丢失,比如应用下线了一台机器,但是由于日志还未达到三个小时的滚动时间,导致日志未能上传
看到这里大家可能会有一些问题,1.为何三小时滚动一次?由于最初是大数据离线计算使用,实时性要求并不是很高,另外频繁的上传频率,对应用影响也较大。2.为何要删除历史的日志文件? 由于上传脚本是没有持久化已经上传了哪些文件,如果不清理,导致在下次上传文件时不知道是不是上传过,考虑到日志已经通过 elk 采集,可以在 kibana 查看,所以直接对上传过的文件进行清理即可。
Flink 采集
2020 年,Flink 社区处于一个高速发展的阶段,大数据部门也早早引入了 Flink 来解决一些实时业务问题,当时我们发现了旧的采集方式的弊端,于是决定使用 Flink 来做日志采集,此时主要是要解决掉日志丢失、对应用的影响、以及实时性的问题。

上图是 Flink 的采集方案。运维这边会使用 Filebeat 将应用的日志实时转发到 log kafka,然后大数据这边将会使用 Flink 启动一个 source 为 kafka,sink 端为 HDFS 的实时任务,此时即完成了日志的初步采集。最后会在我们的 HERA离线调度平台上新建一个 ETL 任务,每个小时周期调度将最近两个小时的 HDFS 日志数据同步到对象存储(s3/cosn/oss/wabs)上,然后删除 HDFS 的临时数据。
在这里三个问题
1.数据已经上传到 HDFS 了,为什么还要上传到对象存储?
首先我们大数据离线计算和存储是分离的架构,也就是说我们的存储都是在对象存储上,计算资源是需要的时候创建,不需要的时候就回收掉,并不会导致数据的丢失。受限于计算存储分离的架构,我们的数据只能放到对象存储。
2.为什么 Flink 不直接将日志写到对象存储上,还要在 HDFS 中转一下?
在这里用 HDFS 中转的原因是在开发这个程序的时候,FlinkStreamingFilesink 支持的还不是很完善,仅仅对 HDFS 支持了 Exactly-Once 的语义,对一些云厂商的对象存储还不支持,在重启或者挂掉等异常情况下可能会导致数据的重复,所以使用了以上方式。
3.为什么每个小时要拉取最近两个小时的数据?
这里是出于 Flink 日志采集任务可能延迟的原因,因为 Flink 和 hera 之前并没有进行一种通知机制,比如在某个小时的日志数据采集完成之后通知 hera 进行 ETL 抽取,考虑到 Flink 日志采集可能会延迟,所以冗余了两个小时的数据。
Flink 采集 2.0
在 2021 年,整个研发部门都有了降本的目标,此时我们发现 Flink 1.0 的日志采集产生了大量的流量费用。究其原因就是我们的应用部署在 AWS 等 Region,为了保证 HA,应用又部署到多个可用区,但是我们的大数据平台 EMR 平台只部署了一个可用区,也就发生了跨 AZ 的日志数据拉取,导致流量费的产生,甚至流量费占用了整个集群费用的 70%。
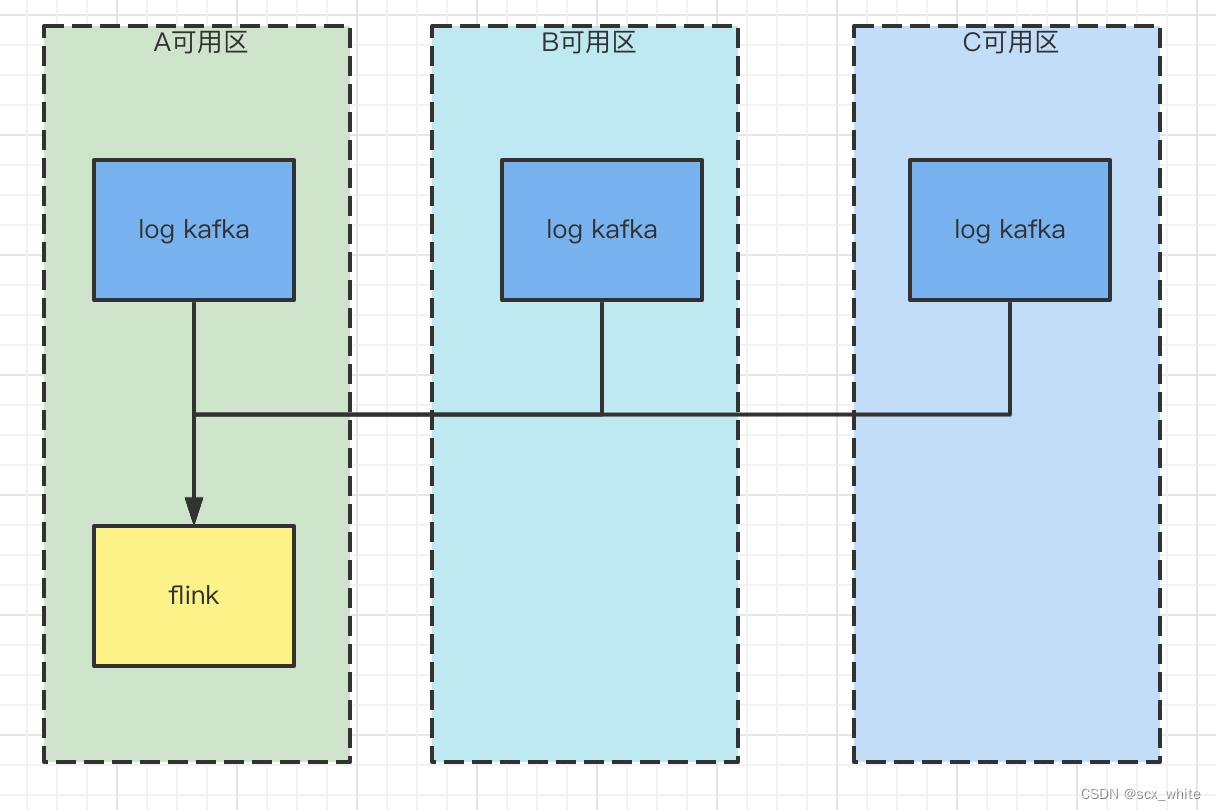
所以,我们对于一些大日志量的 Topic 进行了同可用区的采集,方式也很简单,创建一个跨多个可用区的 Flink 大数据集群,然后在每个可用区都启动一个相同的采集任务。但是该种方案会有一些问题,原因是我们的采集集群和业务集群用的是同一个,如果变成跨可用区的 Flink 集群,此时如果 Flink 实时任务的 TaskManager 分散在不同的可用区,TaskManager 和 JobManager 不在同一个可用区在进行计算时都会产生额外的流量费,所以我们把业务 Flink 集群和采集 Flink 集群分开了。
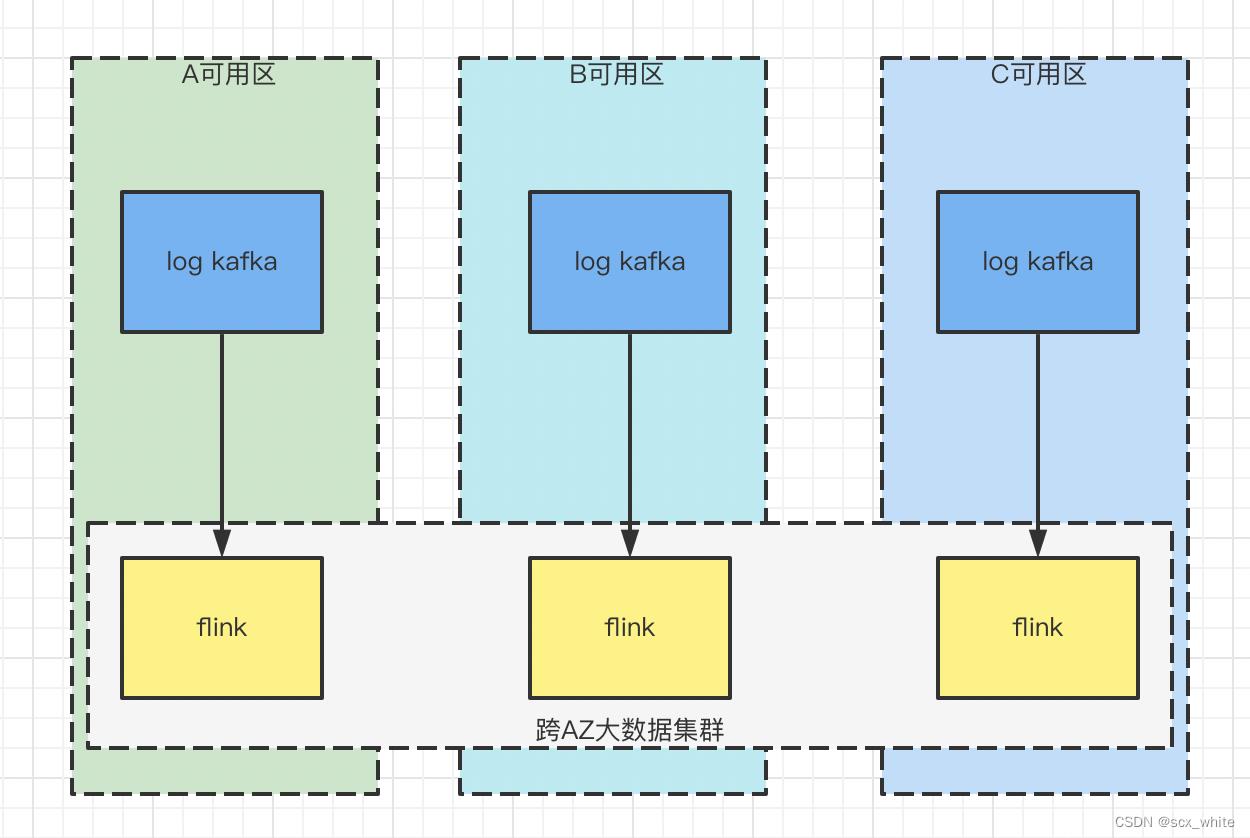
至此,我们完成了 Flink 2.0 的日志采集方案,解决了跨可用区日志采集的流量问题。
彩虹桥
尽管 Flink 2.0 已经是比较完善的数据采集方案了,但是它仍然有以下弊端
- 采集任务需要确保在每个可用区启动一个
Job,浪费资源 - 每个采集任务都是一个
Job,即使日志量极小,浪费资源 - 只对日志量较大的
Topic进行同可用区采集,如果日志量不大,需要在资源和流量成本之间进行取舍 - 有一些日志数据,业务
Flink集群也需要,而业务Flink集群只部署在一个可用区,流量问题还是存在
基于以上这些原因,22 年的 4 月份,设计了新的采集方案,该方案基于:无论在哪个可用区,向对象存储的读写都不收流量费。
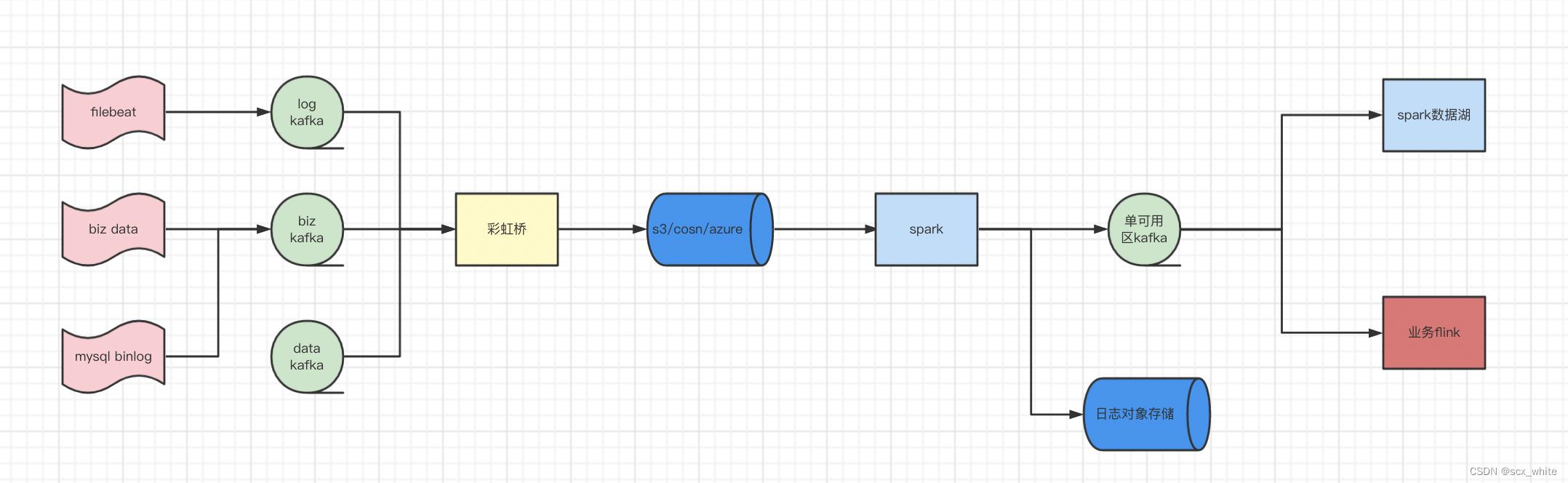
在该方案中,彩虹桥不再使用 Flink 或者 Spark 开发,改为纯 Java 代码。这样就能使用我们的部署平台部署到各个可用区。kafka client 使用经我们中间件开发的同可用区消费并且支持 trace 监控,加上各个对象存储都支持对 HDFS 的 API 兼容,所以写对象存储时使用了 HDFS 的 FileSystem 进行写入。彩虹桥将会根据配置的滚动时间和文件大小将日志数据上传到对象存储(该存储为临时存储,不是最终的日志存储,目前保存策略为TTL=三天)。
在彩虹桥将数据写到对象存储后,我们将会启动一个 Spark 周期任务,该 Spark 任务会监听对象存储之上文件的变更,如果新增了文件,则将新增的文件数据转发到单可用区的 Kafka 集群(也可以 Leader 为单可用区的 Topic)供下游的实时业务使用,或者直接根据配置的分区字段保存到日志存储。
在彩虹桥开发过程中也遇到一些问题,比如消费的性能问题,精确一次的问题,任务的分配问题,在这里简单说一下。彩虹桥系统的具体架构就不再叙述。
- 消费吞吐优化
最初发现一台机器每秒只能达到 2000 的 TPS,查看公司 kafka-client 源码后发现,我们公司的反序列化默认使用KafkaJSONDeserializer 该类会对所有消息进行 Json 解析,所有的 CPU 时间都浪费在 Json 解析上,由于我仅仅对日志的消息进行保存,无需关心具体的消息内容,所以重新定了反序列化器,吞吐量一下就上升了几十倍。
- 异步消费
由于彩虹桥订阅了多个 Kafka 集群,并且同时会消费较多 Topic。 公司默认的 Consumer 一次只能处理一次一条消息。而对于文件的写入,最好是减少 IO 次数批量写入,所以我重新实现了KafkaAcknowledgingConsumer ,将消息、Topic、Partition、Offset以及 ACK 等信息都放入到一个消费队列中。 在下游每个 Topic 会有一个 Write 线程,将消费队列中的数据批量写到文件中。当文件上传成功后触发 ACK 事件。
- 精确一次处理
彩虹桥将每个 Topic 的消费当作一个任务,每个彩虹桥应用对于同一个任务同一时间只有一个输出文件。 并且将文件划分为三个状态,分别为:IN_PROCESS,FINISH,COMMIT 三个状态,在 zookeeper 上记录每个文件的写入状态。
IN_PROCESS:临时文件已经创建,数据可以写入
FINISH: 临时文件已经写入完毕,并且各个 Partition 的 Offset 也已经保存到 zookeeper 完毕
COMMIT: 临时文件上传到对象存储完毕,已经删除临时文件
有了这三种状态,在我们重启时或者任务异常挂掉时就可以根据文件不同的状态进行任务的恢复,
彩虹桥实现了ConsumerAwareRebalanceListener 接口,当 Kafka 某个 Topic 的 Partition 做rebalance 时,将会触发ConsumerAwareRebalanceListener 的onPartitionsRevokedBeforeCommit 方法和onPartitionsAssigned 方法。此时我们需要在onPartitionsRevokedBeforeCommit 方法下做一些预处理。
IN_PROCESS:表示文件创建完成,数据写入中,此时直接删除临时文件,获取在 zookeeper上保存的 Offset,通过 consumer.seek 进行消费。
FINISH:对临时文件进行上传,删除临时文件,获取在 zookeeper上保存的 Offset,通过 consumer.seek 进行消费。
COMMIT:文件无需处理,获取在 zookeeper上保存的 Offset,通过 consumer.seek 进行消费。
- 任务分配
对于每个 Topic,我们希望在每个可用区都根据配置的并行度来分配消费者。比如共有三个可用区,彩虹桥共 6 台机器,我们配置了一个并行度为 3 的采集任务,此时如何分配?
彩虹桥上所有的采集任务都会在 zookeeper 的 node 上,node下将会挂载目前正在消费该 Topic 数据的彩虹桥节点。

当彩虹桥收到任务开启的通知时,首先会进行平均到单个可用区的计算:
int zoneParallelism = parallelism % globalEnv.getZoneNum() == 0 ? parallelism / globalEnv.getZoneNum() : (parallelism / globalEnv.getZoneNum() + 1);
然后将会对 zookeeper 上的该任务节点下已经抢占的的彩虹桥应用进行统计,如果当前可用区的应用数小于 zoneParallelism 则在该任务节点下进行顺序临时节点的新增,然后获取最新的彩虹桥应用,如果当前可用区的数量在 zoneParallelism 之内,并且该节点在 list上,则启动新的消费。如果大于,则删除自己的节点。
通过以上策略,我们也就完成了日志采集的最终方案,目前彩虹桥项目开发完成,并且接入了大概十个日志采集。在美国区高峰期有 300M/s 的日志写入量,平均有 200M/s 的日志写入量,后续将完全替换 Flink 采集 2.0。
以上是关于数据准备之日志采集发展历程的主要内容,如果未能解决你的问题,请参考以下文章