最新NLP赛事实践总结!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新NLP赛事实践总结!相关的知识,希望对你有一定的参考价值。
赛题介绍
国内车企为提升产品竞争力、更好走向海外市场,提出了海外市场智能交互的需求。但世界各国在“数据安全”上有着严格法律约束,要做好海外智能化交互,本土企业面临的最大挑战是数据缺少。本赛题要求选手通过NLP相关人工智能算法来实现汽车领域多语种迁移学习。
赛事地址:https://challenge.xfyun.cn/topic/info?type=car-multilingual&ch=ds22-dw-gzh01
赛事任务
本次迁移学习任务中,讯飞智能汽车BU将提供较多的车内人机交互中文语料,以及少量的中英、中日、中阿平行语料作为训练集。
参赛选手通过提供的数据构建模型,进行意图分类及关键信息抽取任务,最终使用英语、日语、阿拉伯语进行测试评判。
1.初赛
- 训练集:中文语料30000条,中英平行语料1000条,中日平行语料1000条
- 测试集A:英文语料500条,日文语料500条
- 测试集B:英文语料500条,日文语料500条2.复赛
- 训练集:中文语料同初赛,中阿拉伯平行语料1000条
- 测试集A:阿拉伯文语料500条
- 测试集B:阿拉伯文语料500条赛题数据
本次比赛为参赛选手提供三类车内交互功能语料,其中包括命令控制类、导航类、音乐类。
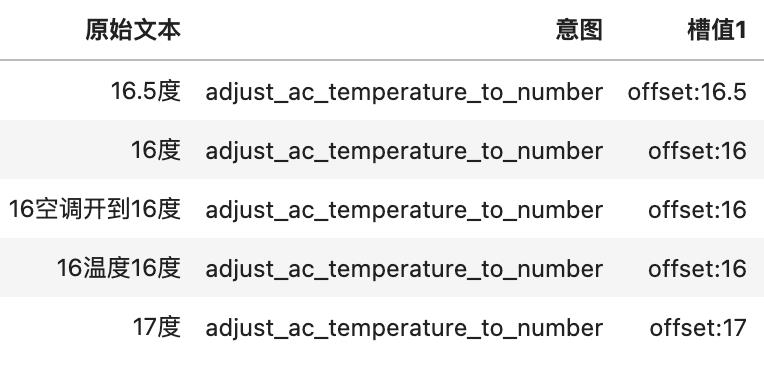
较多的中文语料和较少的多语种平行语料均带有意图分类和关键信息,选手需充分利用所提供数据,在英、日、阿拉伯语料的意图分类和关键信息抽取任务上取得较好效果。数据所含标签种类及取值类型如下表所示。
| 变量 | 数值格式 | 解释 |
|---|---|---|
| intent | string | 整句意图标签 |
| device | string | 操作设备名称标签 |
| mode | string | 操作设备模式标签 |
| offset | string | 操作设备调节量标签 |
| endloc | string | 目的地标签 |
| landmark | string | 周边搜索参照标签 |
| singer | string | 歌手 |
| song | string | 歌曲 |
评估指标
本模型依据提交的结果文件,采用accuracy进行评价。
意图分类意图正确数目总数据量
关键信息抽取关键信息完全正确数目总数据量
注:
每条数据的关键信息多抽或者少抽均算错误,最终得分取意图分类和关键信息抽取的平均值;
预测过程中不得进行语种转换,必须使用测试集提供的语种直接进行意图分类和关键信息抽取任务。
解题思路
意图分类为典型的文本任务;
信息抽取为实体抽取任务;
赛题任务有以下特点:
多语种文本,需要考虑多语种BERT;
短文本,可以尝试进行关键词匹配;
我们先使用TFIDF + 逻辑回归的思路来完成,后续也会继续分享使用BERT和关键词匹配的思路。
步骤1:导入库
import pandas as pd # 读取文件
import numpy as np # 数值计算
import nagisa # 日文分词
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征提取
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.pipeline import make_pipeline # 组合流水线步骤2:读取数据
# 读取数据
train_cn = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/中文_trian.xlsx')
train_ja = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/日语_train.xlsx')
train_en = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/英文_train.xlsx')
test_ja = pd.read_excel('testA.xlsx', sheet_name='日语_testA')
test_en = pd.read_excel('testA.xlsx', sheet_name='英文_testA')步骤3:文本分词
# 文本分词
train_ja['words'] = train_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
train_en['words'] = train_en['原始文本'].apply(lambda x: x.lower())
test_ja['words'] = test_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
test_en['words'] = test_en['原始文本'].apply(lambda x: x.lower())步骤4:构建模型
# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_ja['words'].tolist() + train_en['words'].tolist(),
train_ja['意图'].tolist() + train_en['意图'].tolist()
)
# 模型预测
test_ja['意图'] = pipline.predict(test_ja['words'])
test_en['意图'] = pipline.predict(test_en['words'])
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
# 写入提交文件
writer = pd.ExcelWriter('submit.xlsx')
test_en.drop(['words'], axis=1).to_excel(writer, sheet_name='英文_testA', index=None)
test_ja.drop(['words'], axis=1).to_excel(writer, sheet_name='日语_testA', index=None)
writer.save()
writer.close()关注Datawhale公众号,回复“NLP”可邀请进NLP赛事交流群,已在的不用再加入。

整理不易,点赞三连↓
以上是关于最新NLP赛事实践总结!的主要内容,如果未能解决你的问题,请参考以下文章