NLP 类问题建模方案探索实践
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP 类问题建模方案探索实践相关的知识,希望对你有一定的参考价值。
作者 | 林深
出品 | AI科技大本营(ID:rgznai100)
背景
NLP全称Neuro Linguistic Programming,一般翻译为自然语言处理,是一门研究计算机处理人类语言的技术,简单的说就是帮助计算机理解人类语言。常见的NLP类问题包括命名实体识别、文本分类、机器翻译、信息检索、语音识别、问答系统等等,种类繁多,应用领域也很广泛,是近些年来非常火的研究领域。
由于人类语言本身具有复杂性、多样性、歧义性等特点,导致NLP类问题成为一个开放性的研究课题,吸引了众多专家学者,创造了很多模型和理论,也给初学者们带来了比较大的挑战。
本文以kaggle平台上近期举办的Feedback Prize - Evaluating Student Writing比赛为例,使用NLP技术分析学生的议论文写作要素,直观感受NLP类问题的解析过程和建模方案,为初学者们提供帮助和参考。
数据准备
Evaluating Student Writing比赛目的是通过自动反馈工具,评估学生的写作并提供个性化反馈,参赛者需要通过构建模型,实现自动分割文本,并对文本中的辩论和修辞元素进行分类,因此比赛训练数据为6-12年级学生的作文,共15594篇文章,格式为txt英文文本,内容示例如图1所示。

图1 训练文本内容示例
训练样本的标注文件包括8个维度,分别代表文本编号(id)、辩论和修辞元素编号(discourse_id)、辩论和修辞元素开始位置(discourse_start)、辩论和修辞元素结束位置(discourse_end)、辩论和修辞元素文本(discourse_text),辩论和修辞元素类别(discourse_type),辩论和修辞元素类别数量(discourse_type_num),辩论和修辞元素文本单词索引(predictionstring),格式如图2所示。

图2 标注文件样例
构建的模型需要能够从文本内容中划分出辩论和修词元素,简称论述段(discourse),并且识别其类别,即需要得到论述段文本单词索引(predictionstring),以及类别(discourse_type)。对论述段类别进行统计,结果如图3所示,总共分为七类:Lead (导言)、Position(立场)、Claim(主张)、Counterclaim(反诉)、Rebuttal(反驳)、Evidence(证据)、Concluding Statement(结论性陈述),其中Claim(主张)和Evidence(证据)两类数量上占据主导地位。
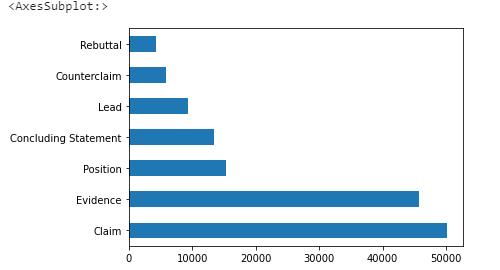
图3 辩论和修辞元素类别示例
比赛的评分函数是根据真实值和预测值词索引之间的重叠进行评估,如果真实值和预测值之间单词索引的重叠,以及预测值和真实值之间单词索引的重叠均大于等于0.5,则预测是匹配的,并被视为真正例(TP)。如果存在多个匹配项,则采用具有最高重叠对的匹配项。任何不匹配的真实值都被视为假负例(FN),任何不匹配的预测值都被视为假正例(FP)。通过计算每个类别的TP/FN/FN,然后计算所有类别的总分F1值。
明确目的和思路
解决NLP类问题首先需要明确目的和思路,先进行一些简单的可视化分析,从宏观角度观察文章的划分和分类情况。
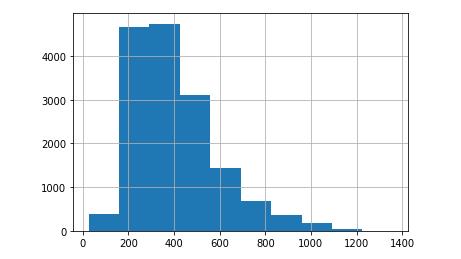
图3 文章的长度分布
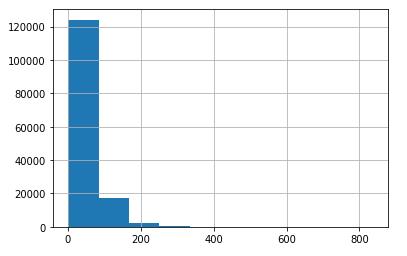
图4 论述段(discourse)的长度分布

图5 文章标注可视化
训练样本总共提供了15594篇文章及其标注,文章的平均长度大致在400个单词左右,划分的论述段平均长度大致在200个单词左右,类别有七类,数量有比较大的差异。通过以上简单的可视化分析,我们大致可以了解到自己的任务包括文本划分和文本分类两部分,接下来需要明确建模的思路。
最直观的一种思路是先把文本分割成句子,再对句子特征表示,也就是把文本编码成数值向量,然后对编码后的向量进行分类。这种思路常用的特征表示算法包括One-hot独热编码、BoW词袋编码、TF-IDF编码、Word2vec、Glove词向量等,常用的分类模型包括机器学习的NB朴素贝叶斯、SVM支持向量积、KNN K近邻、DT决策树、RF随机森林,以及深度学习的RNN、CNN、Attention、Transformer等等。
除此之外,通过对文章标注的可视化展示,让我们联想到了文本的序列标注,从而产生另一种思路,即使用命名实体识别的方法达到目标。命名实体识别(Named Entity Recognition,简称NER),是序列标注任务范畴中的一类,专指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,通常包括两部分,实体边界识别和确定实体类别,刚好类似题目中的论述段划分和分类。命名实体识别的常用算法包括传统的HMM、CRF以及近期的LSTM,BILSTM+CRF等等。
接下来本文分别采用两种思路的经典算法进行建模,帮助读者进一步理解NLP类问题的解决思路。
基于不同思路的建模流程
4.1 基于文本分类的建模
基于文本分类的建模,需要首先将文章划分为句子,针对训练样本,可以直接将标注文件中的每个论述段作为一个句子,针对测试样本,可以直接采用nltk工具包中的sent_tokenize方法进行划分。
接下来针对每一个句子进行特征表示,也就是将文本表示成计算机能够运算的数字或向量,先对常用的文本特征表示方法做一个简要概述。
One-hot独热编码:基于全部文本建立一个维度为n的单词库,对其中的每个单词赋予一个数值,通常是索引,再将文本中的每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其余元素都是0,不同词汇元素为1的位置不同。这种表示方式最大的缺点在于会生成巨大的稀疏矩阵,效率低下。
BoW词袋编码:忽略文本的词序和语法、句法,仅仅将其看作是一些词汇的集合,赋值用每个词汇出现的次数。词袋模型也有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。
TF-IDF编码:主要思想为字词的重要性随着它在文件中的次数成正比,与在语料库中出现的频率成反比。TF描述词频,即该词语在当前文档中出现的次数与当前文档的总次数的比值,IDF描述逆向性文件频率,即文档总数与出现该词语的文档数的比值取对数。TF-IDF编码的问题在于同样没有考虑上下文的关系。
Word2vec:Word2vec与以上几种编码方式最大的不同在于被它编码得到的向量并不是随便生成的,而是能够体现这些单词之间的关系(如相似性等)。Word2vec本质上是一种词嵌入方法(Word Embedding),即利用神经网络,通过训练大量文本的方式,将单词从高维空间映射到低维空间,生成数值向量,同时向量间的余弦或内积可以用来描述单词间的相似性。Word2Vec有两种模型可以使用,连续词袋(CBOW)模型和跳字(Skip-gram)模型,二者都是三层的神经网络,区别在于前者根据上下文预测中间词,后者根据中间词预测上下文,可以根据需要选择使用,CBOW的模型使用的更多一些,两个模型的网络结构如图6所示。
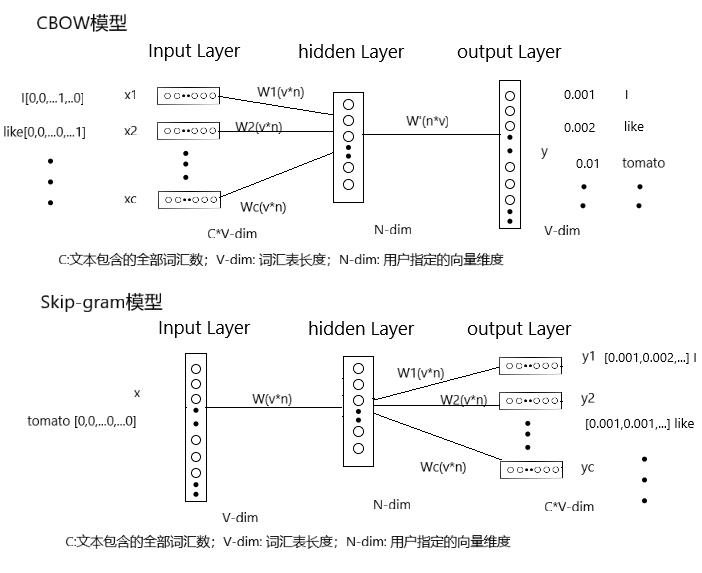
图6 CBOW模型和Skip-gram模型结构示意图
CBOW模型根据上下文预测中间词,所以输入便是上下文词,当然原始的单词是无法作为输入的,这里的输入仍然是每个词汇的one-hot向量(例如:I[0,0,...1,...0]、like[0,0,...0,...1]),输出为给定词汇表中每个词作为目标词的概率(例如:I:0.001、like:0.002、tomato:0.01、...)。
Skip-gram模型根据中间词预测上下文词,所以输入是任意单词(例如:tomato[0,0,...0,...0]),输出为给定词汇表中每个词作为上下文词的概率(例如:I[0.001,0.002,...]、like[0.001,0.001,...])。
模型训练完毕后,最后得到的其实是神经网络的权重矩阵W(W1,W2...Wc用于区分单词,实际所有单词使用共享的权重W),输入单词与权重相乘,即得到每个单词的向量编码(N维)。
Glove:Word2vec编码,是通过训练神经网络对上下文来进行预测获得,使用了局部规律,未使用全局的统计规律,缺乏全局的信息。而Glove则引入了全局信息,通过对’词-词’共现矩阵进行分解得到单词的向量编码,计算更简单,可以加快模型的训练速度。简单的说,Glove是一种全局的对数线性回归模型,目标函数采用带权重的最小二乘法,基于‘词-词’ 共现次数统计来训练。
了解了基础的文本编码方法,我们就可以对训练数据的单词进行编码处理,由于分类基于句子进行,所以句子的编码为句子中单词编码值的加和求平均。本文中针对每一个论述段(discorse)计算得到一个编码向量,维度自定义,每个论述段所对应的discourse_type即为需要预测的类别标签。
得到句子编码后就可以选择分类模型进行句子的分类,本文使用支持向量机(SVM)模型举例,原理不再赘述,使用不同编码方式+SVM的分类结果如下表所示:
| 编码类别 | 特征维度 | 分类模型 | 运行时间 | F1-core |
| BoW词袋编码 | 200 | SVM模型 | 39.7 | 0.112 |
| TF-IDF编码 | 200 | SVM模型 | 48.4 | 0.154 |
| Word2vec | 200 | SVM模型 | 1740.3 | 0.169 |
表1 不同编码方式的分类结果对比
在其他变量一致的情况下,Word2vec的分类效果最好,但是运行时间最长,因为神经网络的训练比较花费时间。如果想达到更好的分类效果,可以考虑继续增加Word2wec的迭代轮数,或者增加使用的特征维度,本文中只迭代了5轮。
4.2 基于命名实体识别的建模
基于命名实体识别的建模相对复杂一些,需要对每个单词进行标注,所以需要先进行数据预处理,将提供的训练文本和标注文件整理成序列标注的格式,其中每一篇文章作为一个序列。模仿BIO三位序列标注法(B-begin,I-inside,O-outside),对于在论述段中的单词,根据所属类别和单词位置,标记为B-type,和I-type,对于不在论述段中的单词,标记为O,标注结果如图7所示。
 图7 文本序列标注结果
图7 文本序列标注结果
然后对文本内容进行简单数值化,同时由于文本文件的长度不一,需要先进行补齐操作,将所有文本文件切分成指定长度MAX_LEN,长度不够的进行补0操作。根据前期对论述段长度的分析,MAX_LEN的值取为200,同时注意保存文本的原始长度,方便后期处理,补齐后的文本如图8所示。
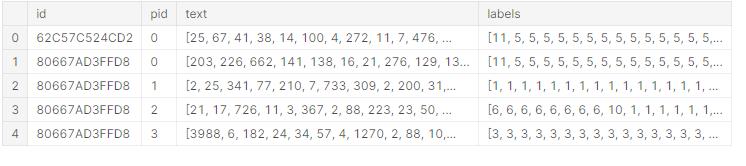 图8 不定长文本补齐
图8 不定长文本补齐
文本标注完毕后,就可以进行相应训练,接下来以LSTM网络模型为例,简述建模流程。
LSTM名为长短期记忆网络,作为一种改进之后的循环神经网络,不仅能够解决 RNN无法处理长距离的依赖的问题,还能够解决神经网络中常见的梯度爆炸或梯度消失等问题,在处理序列数据方面非常有效,如图9所示。每一个单词,转化成向量输入LSTM网络,经过计算后输出一个包括全部标签大小的概率向量,通过SoftMax,挑选概率最大的标签,为预测的结果,跟真实值对比,误差反向传播更新模型。
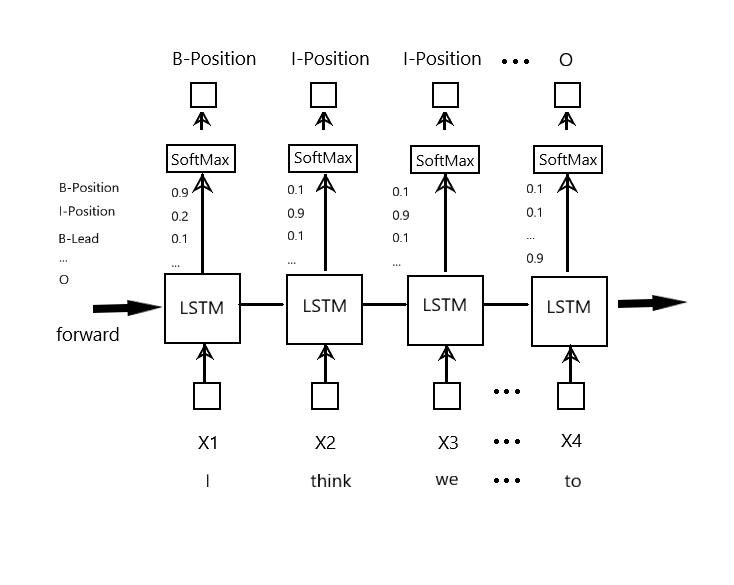 图9 基于LSTM的命名实体识别
图9 基于LSTM的命名实体识别
在使用LSTM模型进行命名实体识别时,有一些关键点要注意。首先是文本编码,因为LSTM的输入要求是向量,所以本文在LSTM模型中增加了Embedding层,也就是一个词表大小*用户指定维度的矩阵,提前对文本使用Word2vec的方法进行预训练,然后将得到的权重矩阵赋值给LSTM的Embedding,这样输入LSTM的单词就会转化为指定维度的向量。其次因为进行了不定长序列补齐的操作,在训练时要注意进行序列的压缩和解压缩,保持维度一致。再次如果分批次训练,每训练一个batch都需要将梯度归零,因为每个batch都是独立训练地。最后得到预测序列后还要将结果的格式调整成句子+类别的格式。
结论和展望
对比文本分类和命名实体识别两种建模思路的得分结果如下表所示:
| 建模思路 | 特征维度 | 分类模型 | 运行时间 | F1-core |
| 文本分类 | 200 | Word2vec+SVM模型 | 1740.3 | 0.169 |
| 命名实体识别 | 100 | Word2vec+LSTM模型 | 1479.4 | 0.046 |
表2 两种建模思路的结果对比
虽然从表2中发现文本分类的效果明显优于命名实体识别,但是不能就此判断命名实体识别的方法就没有价值,因为可能是模型选择不合适或者训练不够充分导致的,进一步优化后会有改善。在实际比赛中,优胜者队伍就是基于命名实体识别的思路,使用多个训练模型进行加权融合,最终F1-score得分能超过0.72。
因此在解决NLP类问题时,多尝试不同的思路和方案,对初学者的能力提升具有很大的帮助。
作者曾就职于农业银行研发中心,10年+软件研发,负责运营领域相关系统研发。多年专注AI 算法领域。
分享
点收藏
点点赞
点在看以上是关于NLP 类问题建模方案探索实践的主要内容,如果未能解决你的问题,请参考以下文章