SSD: Single Shot MultiBox Detector
Posted 07H_JH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SSD: Single Shot MultiBox Detector相关的知识,希望对你有一定的参考价值。
有参考:http://blog.csdn.net/u010167269/article/details/52563573
SSD: Single Shot MultiBox Detector
By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg.
Introduction
SSD is an unified framework for object detection with a single network. You can use the code to train/evaluate a network for object detection task. For more details, please refer to our arXiv paper.
| System | VOC2007 test mAP | FPS (Titan X) | Number of Boxes |
|---|---|---|---|
| Faster R-CNN (VGG16) | 73.2 | 7 | 300 |
| Faster R-CNN (ZF) | 62.1 | 17 | 300 |
| YOLO | 63.4 | 45 | 98 |
| Fast YOLO | 52.7 | 155 | 98 |
| SSD300 (VGG16) | 72.1 | 58 | 7308 |
| SSD300 (VGG16, cuDNN v5) | 72.1 | 72 | 7308 |
| SSD500 (VGG16) | 75.1 | 23 | 20097 |
Citing SSD
Please cite SSD in your publications if it helps your research:
@articleliu15ssd,
Title = SSD: Single Shot MultiBox Detector,
Author = Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C.,
Journal = arXiv preprint arXiv:1512.02325,
Year = 2015
Contents
Installation
-
Get the code. We will call the directory that you cloned Caffe into
$CAFFE_ROOTgit clone https://github.com/weiliu89/caffe.git cd caffe git checkout ssd -
Build the code. Please follow Caffe instruction to install all necessary packages and build it.
# Modify Makefile.config according to your Caffe installation. cp Makefile.config.example Makefile.config make -j8 # Make sure to include $CAFFE_ROOT/python to your PYTHONPATH. make py make test -j8 make runtest -j8 # If you have multiple GPUs installed in your machine, make runtest might fail. If so, try following: export CUDA_VISIBLE_DEVICES=0; make runtest -j8 # If you have error: "Check failed: error == cudaSuccess (10 vs. 0) invalid device ordinal", # first make sure you have the specified GPUs, or try following if you have multiple GPUs: unset CUDA_VISIBLE_DEVICES
Preparation
-
Download fully convolutional reduced (atrous) VGGNet. By default, we assume the model is stored in
$CAFFE_ROOT/models/VGGNet/ -
Download VOC2007 and VOC2012 dataset. By default, we assume the data is stored in
$HOME/data/# Download the data. cd $HOME/data wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar # Extract the data. tar -xvf VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_06-Nov-2007.tar tar -xvf VOCtest_06-Nov-2007.tar
-
Create the LMDB file.
cd $CAFFE_ROOT # Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/ ./data/VOC0712/create_list.sh # You can modify the parameters in create_data.sh if needed. # It will create lmdb files for trainval and test with encoded original image: # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb # and make soft links at examples/VOC0712/ ./data/VOC0712/create_data.sh
Train/Eval
-
Train your model and evaluate the model on the fly.
# It will create model definition files and save snapshot models in: # - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/ # and job file, log file, and the python script in: # - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/ # and save temporary evaluation results in: # - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/ # It should reach 72.* mAP at 60k iterations. python examples/ssd/ssd_pascal.py
If you don't have time to train your model, you can download a pre-trained model at here.
-
Evaluate the most recent snapshot.
# If you would like to test a model you trained, you can do: python examples/ssd/score_ssd_pascal.py -
Test your model using a webcam. Note: press esc to stop.
# If you would like to attach a webcam to a model you trained, you can do: python examples/ssd/ssd_pascal_webcam.pyHere is a demo video of running a SSD500 model trained on MSCOCO dataset.
-
Check out
examples/ssd_detect.ipynborexamples/ssd/ssd_detect.cppon how to detect objects using a SSD model. -
To train on other dataset, please refer to data/OTHERDATASET for more details. We currently add support for MSCOCO and ILSVRC2016.
Models
Preface
这是今年 ECCV 2016 的一篇文章,是 UNC Chapel Hill(北卡罗来纳大学教堂山分校) 的 Wei Liu 大神的新作,论文代码:https://github.com/weiliu89/caffe/tree/ssd
Obeject detection summary link: Object Detection
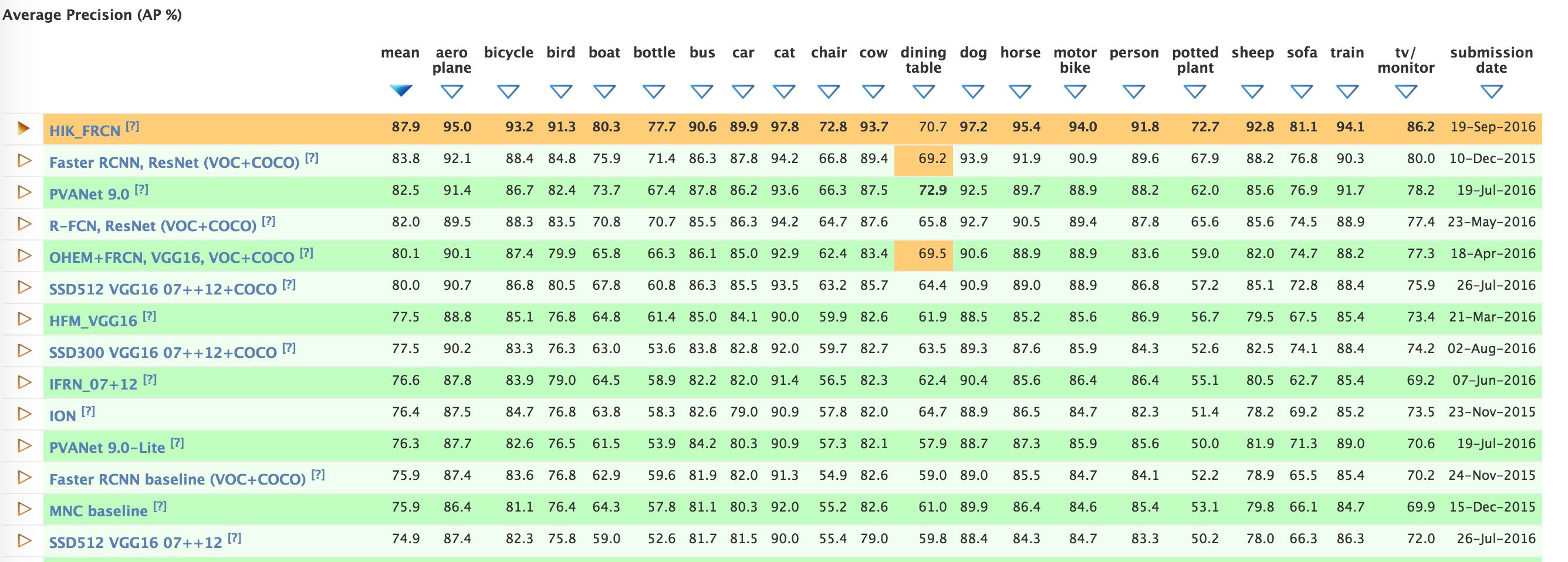
目前 voc 2012 的榜单:
Abstract
这篇文章在既保证速度,又要保证精度的情况下,提出了 SSD 物体检测模型,与现在流行的检测模型一样,将检测过程整个成一个 single deep neural network。便于训练与优化,同时提高检测速度。SSD 将输出一系列 离散化(discretization) 的 bounding boxes,这些 bounding boxes 是在 不同层次(layers) 上的 feature maps 上生成的,并且有着不同的 aspect ratio。
在 prediction 阶段:
-
要计算出每一个 default box 中的物体,其属于每个类别的可能性,即 score,得分。如对于 PASCAL VOC 数据集,总共有 20 类,那么得出每一个 bounding box 中物体属于这 20 个类别的每一种的可能性。
-
同时,要对这些 bounding boxes 的 shape 进行微调,以使得其符合物体的 外接矩形。
-
还有就是,为了处理相同物体的不同尺寸的情况,SSD 结合了不同分辨率的 feature maps 的 predictions。
相对于那些需要 object proposals 的检测模型,本文的 SSD 方法完全取消了 proposals generation、pixel resampling 或者 feature resampling 这些阶段。这样使得 SSD 更容易去优化训练,也更容易地将检测模型融合进系统之中。
在 PASCAL VOC、MS COCO、ILSVRC 数据集上的实验显示,SSD 在保证精度的同时,其速度要比用 region proposals 的方法要快很多。
SSD 相比较于其他单结构模型(YOLO),SSD 取得更高的精度,即是是在输入图像较小的情况下。如输入 300×300 大小的 PASCAL VOC 2007 test 图像,在 Titan X 上,SSD 以 58 帧的速率,同时取得了 72.1% 的 mAP。
如果输入的图像是 500×500 ,SSD 则取得了 75.1% 的 mAP,比目前最 state-of-art 的 Faster R-CNN 要好很多。
Introduction
现金流行的 state-of-art 的检测系统大致都是如下步骤,先生成一些假设的 bounding boxes,然后在这些 bounding boxes 中提取特征,之后再经过一个分类器,来判断里面是不是物体,是什么物体。
这类 pipeline 自从 IJCV 2013, Selective Search for Object Recognition 开始,到如今在 PASCAL VOC、MS COCO、ILSVRC 数据集上取得领先的基于 Faster R-CNN 的 ResNet 。但这类方法对于嵌入式系统,所需要的计算时间太久了,不足以实时的进行检测。当然也有很多工作是朝着实时检测迈进,但目前为止,都是牺牲检测精度来换取时间。
本文提出的实时检测方法,消除了中间的 bounding boxes、pixel or feature resampling 的过程。虽然本文不是第一篇这样做的文章(YOLO),但是本文做了一些提升性的工作,既保证了速度,也保证了检测精度。
这里面有一句非常关键的话,基本概括了本文的核心思想:
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
本文的主要贡献总结如下:
-
提出了新的物体检测方法:SSD,比原先最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
-
SSD 方法的核心就是 predict object(物体),以及其 归属类别的 score(得分);同时,在 feature map 上使用小的卷积核,去 predict 一系列 bounding boxes 的 box offsets。
-
本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
-
本文的这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体 end-to-end 的设计,训练也变得简单。在检测速度、检测精度之间取得较好的 trade-off。
-
本文提出的模型(model)在不同的数据集上,如 PASCAL VOC、MS COCO、ILSVRC, 都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前物体检测领域 state-of-art 的检测方法进行了比较。
The Single Shot Detector(SSD)
这部分详细讲解了 SSD 物体检测框架,以及 SSD 的训练方法。
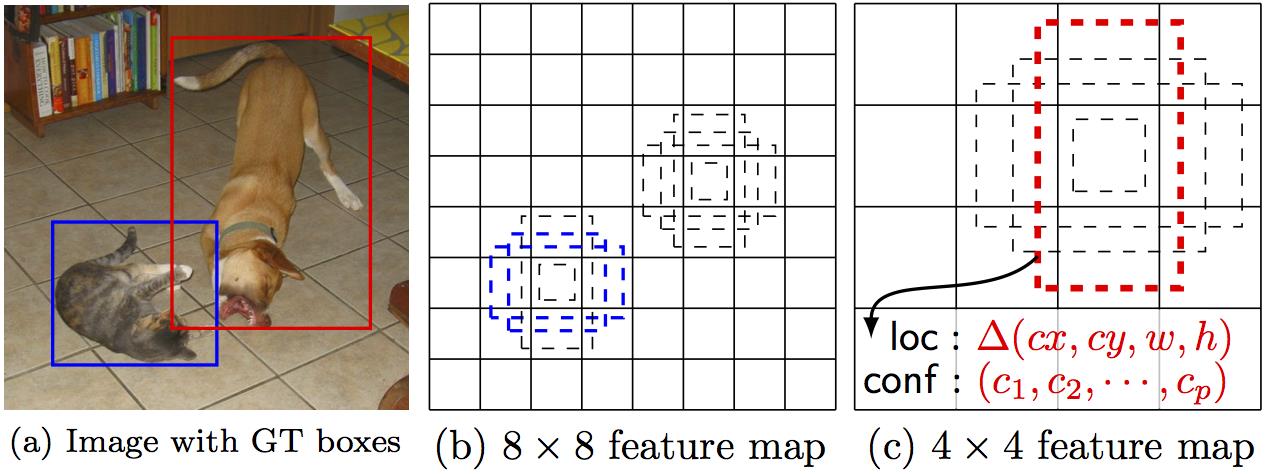
这里,先弄清楚下文所说的 default box 以及 feature map cell 是什么。看下图:
-
feature map cell 就是将 feature map 切分成 8×8 或者 4×4 之后的一个个 格子;
-
而 default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。
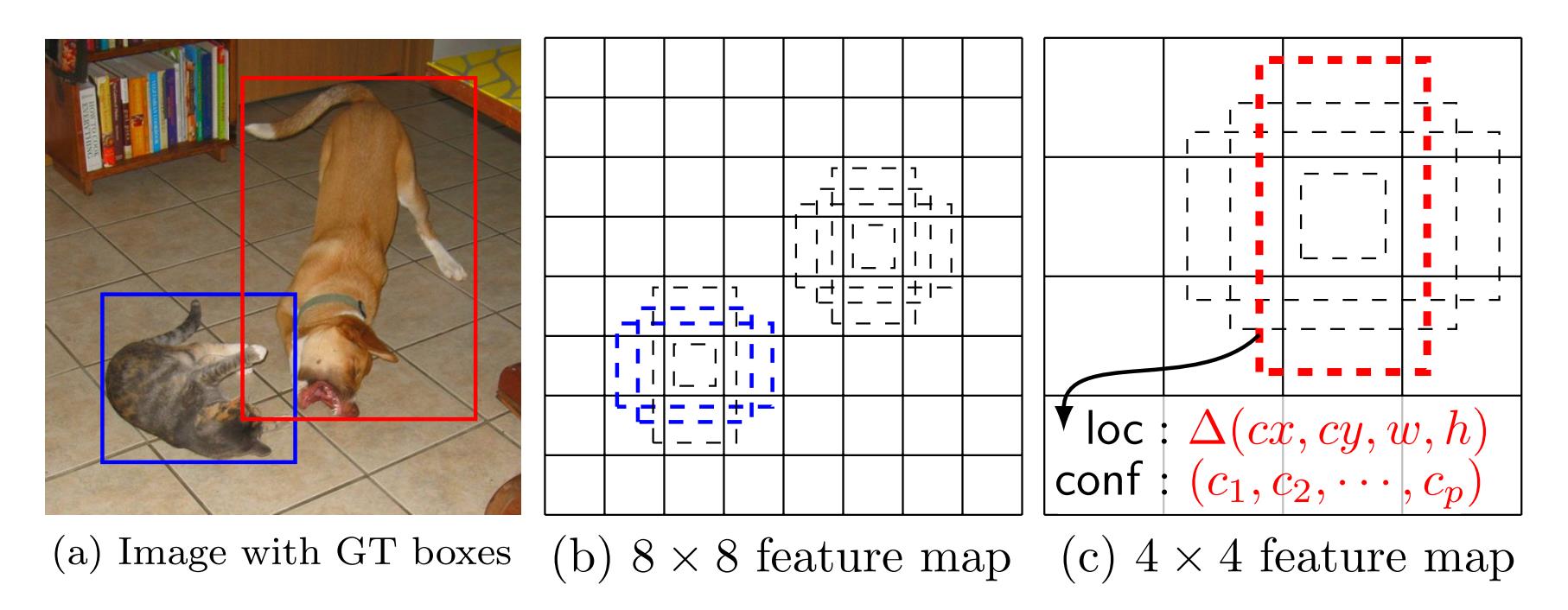
Model
SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个 非极大值抑制(Non-maximum suppression) 得到最终的 predictions。
SSD 模型的最开始部分,本文称作 base network,是用于图像分类的标准架构。在 base network 之后,本文添加了额外辅助的网络结构:
-
Multi-scale feature maps for detection
在基础网络结构后,添加了额外的卷积层,这些卷积层的大小是逐层递减的,可以在多尺度下进行 predictions。 -
Convolutional predictors for detection
每一个添加的特征层(或者在基础网络结构中的特征层),可以使用一系列 convolutional filters,去产生一系列固定大小的 predictions,具体见 Fig.2。对于一个大小为 m×n ,具有 p 通道的特征层,使用的 convolutional filters 就是 3×3×p 的 kernels。产生的 predictions,那么就是归属类别的一个得分,要么就是相对于 default box coordinate 的 shape offsets。
在每一个 m×n 的特征图位置上,使用上面的