Python爬虫_Scrapy
Posted 敷衍zgf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫_Scrapy相关的知识,希望对你有一定的参考价值。
Python爬虫_Scrapy
一、Scrapy简述
是为了爬取网站数据,提取结构性数据而编写的应用框架,可应用在包括数据挖掘、信息处理或存储历史数据等一系列程序中
(一)安装
pip install scrapy -i https://pypi.douban.com/simple
报错:
WARNING: You are using pip version 21.3.1; however, version 22.1.2 is available.
You should consider upgrading via the 'D:\\PythonCode\\venv\\Scripts\\python.exe -m pip install --upgrade pip' command.
解决办法:运行python -m pip install --upgrade pip
(二)基本使用
- 创建爬虫项目:
scrapy startproject scrapy_baidu_01
注意:
(1)必须要进入到安装有scrapy.exe文件夹中才可运行;
(2)创建的爬虫项目名字不允许用数字开头,也不能包含中文
(3)务必配置scrapy.exe的环境变量,同时重启电脑在运行D:\\P ythonCode\\venv\\Scripts - 创建爬虫文件 在spider文件夹中去创建
D:\\PythonCode\\venv\\Scripts\\scrapy_baidu_01\\scrapy_baidu_01\\spiders>
创建指令:scrapy genspider 爬虫文件名字 要爬取的网页 - 运行爬虫代码
scrapy crawl 爬虫的名字名字是[name = ‘baidu’]
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字,使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['www.baidu.com']
# 起始的url地址 第一次要访问的域名
# start_urls实在allowed_domains的前面添加一个http://,在后面添加了/
start_urls = ['http://www.baidu.com/']
# 执行了start_urls之后执行的方法,方法中的response是返回的对象,相当于
# response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('ssssss')
二、58同城项目案例
1. scrapy项目的结构
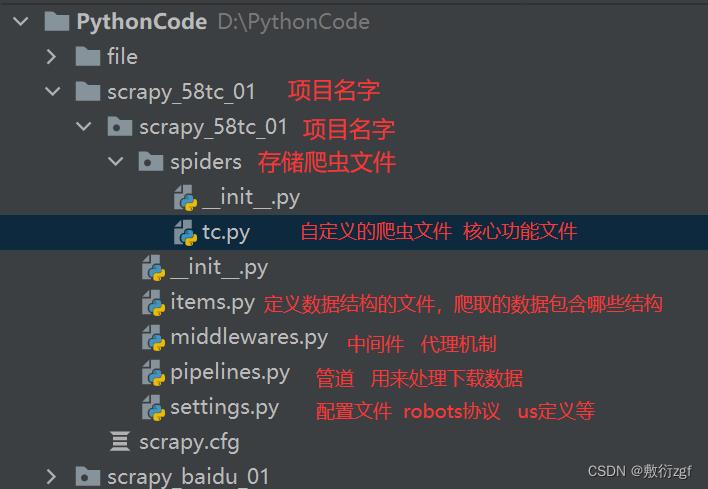
2. response的属性和方法
response.text获取的是响应的字符串
response.body获取二进制数据
response.xpath可以直接使用xpath方法来解析response中的内容
response.extract() 用于提取seletor对象中的data属性值
response.extract_first() 提取seletor列表的第一个数据
三、汽车之家案例
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['car.autohome.com.cn/price/brand-15.html']
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
price(name,price)
scrapy工作原理【灰常重要!!】
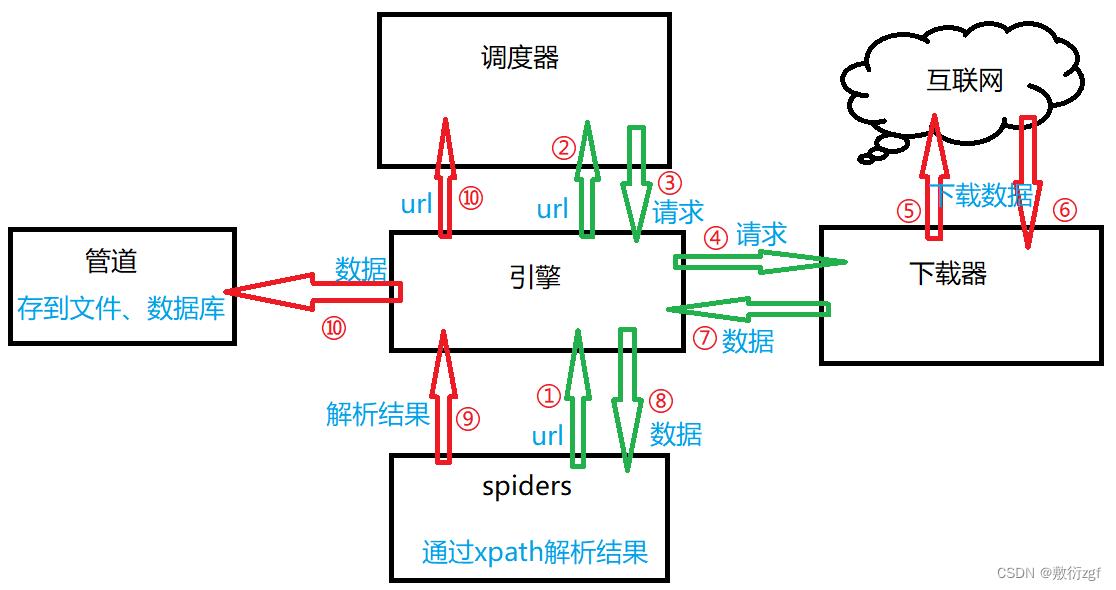
- 引擎向spiders请求url;
- 引擎将请求得到的url传递给调度器
- 调度器将url生成的请求对象放入指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次交给spiders
- spiders通过xpath解析该数据,得到数据或者url
- spiders将解析结果交给引擎
- 若解析结果是数据,则交给管道处理;若解析结果是url,则交给调度器进入下一次循环。
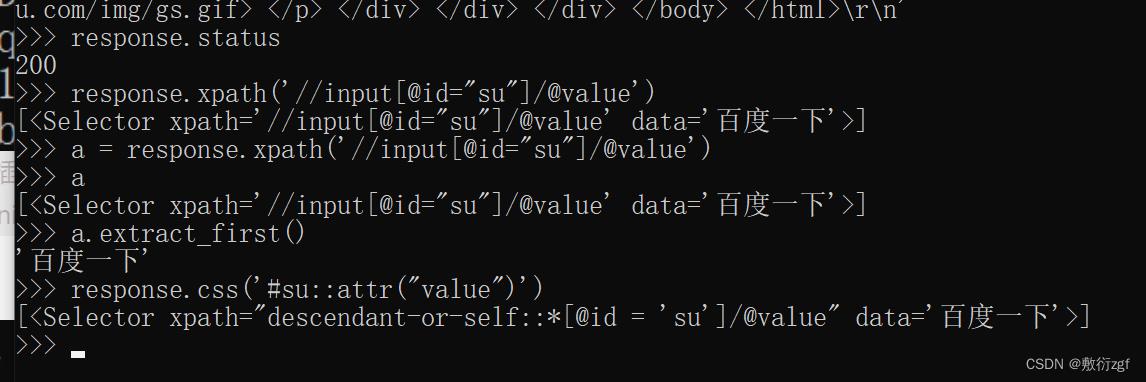
四、scrapy shell

直接输入指令:scrapy shell www.baidu.com


以上是关于Python爬虫_Scrapy的主要内容,如果未能解决你的问题,请参考以下文章