浅谈redis——单机版redis特性记录
Posted 敲代码的小小酥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈redis——单机版redis特性记录相关的知识,希望对你有一定的参考价值。
前言
先上官方文档地址:redis官方文档。讲解很齐全。
博主一直以来都在做小型的传统项目,因此,在实战中用redis的机会很少。再加上redis篇幅庞大,因此,在学习redis的过程中,博主一度迷茫,纠结细节知识和实操到底要不要学。在一阵迷茫过后,想到平时永不到的东西,即使操作一边,过段时间也就忘得一干二净了,所以没必要在实操上花费时间。学习其中的思想和套路,理解其原理,等真正用上的时候,再实操也为时不晚。因此,本系列博客记录学习redis的心得体会和一些原理观念,熟悉redis的特性和应用场景。
一、redis概述
redis作为一个用C语言开发出的非关系型数据库,官方报道可以支持的读写性能可以达到10万/秒次。我们常说redis是单线程,这里说的单线程是redis执行客户端命令时,采用单线程的方式,不管哪个客户端往服务端发送命令,都会排队,单线程执行。而不是说redis的所有功能,都是单线程。比如日志持久化,集群数据复制等等,都会开启新线程执行。
对于redis的版本选择,在 Redis 的版本计划中,版本号第二位为奇数,为非稳定版本,如 2.7、2.9、 3.1;版本号第二为偶数,为稳定版本如 2.6、2.8、3.0;一般来说当前奇数版本 是下一个稳定版本的开发版本,如 2.9 是 3.0 的开发版本。
对于redis常用命令,博主就不再进行记录。正如前言中所言,没有实战应用,简单写一遍命令过段时间也忘得一干二净。在实操中用到哪个命令了,网上搜索使用即可。
二、redis常用数据类型
redis的key都是字符串类型,这里的数据类型指value的数据类型。
String类型:
最基本的数据类型。字符串,数字(整数、浮点数),甚至是二进制(图片、音频、 视频)都是String类型。最大不超过512MB。
hash类型:
value是一个键值对。可以存储对象类型的数据。其数据结构为:key field value。其中 field value相当于一个大的value。在操作hash类型数据时,都是通过key找到field,然后操作value的值。如:
hset person name 张三;
hset person age 18;
hget person name;
hget person age;
list类型:
list类型用来存储多个有序字符串,redis提供了对list两端插入(push)和弹出(pop),还可以获取指定范围的元素列表,获取指定索引下标的元素。list可以充当栈和队列,在实际开发中可以灵活运用。list中的元素允许有重复值。
set类型:
set类型也是存放多个元素,但是与list不同的是,set类型元素不重复,且是无序的。不能通过下标获取元素。
zet类型:
有序的set类型。通过分数进行排序。插入数据的时候需要设置分数。
三、GEO特性
redis3.2以后版本有此功能,主要用于进行地理位置的计算等操作。如附近的人,外卖距离等等功能会用到。这里不做详解,知道有这个特性即可。用到的时候再做详细研究。
四、pipeline管道技术
正常情况下,redis客户端发送命令到服务端,再获取返回结果的流程如下:
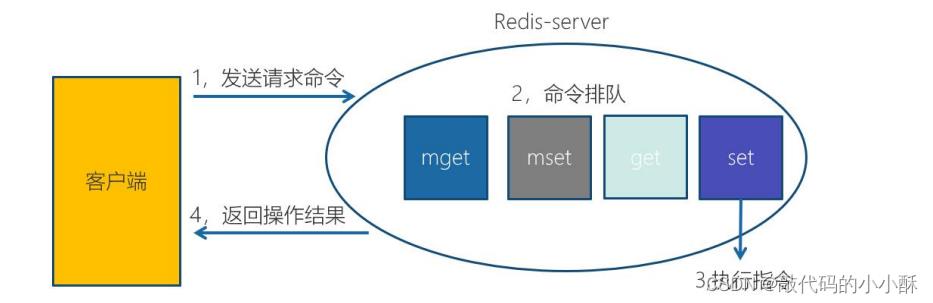
其中,说的redis的单线程,就是执行排队的命令时,是单线程。所以,无论多少客户端发过来的命令,都要在这里排队执行。这也就避免了一些并发问题。所以常用redis来做分布式锁。
上图中从步骤1到步骤4称为一个RTT。Redis 提供了批量操作命令(例如 mget、mset 等),有效地节约 RTT。但大部 分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 命 令存在,需要消耗 n 次 RTT。
这就造成了redis性能的严重瓶颈。为了解决这个问题,redis使用了pipeline机制。将一组 Redis 命令进行组装, 通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端,使用 Pipeline 执行了 n 次命令,整个过程需要 1 次 RTT。
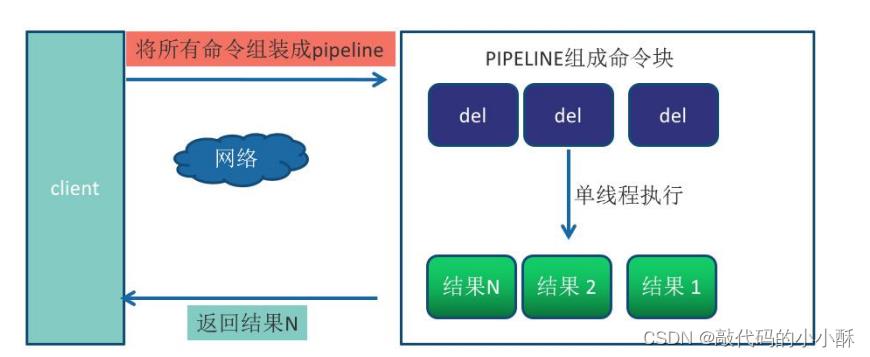
Pipeline 虽然好用,但是每次 Pipeline 组装的命令个数不能没有节制,否则一 次组装 Pipeline 数据量过大,一方面会增加客户端的等待时间,另一方面会造成 一定的网络阻塞,可以将一次包含大量命令的 Pipeline 拆分成多次较小的 Pipeline 来完成,比如可以将 Pipeline 的总发送大小控制在内核输入输出缓冲区大小之内 或者控制在 TCP 包的大小 1460 字节之内。
我们通常使用客户端来操作Pipeline。使用jedis客户端操作pipeline的代码如下:
@Component
public class RedisPipeline
@Autowired
private JedisPool jedisPool;
public List<Object> plGet(List<String> keys)
Jedis jedis = null;
try
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for(String key:keys)
pipelined.get(key);
return pipelined.syncAndReturnAll();
catch (Exception e)
throw new RuntimeException("执行Pipeline获取失败!",e);
finally
jedis.close();
public void plSet(List<String> keys,List<String> values)
if(keys.size()!=values.size())
throw new RuntimeException("key和value个数不匹配!");
Jedis jedis = null;
try
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for(int i=0;i<keys.size();i++)
pipelined.set(keys.get(i),values.get(i));
pipelined.sync();
catch (Exception e)
throw new RuntimeException("执行Pipeline设值失败!",e);
finally
jedis.close();
五、事务与Lua脚本
redis提供了弱事务特性,之所以称之为弱事务,是因为其不支持回滚。具体如下:
到 multi 和 exec 两个命令之间。multi(['mʌlti]) 命令代表事务开始,exec(美[ɪɡˈzek])命令代表事务结 束,如果要停止事务的执行,可以使用 discard 命令代替 exec 命令即可。
在multi和exec命令之间的命令,并不会第一时间执行,而是放入一个队列中,当执行完exec命令后,这个队列中的命令才会执行。这么做保证了这些命令的原子性。当这些命令能顺利完成时,这个事务是没问题的。但是当中间某个命令执行出错时,redis不会对已经执行成功的命令进行回滚。
所以,redis事务在保证执行成功的基础上,可以进行一些原子性操作。
而保证命令的原子性操作,更常用的技术是使用Lua脚本。将redis的命令写入lua脚本中,执行这个脚本文件,那么,脚本文件中的这些命令,会保持原子性。redis执行lua脚本,类似于mysql数据库执行存储过程差不多。
redis实现分布式锁,就是利用了lua脚本来保证命令的原子性。
六、订阅/发布模式
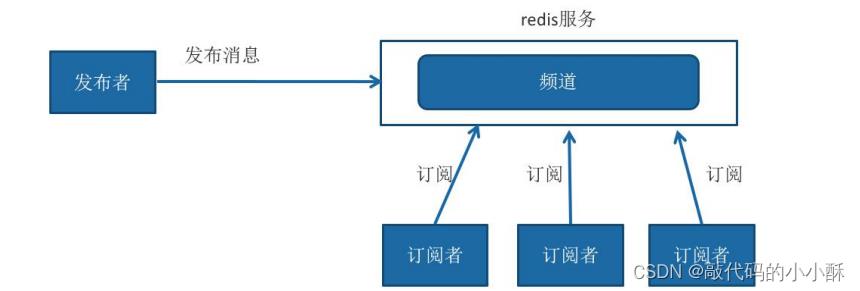
发布消息
publish channel message

返回值是接收到信息的订阅者数量。
订阅消息
subscribe channel [channel ...]
订阅者可以订阅一个或多个频道,如果此时另一个客户端发布一条消息,当 前订阅者客户端会收到消息。 如果有多个客户端同时订阅了同一个频道,都会收到消息。
更多相关操作,请查看笔记或其他博客。
redis的此种订阅发布模式,并不会存储信息。当生产者发送消息后,如果没有消费者订阅频道,消息就丢失了。而且也没有什么ack机制。所以,redis的订阅/发布模式可用于一些消息可靠性不重要的业务场景中,用于解耦 应用时使用。
七、Redis Stream
在redis5.0之后,提供了Stream功能。它是一个新的强大的 支持多播的可持久化的消息队列,作者声明 Redis Stream借鉴了 Kafka 的设计。所以,可以在redis stream中,到处可见kafka设计的影子。
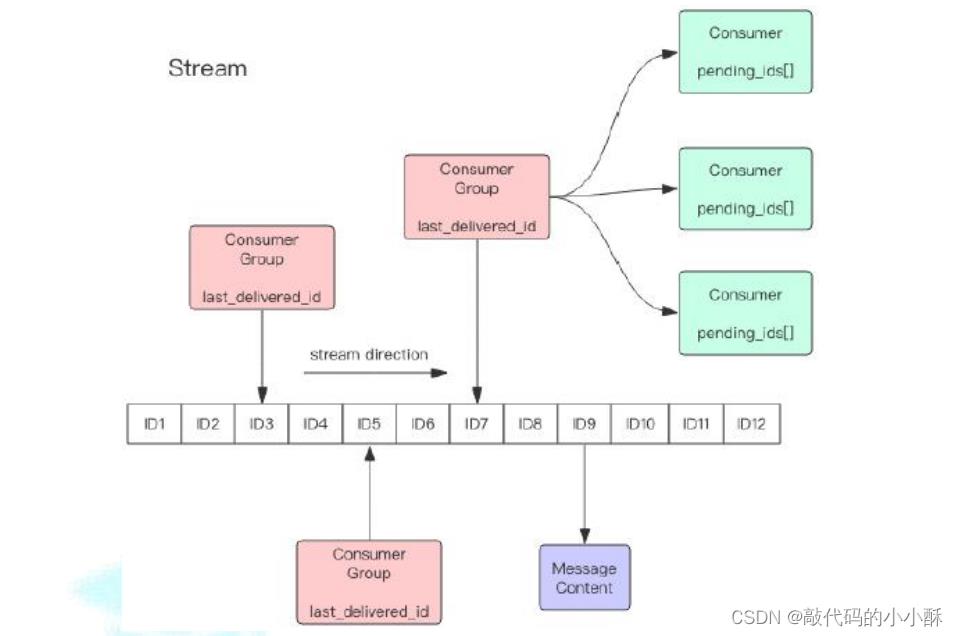
上图就是stream的一个工作流程。每个stream都有一个消息链表。将所有加入 的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。消息是持久化的, Redis 重启后,内容还在。这就相当于是kafka中的topic和其数据文件。
stream也有消费者群组的概念,消费者群组中有多个消费者,和kafka的原理一致。这里不再过多赘述,理解kafka的原理即可。
知道redis有stream机制即可。真正使用消息队列,还是建议使用专业的MQ进行。现在使用redis做MQ的实践不多,不要冒险使用。
八、持久化
8.1 RDB
RDB:生成快照(*.rdb)文件,一次性生成,有手动生成和自动生成两种。
手动触发:
save 命令:阻塞当前 Redis 服务器,直到 RDB 过程完成为止,对于内存比较 大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave 命令:Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程 负责,完成后自动结束。阻塞只发生在 fork 阶段,一般时间很短。
显然 bgsave 命令是针对 save 阻塞问题做的优化。因此 Redis 内部所有的涉 及 RDB 的操作都采用 bgsave 的方式。
自动触发:
1)使用 save 相关配置,如“save m n”。表示 m 秒内数据集存在 n 次修改时, 自动触发 bgsave。 在redis配置文件中配置。
2)如果从节点执行全量复制操作,主节点自动执行 bgsave 生成 RDB 文件并 发送给从节点。
3)执行 debug reload 命令重新加载 Redis 时,也会自动触发 save 操作。 4)默认情况下执行 shutdown 命令时,如果没有开启 AOF 持久化功能则自 动执行 bgsave。
RDB 文件保存在 dir 配置指定的目录下,文件名通过 dbfilename 配置指定。 可以通过执行 config set dir newDir和 config set dbfilename (newFileName运行期 动态执行,当下次运行时 RDB 文件会保存到新目录。 Redis 默认采用 LZF 算法对生成的 RDB 文件做压缩处理,压缩后的文件远远 小于内存大小,默认开启,可以通过参数 config set rdbcompression yes |no动 态修改。
优点:
RDB 是一个紧凑压缩的二进制文件,代表 Redis 在某个时间点上的数据快照。 非常适用于备份,全量复制等场景。 比如每隔几小时执行 bgsave 备份,并把 RDB 文件拷贝到远程机器或者文件 系统中(如 hdfs),,用于灾难恢复。 Redis 加载 RDB 恢复数据远远快于 AOF 的方式
缺点:
RDB 方式数据没办法做到实时持久化/秒级持久化。因为 bgsave 每次运行都 要执行 fork 操作创建子进程,属于重量级操作,频繁执行成本过高。 RDB 文件使用特定二进制格式保存,Redis 版本演进过程中有多个格式的 RDB 版本,存在老版本
8.2AOF
以独立日志的方式记录每次写命令,重启时再重 新执行 AOF 文件中的命令达到恢复数据的目的。AOF 的主要作用是解决了数据 持久化的实时性,目前已经是 Redis 持久化的主流方式.
开启 AOF 功能需要设置配置:appendonly yes,默认不开启。AOF 文件名通过 appendfilename 配置设置,默认文件名是 appendonly.aof。保存路径同 RDB 持久 化方式一致,通过 dir 配置指定。AOF 的工作流程操作:命令写入( append)、文件 同步( sync)、文件重写(rewrite)、重启加载( load)。
aof日志重写机制:当aof命令足够大时,会触发重写。重写就是将多条命令合并,如lpush list a, lpush list b,lpush list c合并成lpush list a b c。来减少空间。
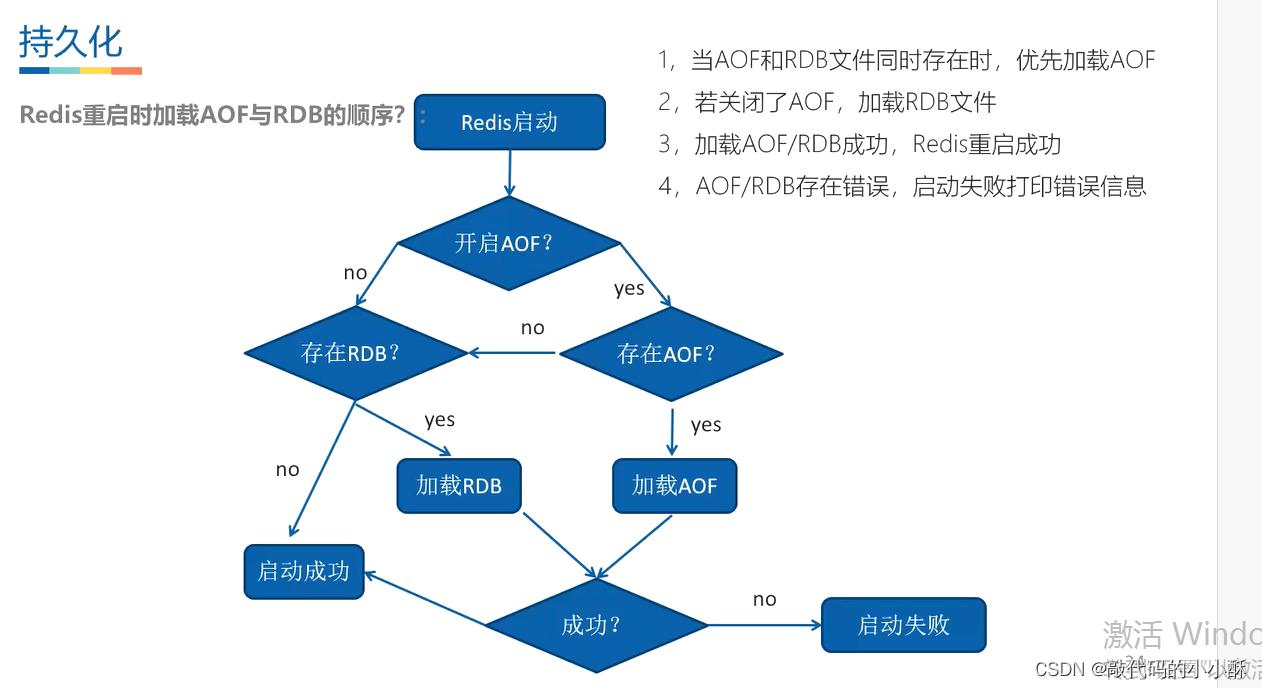
AOF和RDB的加载顺序如下:
以上是关于浅谈redis——单机版redis特性记录的主要内容,如果未能解决你的问题,请参考以下文章