Tensorflow 写给初学者的深度学习教程之 MNIST 数字识别
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow 写给初学者的深度学习教程之 MNIST 数字识别相关的知识,希望对你有一定的参考价值。
一般而言,MNIST 数据集测试就是机器学习和深度学习当中的"Hello World"工程,几乎是所有的教程都会把它放在最开始的地方.这是因为,这个简单的工程包含了大致的机器学习流程,通过练习这个工程有助于读者加深理解机器学习或者是深度学习的大致流程.
但恰恰有那么一部分同学,由于初入深度学习这个领域,脑海中还没有清晰的概念,所以即使是 MNIST 数字识别这样简单的例子,我觉得也应该有人稍微详细地讲解一下。
本文的目的就是用更耐心的方式去引导初学者理解深度学习的大致流程和操作技巧.
最核心的模型
无论是机器学习还是深度学习,都绕不过模型.深度学习中的模型主要是各种神经网络.
但只有模型是不够的,前提条件其实是数据,然后,后置的操作是训练,再之后是测试.
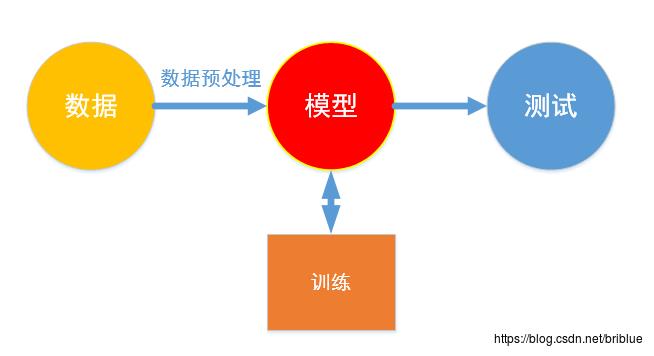
模型通过不断的训练从数据中学习,然后通过测试去验证模型的正确性.
MNIST 数字识别工程,也是为了确定一个模型,然后进行训练,训练过程中这个模型从大量的数字图片中学习得到识别手写数字的能力,最后,需要测试验证这个模型是否足够理想和优秀.
MNIST 数字识别项目,模型可以是传统的机器学习中的模型,也可以使用深度学习中的神经网络.在本文中,我使用的是 CNN,然后用的是 Python 和 Tensorflow.
MNIST 是什么?
MNIST 是一个小型的手写数字图片库,它总共有 60000 张图片,其中 50000 张训练图片,10000 张测试图片.每张图片的像素都是 28 * 28
MNIST 对应上图数据这一块,它需要导入到模型当中.
从数据到模型一般而言是需要转化的,这一步叫做数据预处理。Tensorflow 接受 Numpy 中的 ndarray ,所以要想办法进行转换.
它的官网地址如下:
http://yann.lecun.com/exdb/mnist/
数据库其实只由 4 个文件组成.

下载下来,然后分别解压缩,可以发现其实只是 4 个 bin 文件.
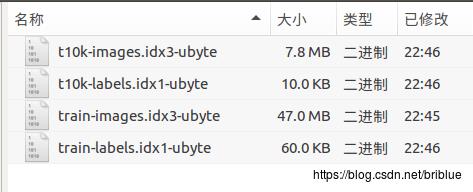
train-images.idx3-ubyte 包含了 50000 张训练图片.
train-labels.idx1-ubyte 包含了 50000 个标签.
t10k-images.idx3-ubyte 包含了 10000 张训练图片.
t10k-labels.idx1-ubyte 包含了 10000 个标签.
在这里有一点,非常重要,MNIST 将需要图片或者标签全部写入到一个 bin 文件当中去了,如果要读取某张图片和对应的标签值就需要按照一定的方法从 bin 文件中分割.
不过,MNIST 官网有 bin 文件的结果说明,所以根据结构很容易编写代码实现.

我们先看,训练用的标签文件.
0000 起始位置是一个魔数 数值为 2049
0004 文件这个地方存放的数值是 6000 代表 6000 个标签
0008 文件这个地方开始按顺序存放与训练图片对应的数字标签 数值 0~9 我想大家都知道是什么吧所以,如果我们要读取标签的话,从标签文件开始偏移8个ubyte就能读取所有的标签数值了.
再看看训练用的图片集文件
0000 位置也是一个魔数
0004 代表了本文件中的图片数量
0008 文件这个位置存放的是一张图片的高
0012 文件这个位置存放的是一张图片的宽
0016 从这里起,代表的是图像中的每一个像素点
如果我们想要读取第一张图片怎么办?
从文件起始位置偏移16个byte,然后读取后面的28*28也就是 784 个字节.
如果要读取第二张图片能?
从文件起始位置偏移16+(2-1)*784个byte,然后读取后面的28*28个字节.
读取第 n 张图片时
从文件起始位置偏移 16+(n-1)*784 个byte,然后读取后面的28*28个字节.
一切都是有套路可以循的.
至于测试图片集文件和测试标签集文件,跟上面的类似,就不继续分析了.
我们可以自己按照bin文件的格式提取图片和标签,但考虑到这个没有技术含量又枯燥无畏,常见的机器学习框架都预置了对MNIST的处理,如scklean和Tensorflow,并不需要我们动手.极大减低了我们的痛苦
人生苦短,我用python大概就是这个意思.
接下来的内容,我们可以看到 Tensorflow 可以很轻松地实现对 MNIST 中数据的读取.
Tensorflow 读取MNIST图片数据
前面说过 Tensorflow 能很容易对 MNIST 进行读取和格式转换,其实是因为 Tensorflow 示例教程替我们做了这一部分的工作.
from tensorflow.examples.tutorials.mnist import input_data从mnist这个模块中引入 input_data 这个类.
# MNIST_data 代表当前程序文件所在的目录中,用于存放MNIST数据的文件夹,如果没有则新建,然后下载.
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)只需要调用 input_data 的 read_data_sets() 方法就好了。
如果当前文件所在目录中,不存在 MNIST_data 这个目录的话,程序会自动下载 MNIST 数据到这个位置,如果已经存在了的话,就直接读取数据文件。
把所有的图片读取出来后,创建一个 mnist,mnist 是一个 dataset 类实例,里面有许多 numpy 数组,存放图片和标签.
需要注意的是 MNIST 本身数据集分为两个部分.
训练集 和测试集
但在 input_data 中,人为增加了验证集,默认 5000 张图片.
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]所以,最终有3个数据集:
训练集、测试集、验证集
通过 mnist 对象可以轻松访问它们,如下面代码所示
mnist.train.images
mnist.train.labels
mnist.test.images
mnist.test.labels
mnist.validation.images
mnist.validation.labels需要注意的是,读取后的图片数据,每张图片就是numpy 数组中一行的数据.
我们简单打印一下
print(mnist.train.images.shape)
print(mnist.train.labels.shape)打印的结果如下:
(55000, 784)
(55000, 10)可以看到,train.images 数组行数为55000 列数为 784,代表了 55000 张测试图片.
好奇的同学也可以将测试图片可视化的方式呈现.
#获取第二张图片
image = mnist.train.images[1,:]
#将图像数据还原成28*28的分辨率
image = image.reshape(28,28)
#打印对应的标签
print(mnist.train.labels[1])
plt.figure()
plt.imshow(image)
plt.show()
可以看到图片其实是数字3,标签内容如下.
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]这是 one-hot 的形式,它代表标签值是 3.
Tensorflow 设置 CNN 结构
上面的内容介绍了如何在 Tensorflow 中读取 MNIST 数据集的图片和标签,接下来要做的事情就是搞定模块这一环节.
模型我选定的是 CNN,也就是卷积神经网络,在这里我假设大家都明白 CNN 的概念,我要确定一个 CNN 来学习如何识别手写数字的能力.
为了简单起见,我确定了一个 4 层的神经网络.

从左到右,分别是输入层、卷积层、全连接层、输出层.
卷积层我用了 3x3 的卷积核,数量为 32 stride为 1
激活方法用了 relu
然后用了池化层 2x2 的核 stride 为 2
fc1 层用了 784 个神经元
output 层 10 个神经元,用于预测一张测试图片中每个数字的概率,其中的概率经 softmax 处理过
本文想测试一下,就是这个再简单不过的卷积神经网络,它对 MNIST 中数字的识别效果如何.
下面就是代码
# None 代表图片数量未知
input = tf.placeholder(tf.float32,[None,784])
# 将input 重新调整结构,适用于CNN的特征提取
input_image = tf.reshape(input,[-1,28,28,1])
# y是最终预测的结果
y = tf.placeholder(tf.float32,[None,10])因为 Tensorflow 一次可以训练多张图片,所以要用一个占位符 placeholder 这样具体数值可以在后面训练时动态分配.
# input 代表输入,filter 代表卷积核
def conv2d(input,filter):
return tf.nn.conv2d(input,filter,strides=[1,1,1,1],padding='SAME')
# 池化层
def max_pool(input):
return tf.nn.max_pool(input,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 初始化卷积核或者是权重数组的值
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
# 初始化bias的值
def bias_variable(shape):
return tf.Variable(tf.zeros(shape))
上面4个方法都是工具方法,为了帮助我们创造神经网络的.
conv2d() 是创造卷积层的方法.
max_pool() 是池化层.
然后剩下的两个方法都是为了初始化超参数的.
#[filter_height, filter_width, in_channels, out_channels]
#定义了卷积核
filter = [3,3,1,32]
filter_conv1 = weight_variable(filter)
b_conv1 = bias_variable([32])
# 创建卷积层,进行卷积操作,并通过Relu激活,然后池化
h_conv1 = tf.nn.relu(conv2d(input_image,filter_conv1)+b_conv1)
h_pool1 = max_pool(h_conv1)定义了卷积层的结构.
h_flat = tf.reshape(h_pool1,[-1,14*14*32])
W_fc1 = weight_variable([14*14*32,784])
b_fc1 = bias_variable([784])
h_fc1 = tf.matmul(h_flat,W_fc1) + b_fc1
W_fc2 = weight_variable([784,10])
b_fc2 = bias_variable([10])
y_hat = tf.matmul(h_fc1,W_fc2) + b_fc2
h_flat 是将 pool 后的卷积核全部拉平成一行数据,便于和后面的全连接层进行数据运算.
y_hat 是整个神经网络的输出层,包含 10 个结点.
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=y_hat ))代价函数采用了 cross_entropy,显然,整个模型输出的值经过了 softmax 处理,将输出的值换算成每个类别的概率.
到这里,神经网络结构我们就确定了,下面要做的就是训练神经网络和测试神经网络了.
训练神经网络
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)在这里,定义了一个梯度下降的训练器,学习率是0.01.
train_step 其实就是一个黑盒子,它隐去了很多的技术细节,但同时也极大方便了我们的开发.
我们只需要知道,train_step在每一次训练后都会调整神经网络中参数的值,以便 cross_entropy 这个代价函数的值最低,也就是为了神经网络的表现越来越好.
correct_prediction = tf.equal(tf.argmax(y_hat,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))上面代码的目的是定义准确率,我们会在后面的代码中周期性地打印准确率,训练测试后,我们还要打印测试集下面神经网络的准确率.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(10000):
batch_x,batch_y = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict=input:batch_x,y:batch_y)
print("step %d,train accuracy %g " %(i,train_accuracy))
train_step.run(feed_dict=input:batch_x,y:batch_y)
print("test accuracy %g " % accuracy.eval(feed_dict=input:mnist.test.images,y:mnist.test.labels))我们的 epoch 是 10000 次,也就是说需要训练10000个周期.每个周期训练都是小批量训练 50 张,然后每隔 100 个训练周期打印阶段性的准确率.
训练完成后,还需要验证测试集下的准确度
step 9600,train accuracy 0.98
step 9700,train accuracy 0.96
step 9800,train accuracy 1
step 9900,train accuracy 1
test accuracy 0.9766 最终的测试成绩,准确率 97.66%.
那么准确率为 97.66 % 算不算高呢?
其实,非常不错了.我们文章采取的模型是我自己设置的最简单的模型.但即使这样,相比于传统的机器学习方法,它的确不错了.大家可以去官网看看不同的模型,在 MNIST 测试时的表现.
下面是完整代码,我是 Python3.5 + Tensorflow1.7
mnist_conv.py
# coding:utf-8
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
input = tf.placeholder(tf.float32,[None,784])
input_image = tf.reshape(input,[-1,28,28,1])
y = tf.placeholder(tf.float32,[None,10])
# input 代表输入,filter 代表卷积核
def conv2d(input,filter):
return tf.nn.conv2d(input,filter,strides=[1,1,1,1],padding='SAME')
# 池化层
def max_pool(input):
return tf.nn.max_pool(input,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 初始化卷积核或者是权重数组的值
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
# 初始化bias的值
def bias_variable(shape):
return tf.Variable(tf.zeros(shape))
#[filter_height, filter_width, in_channels, out_channels]
#定义了卷积核
filter = [3,3,1,32]
filter_conv1 = weight_variable(filter)
b_conv1 = bias_variable([32])
# 创建卷积层,进行卷积操作,并通过Relu激活,然后池化
h_conv1 = tf.nn.relu(conv2d(input_image,filter_conv1)+b_conv1)
h_pool1 = max_pool(h_conv1)
h_flat = tf.reshape(h_pool1,[-1,14*14*32])
W_fc1 = weight_variable([14*14*32,768])
b_fc1 = bias_variable([768])
h_fc1 = tf.matmul(h_flat,W_fc1) + b_fc1
W_fc2 = weight_variable([768,10])
b_fc2 = bias_variable([10])
y_hat = tf.matmul(h_fc1,W_fc2) + b_fc2
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=y_hat ))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_hat,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(10000):
batch_x,batch_y = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict=input:batch_x,y:batch_y)
print("step %d,train accuracy %g " %(i,train_accuracy))
train_step.run(feed_dict=input:batch_x,y:batch_y)
# sess.run(train_step,feed_dict=x:batch_x,y:batch_y)
print("test accuracy %g " % accuracy.eval(feed_dict=input:mnist.test.images,y:mnist.test.labels))
扩展
本文中的神经网络,麻雀虽小,但五脏俱全.
不过,同学们可以持续优化它,毕竟有的神经网络能够达到 99.67% 的准确率.
- 设计更深的层次的神经网络,本文只有4层,并且这4层还包括输入输出层,同学们可以扩展更多的层,变现效果肯定更好.
- 使用其它的优化器,比如 AdamOptimizer
- 使用 dropout 优化手段
- 使用数据增强技术,让 MNIST 可供训练的图片更多,这样神经网络学习也更充分
- 用 Tensorboard 记录训练过程的准确率或者 cross_entropy 的数值,最后生成可视化的报表
最终,还是要建议同学们自己动手敲一遍代码,敲完然后思考一下,为什么要这样写,等你能够比较流利敲出代码时,你就通过 MNIST 基本掌握了深度学习的一些套路,这会提高你在后续学习中的兴致.如果你不亲手敲代码的化,那么深度学习的很多概念,你没有办法让它直观起来,并且你会把它们忘掉.
最后,如果应对了 MNIST 之后,我们就可以将目光放到更复杂的数据集上去。比如 CIFAR10,比如自动驾驶中的行人识别。
光看书是不行的,真的要亲手实践。

以上是关于Tensorflow 写给初学者的深度学习教程之 MNIST 数字识别的主要内容,如果未能解决你的问题,请参考以下文章