Linux工具学习
Posted Jocelin47
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux工具学习相关的知识,希望对你有一定的参考价值。
一、linux下性能调优工具OProfile和perf
OProfile 已经存在了几十年,有一段时间是在基于 Linux的系统上进行性能分析的主力军,今天也可以发挥同样的作用。但是,OProfile 不包含在 Red Hat Enterprise Linux (RHEL) 8 beta 中,因此 OProfile 用户开始考虑替代工具可能是谨慎的。在功能、易用性和社区活力方面与OProfile 相比非常有利的类似项目如perf命令。
OProfile 和perf当前在 Linux 内核中使用相同的基本机制来启用事件跟踪:perf_events 基础结构。虽然它主要是一个用户空间工具,perf但从开发的角度来看,该命令是 Linux 内核的一部分,作为 Linux 内核的一部分有优点也有缺点。一个可能的优势是代码更容易维护,因为代码库不会随着时间的推移而分崩离析。一个缺点是版本perf在很大程度上与 Linux 内核的版本有内在联系:获得新功能perf通常意味着获得新内核。
1.1 OProfile
1.1.1 OProfile介绍
OProfile是用于Linux的若干种评测和性能监控工具中的一种,它可以工作在不同的体系结构上,包括MIPS、ARM、IA32、IA64和AMD。
同时OProfile是Linux平台上的一个功能强大的性能分析工具,支持两种采样(sampling)方式:基于事件的采样(eventbased)和基于时间的采样(timebased)。
基于事件的采样是OProfile只记录特定事件(比如L2 cache miss)的发生次数,当达到用户设定的定值时OProfile就记录一下(采一个样)。这种方式需要CPU内部有性能计数器(performace counter)。
基于时间的采样是oProfile借助OS时钟中断的机制,每个时钟中断OProfile都会记录一次(采一次样),引入此种采样方式的目的在于提供对没有性能计数器的CPU的支持,其精度相对于基于事件的采样要低。因为要借助OS时钟中断的支持,对禁用中断的代码OProfile不能对其进行分析。
oProfile在Linux上分两部分,一个是内核模块(oprofile.ko),一个为用户空间的守护进程(oprofiled)。前者负责访问性能计数器或者注册基于时间采样的函数(使用register_timer_hook注册之,使时钟中断处理程序最后执行profile_tick时可以访问之),并采样置于内核的缓冲区内。后者在后台运行,负责从内核空间收集数据,写入文件。
1.1.2 安装OProfile
http://oprofile.sourceforge.net/download/
./configure make & sudo make install
-
ERROR1:configure:error:popt library not found
下载popt-1.16,下载地址:https://www.linuxfromscratch.org/blfs/view/svn/general/popt.html
./configure make & sudo make install -
ERROR2:configure:error: liberty library not found
下载binutils-2.25,下载地址:http://ftp.gnu.org/gnu/binutils/?C=M;O=D./configure make & sudo make install
1.3 使用OProfile
(1) OProfile使用流程
1. opcontrol --init
2. opcontrol --no-vmlinux
3. opcontrol --start
4. ./your_app
5. opcontrol --dump
6. opcontrol --stop
7. opreport -l ./your_app
(2) oprofile初始化
opcontrol --init
该命令会加载oprofile.ko模块,mount oprofilefs。成功后会在/dev/oprofile/目录下导出
一些文件和目录如: cpu_type, dump, enable, pointer_size, stats/
(3) 配置
主要设置计数事件和样本计数,以及计数的CPU模式(用户态、核心态)
opcontrol --vmlinux=/boot/vmlinux-`uname -r` # 监控内核及驱动模块
opcontrol --no-vmlinux # 不监控内核及驱动模块
设置计数事件为CYCLES,即对处理器时钟周期进行计数样本计数为1000,即每1000个时钟周期,oprofile 取样一次。处理器运行于核心态则不计数,运行于用户态则计数。
opcontrol --setup --event=CYCLES:1000::0:1
(4) 清除会话中的数据
opcontrol --reset # 清除当前会话中的数据
(5) oprofile启动监控
opcontrol --start
opcontrol --start-daemon;opcontrol --start # 轻量级,减少启动守护进程对测试结果的影响
(6) 运行测试程序
./test
(7) oprofile停止监控
运行完成后,停止oprofile数据的收集。
opcontrol --stop # 停止监控
opcontrol --shutdown # 停止监控,并结束监控进程(监控的数据默认保存在/var/lib/oprofile/samples)
(8) 查看报告
opreport -l # 如果需要保存信息,可以重定向到文件中,比如opreport -l > 1.txt
(9) 卸载模块
opcontrol --deinit # 卸载模块
1.2 perf
1.2.1 perf介绍
Perf是Linux内核自带的系统性能优化工具,原理是:CPU的PMU registers(性能监控单元寄存器)中Get/Set performance counters来获得诸如instructions executed, cache-missed suffered, branches mispredicted(预测失准的分枝)等信息。
通过Perf,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。使用 perf可以分析程序运行期间发生的硬件事件,比如 cache miss等;也可以分析软件事件,比如 page fault 和进程切换。
1)PMU:性能监控单元(Performance Monitor Unit), CPU提供的一个性能监视单元,用于统计CPU性能数据;
2)Tracepoint:散落在内核源代码中的一些 hook,它们可以在特定的代码被运行到时被触发,这一特性可以被各种 trace/debug 工具所使用。
3)内核运行状态计数,例如: 1) 进程切换 2) Page fault 3) 中断计数
Perf的基本原理就是对被监测对象进行采样,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但若想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 TIck 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
Perf是运行在用户态,它通过RingBuffer数据结构(覆盖方式)与内核态进行交互,每次woken up的时候就是在读RingBuffer中的数据
Perf的使用流程和OProfile很像。所以如果你会用OProfile的话,用Perf就很简单。
1.2.2 安装perf
sudo apt install linux-tools-common
sudo apt install linux-tools-5.4.0-58-generic
sudo apt install linux-cloud-tools-5.4.0-58-generic
1.2.3 使用perf
(1) Perf事件处理常用的参数:
record : 记录到文件perf.data
report: 读取perf.data并以CUI方式展示
stat :统计事件个数
script:脚本自定义处理
trace : live输出事件(strace) ==> (比ptrace更高效的机制)
probe :自定义软件事件
top:类似top命令
list :列出事件
perf record后会将数据保存到perf.data中
perf stat 不会收集数据,只是展示出来通用事件
(2) 实例代码
#include<stdio.h>
void longa()
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
void foo2()
int i;
for(i=0 ; i < 10; i++)
longa();
void foo1()
int i;
for(i = 0; i< 100; i++)
longa();
int main(void)
foo1();
foo2();
return 0;
(3) record 记录到perf.data文件
gcc -o test -g test.c
带上-g选项,加入调试和符号表信息。
sudo perf record -e cycles ./test
带上-e cycles可以不加默认是给我们加上的

perf唤醒内核1次去写(通过信号),与内核交互的ringbuffer交互次数为1次。
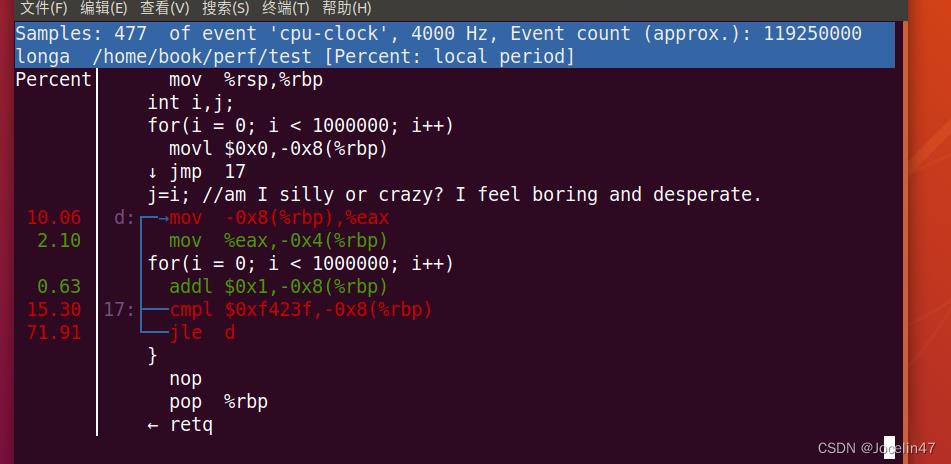
perf report
进入可以看到函数的用时占比
(4) stat统计事件个数
sudo perf stat ./test
将通用的事件展示出来
Performance counter stats for './test':
403.33 msec task-clock # 0.985 CPUs utilized
20 context-switches # 0.050 K/sec
0 cpu-migrations # 0.000 K/sec
45 page-faults # 0.112 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
0.409406795 seconds time elapsed
0.380006000 seconds user
0.024000000 seconds sys
(5) probe自定义软件事件
在test中加入一个probe,在longa函数上。可以统计调用longa调用的次数。
sudo perf probe -x ./test longa
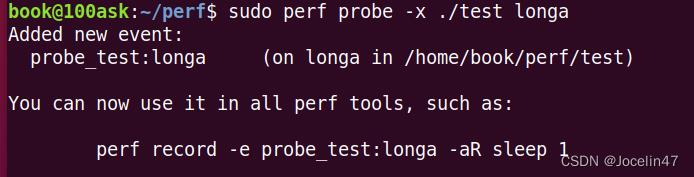
sudo perf record -e probe_test:longa ./test
此时的事件-e就不是cycles了,指定的是probe_test
sudo perf report
可以看到有110个事件

也可以通过-d参数删除事件
sudo perf probe -d longa # 删除这个事件,才能再次运行

(6) script 查看调用详细的次数
sudo perf script # 可以看到调用输出的次数
可以看到函数调用的次数。
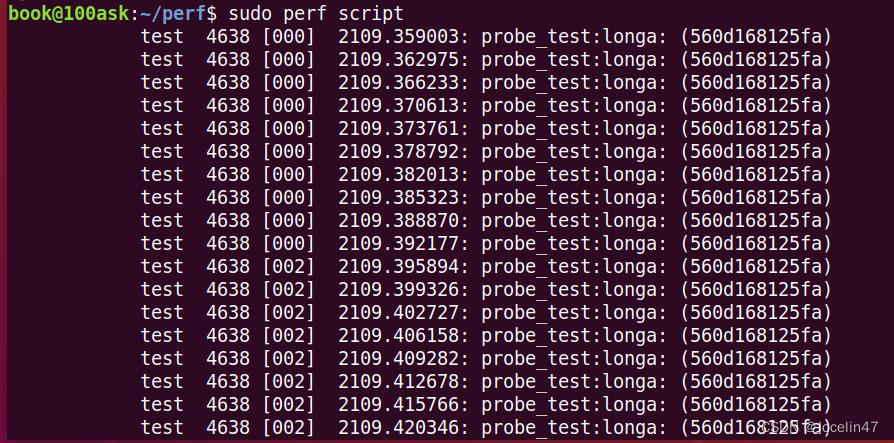
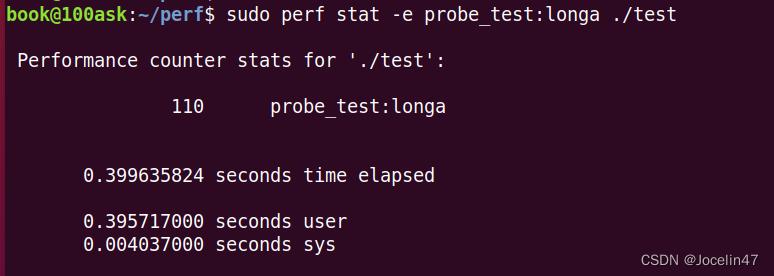
sudo perf stat -e probe_test:longa ./test
在使用前面用的stat命令,可以看到直接输出了调用次数
二、/proc/cpuinfo文件使用
2.1 /proc/cpuinfo涉及的内容介绍
在linux系统中,提供了/proc目录下文件,显示系统的软硬件信息。如果想了解系统中CPU的提供商和相关配置信息,则可以查/proc/cpuinfo。但是此文件输出项较多,不易理解。例如我们想获取,有多少颗物理CPU,每个物理cpu核心数,以及超线程是否开启等信息。
使用cat /proc/cpuinfo可以查看到cpu的信息:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 61
model name : Intel(R) Core(TM) i5-5200U CPU @ 2.20GHz
stepping : 4
microcode : 0x2d
cpu MHz : 2196.822
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap xsaveopt arat md_clear flush_l1d arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_multihit srbds
bogomips : 4393.64
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
其中关键字表示的意思如下:
processor :系统中逻辑处理核心数的编号,从0开始排序。
vendor_id :CPU制造商
cpu family :CPU产品系列代号
model :CPU属于其系列中的哪一代的代号
model name:CPU属于的名字及其编号、标称主频
stepping :CPU属于制作更新版本
cpu MHz :CPU的实际使用主频
cache size :CPU二级缓存大小
physical id :单个物理CPU的标号
siblings :单个物理CPU的逻辑CPU数。siblings=cpu cores [*2]。
core id :当前物理核在其所处CPU中的编号,这个编号不一定连续。
cpu cores :该逻辑核所处CPU的物理核数。比如此处cpu cores 是4个,那么对应core id 可能是 1、3、4、5。
apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
fpu :是否具有浮点运算单元(Floating Point Unit)
fpu_exception :是否支持浮点计算异常
cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
flags :当前CPU支持的功能
bogomips:在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second
clflush size :每次刷新缓存的大小单位
cache_alignment :缓存地址对齐单位
address sizes :可访问地址空间位数
power management :对能源管理的支持
2.2 快速的查看具体的内容
-
查询系统有几颗物理CPU:
cat /proc/cpuinfo | grep "physical id" |sort |uniq -
查询系统每颗物理CPU的核心数
cat /proc/cpuinfo | grep "cpu cores" | uniq -
查询系统的每颗物理CPU核心是否启用超线程技术。
如果启用此技术那么,每个物理核心又可分为两个逻辑处理器。
cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq如果cpu cores数量和siblings数量一致,则没有启用超线程,否则超线程被启用。

-
查询系统具有多少个逻辑CPU
cat /proc/cpuinfo | grep "processor" | wc -l
三、Top工具使用
3.1 top命令介绍
top 命令是 Linux 系统下常用的系统监控工具,通过 top 命令我们可以获取到系统动态运行的信息,包括内存使用情况,系统负载情况,进程的运行情况等等。
3.2 top命令用法
使用top命令后,可以在界面进行交互操作,参数h可以看到帮助命令
-d:number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。要手动刷新,用户可以输入回车或者空格
-b:以批次的方式执行top。
-n:与-b配合使用,表示需要进行几次top命令的输出结果,到达指定次数后 top 退出
top 命令的批处理模式(Batch-mode)可以区别于正常使用的交互模式(Interactive-mode),在批处理模式下top 只会不断打印系统状态,无法接受其他交互模式下的命令。如果配合-n 选项指定刷新次数的话,可以通过批处理模式将系统状态不断打印到日志中,实现实时监控的效果。
-p:指定特定的pid进程号进行观察。
-u: user 只显示指定用户启动的进程
示例: top -u root(只显示以root用户启动的进程)
-B:重要内容加粗
-H:切换到线程状态
-k:结束指定进程
-m:切换内存使用量的显示样式
-e:调整内存的计量单位
F:命令指定字段过滤
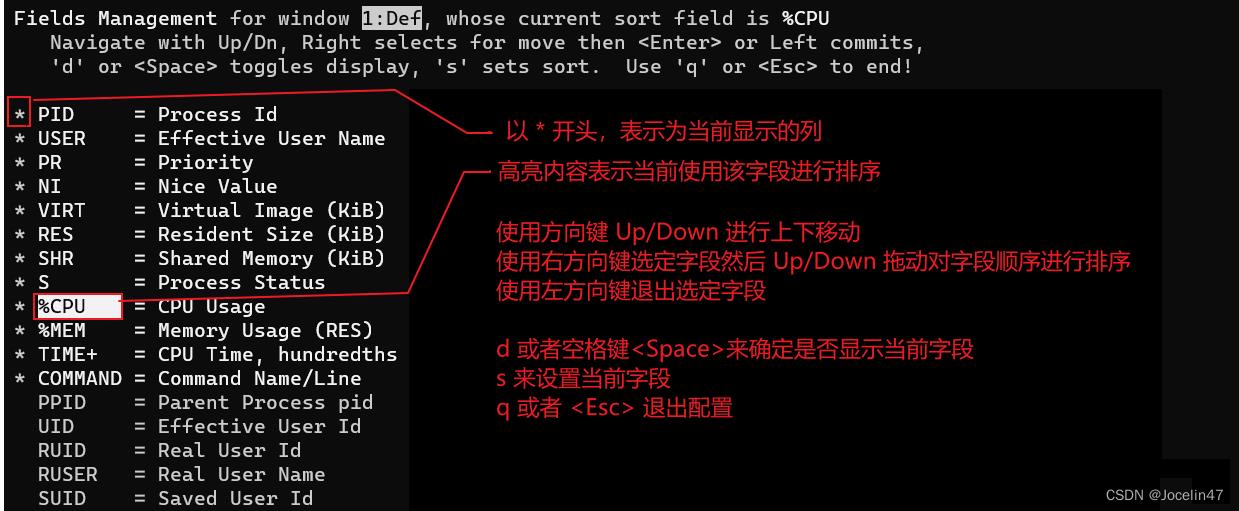
通过选中MEM字段右移调序到CPU上面后,优先以MEM排序;
通过空格可以选择是否显示该字段
-c:切换是否显示进程启动时的完整路径和程序名。
-o:命令执行过滤
命令的格式如下:
<!> <字段名称> <操作符> <包含值/排除值>
支持>,<,=这三类操作符
例子:显示PID>100的可以使用PID>100或者!PID<100
通过COMMAND=top,可以查看到top进程

使用 Ctrl+o 显示当前生效的过滤器
使用 =重置当前窗口的过滤器
使用 +重置全部窗口的过滤器
3.3 top界面参数说明
3.3.1 top前五行信息说明
top - 22:33:04 up 2 min, 1 users, load average: 0.85, 0.62, 0.25
Tasks: 155 total, 2 running, 153 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.4 us, 1.4 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2967536 total, 2249804 free, 303732 used, 414000 buff/cache
KiB Swap: 4194300 total, 4194300 free, 0 used. 2509432 avail Mem
前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。含义如下:
| 22:39:11 | 当前时间 |
|---|---|
| up 8 min | 系统运行时间 |
| 1 user | 当前登录用户数 |
| load average: 0.00, 0.17, 0.16 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。top - 22:33:04 up 2 min, 2 users, load average: 0.85, 0.62, 0.25 |
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。
第二行内容及含义如下:
Tasks: 155 total, 2 running, 153 sleeping, 0 stopped, 0 zombie
| 内容 | 含义 |
|---|---|
| total | 进程总数 |
| running | 正在运行的进程数 |
| sleeping | 睡眠的进程数 |
| stopped | 停止的进程数 |
| zombie | 僵尸进程数 |
第三行内容及含义如下:(可以按1查看所有CPU的信息)
%Cpu(s): 3.4 us, 1.4 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
| 内容 | 含义 |
|---|---|
| us | 用户空间占用CPU百分比 |
| sy | 内核空间占用CPU百分比 |
| ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| id | 空闲CPU百分比 |
| wa | 等待输入输出的CPU时间百分比 |
| hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| si | 软中断(Software Interrupts)占用CPU的百分比 |
| st | (Steal time) 是当 hypervisor 服务另一个虚拟处理器的时候,虚拟 CPU 等待实际 CPU 的时间的百分比。 |
最后两行为内存信息。
第四行的内容及含义如下:
KiB Mem : 2967536 total, 2249804 free, 303732 used, 414000 buff/cache
| 内容 | 含义 |
|---|---|
| KiB Mem | 使用的物理内存总量 |
| used | 使用的内存总量 |
| buff/cache | 用作内核缓存的内存量 |
第五行的内容及含义如下:
KiB Swap: 4194300 total, 4194300 free, 0 used. 2509432 avail Mem
| 内容 | 含义 |
|---|---|
| KiB Swap | 交换区总量 |
| avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上表中的缓冲交换区总量含义为:内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入
3.3.2 进程信息说明
| 列名 | 含义 |
|---|---|
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值,负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEN | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
参考链接:
- OProfile
https://www.jianshu.com/p/a5f28ccff7cd - perf
https://developer.ibm.com/tutorials/migrate-from-oprofile-to-perf/
性能分析工具Linux perf使用经验 - /cpu/info
http://t.zoukankan.com/wxxjianchi-p-10522049.html - top
https://blog.csdn.net/Luckiers/article/details/123909819
以上是关于Linux工具学习的主要内容,如果未能解决你的问题,请参考以下文章