CFS调度主要代码分析一
Posted Loopers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CFS调度主要代码分析一相关的知识,希望对你有一定的参考价值。
在前面学习了CFS调度的原理和主要的数据结构,今天我们就来进入代码分析环节。当然了代码分析只看主要主干不看毛细,同时我们也是根据一个进程是如何被调度的思路来分析一些重要的代码。
在分析代码之前,有一些小函数需要先分析下,俗话说万丈高楼平地起,这些小函数还是很重要的。
calc_delta_fair
calc_delta_fair函数是用来计算进程的vruntime的函数。在之前CFS原理篇了解了一个进程的vruntime的计算公式如下:

一个进程的vruntime 等于进程实际运行时间 乘以 NICE0进程对应权重 除以 当前进程的权重。为了保证除法计算中不涉及浮点运算,linux内核通过先左移32位,然后右移32位来避免浮点运算。修改后的公式为:

再经过转化成如下的公式

其中inv_weight的值内核代码中已经计算好了,在使用的时候只需要通过查表就可以的到Inv_weigth的值
/*
* Inverse (2^32/x) values of the sched_prio_to_weight[] array, precalculated.
*
* In cases where the weight does not change often, we can use the
* precalculated inverse to speed up arithmetics by turning divisions
* into multiplications:
*/
const u32 sched_prio_to_wmult[40] =
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
;这样一来通过上面的计算方式就可以轻松的获取一个进程的vruntime。我们知道计算过程后,再来看下代码
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
如果当前调度实体的权重值等于NICE_0_LOAD,则直接返回进程的实际运行时间。因为nice0进程的虚拟时间等于物理时间。否则调用__calc_delta函数计算进程的vruntime
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
u64 fact = scale_load_down(weight);
int shift = WMULT_SHIFT;
__update_inv_weight(lw);
if (unlikely(fact >> 32))
while (fact >> 32)
fact >>= 1;
shift--;
/* hint to use a 32x32->64 mul */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32)
fact >>= 1;
shift--;
return mul_u64_u32_shr(delta_exec, fact, shift);
最终通过上面的计算公式就可以计算出一个进程的虚拟运行时间。详细代码不推到了,没必要。有兴趣的可以看下。
sched_slice
此函数是用来计算一个调度周期内,一个调度实体可以分配多少运行时间
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);
for_each_sched_entity(se)
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq))
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
slice = __calc_delta(slice, se->load.weight, load);
return slice;
__sched_period函数是计算调度周期的函数,此函数当进程个数小于8时,调度周期等于调度延迟等于6ms。否则调度周期等于进程的个数乘以0.75ms,表示一个进程最少可以运行0.75ms,防止进程过快发生上下文切换。
接着就是遍历当前的调度实体,如果调度实体没有调度组的关系,则只运行一次。获取当前CFS运行队列cfs_rq,获取运行队列的权重cfs_rq->rq代表的是这个运行队列的权重。最后通过__calc_delta计算出此进程的实际运行时间。
__calc_delta此函数之前计算虚拟函数的时候介绍过,它不仅仅可以计算一个进程的虚拟时间,它在这里是计算一个进程在总的调度周期中可以获取的运行时间,公式为:
进程的运行时间 = (调度周期时间 * 进程的weight) / CFS运行队列的总weigthplace_entity
此函数用来惩罚一个调度实体,本质是修改它的vruntime的值
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
if (!initial)
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
- 获取当前CFS运行队列的min_vruntime的值
- 当参数initial等于true时,代表是新创建的进程,新创建的进程则给它的vruntime增加值,代表惩罚它。这就是对新创建进程的一种惩罚吧,因为新创建进程的vruntime过小,防止一直占在CPU
- 如果inital不为true,则代表的是唤醒的进程,对于唤醒的进程则需要照顾,最大的照顾是调度延时的一半。
- 确保调度实体的vruntime不得倒退,通过max_vruntime获取最大的vruntime.
update_curr
update_curr函数用来更新当前进程的运行时间信息
static void update_curr(struct cfs_rq *cfs_rq)
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
account_cfs_rq_runtime(cfs_rq, delta_exec);
- delta_exec = now - curr->exec_start; 计算出当前CFS运行队列的进程,距离上次更新虚拟时间的差值
- curr->exec_start = now; 更新exec_start的值
- curr->sum_exec_runtime += delta_exec; 更新当前进程总共执行的时间
- 通过calc_delta_fair计算当前进程虚拟时间
- 通过update_min_vruntime函数来更新CFS运行队列中最小的vruntime的值
新进程创建
通过新进程创建流程,来分析下CFS调度器是如何设置新创建的进程的。在fork创建一个新进程的时候我们涉及到sched模块时是一笔带过的,这里重点分析。
int sched_fork(unsigned long clone_flags, struct task_struct *p)
unsigned long flags;
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_NEW;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
if (dl_prio(p->prio))
return -EAGAIN;
else if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class;
init_entity_runnable_average(&p->se);
raw_spin_lock_irqsave(&p->pi_lock, flags);
/*
* We're setting the CPU for the first time, we don't migrate,
* so use __set_task_cpu().
*/
__set_task_cpu(p, smp_processor_id());
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
init_task_preempt_count(p);
return 0;
- __sched_fork 主要是初始化调度实体的,此处不用继承父进程,因为子进程会重新运行的,对这些值会进程重新的复制
- 设置进程的状态为TASK_NEW,代表这是个新进程
- 将当前current进程的优先级设置给新创建的进程,新创建进程动态优先级p->prio = current->normal_prio
- 根据进程的优先级设置进程的调度类,如果是RT进程设置调度类为rt_sched_class, 如果是普通进程设置调度类为fair_sched_class
- 设置当前进程在哪个CPU运行,此处只是简单的设置。在加入调度器的运行队列时还会设置一次
- 最后调用调度类中的task_fork函数指针,最后会调用到fair_sched_class中的task_fork函数指针
static void task_fork_fair(struct task_struct *p)
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr)
update_curr(cfs_rq);
se->vruntime = curr->vruntime;
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se))
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
- 通过current获取当前CFS运行队列,通过运行队列的curr指针获取当前的调度实体,然后通过update_curr更新当前调度实体的运行时间,同时将当前调度实体的虚拟vruntime的值赋值给新创建进程的vruntime。
- 通过place_entity函数对当前新创建的进程进行惩罚,以为第三个参数是1,则会对新创建进程惩罚
- se->vruntime -= cfs_rq->min_vruntime; 将当前调度实体虚拟运行时间减去min_vruntime,这句可以这样理解,因为在此调度实体添加到运行队列中还有一段时间,在这段时间内min_vruntime的值会改变的。当在添加到运行队列的时候在加上,就显得公平了。
以上就是新创建一个进程流程,用如下的流程图总结下
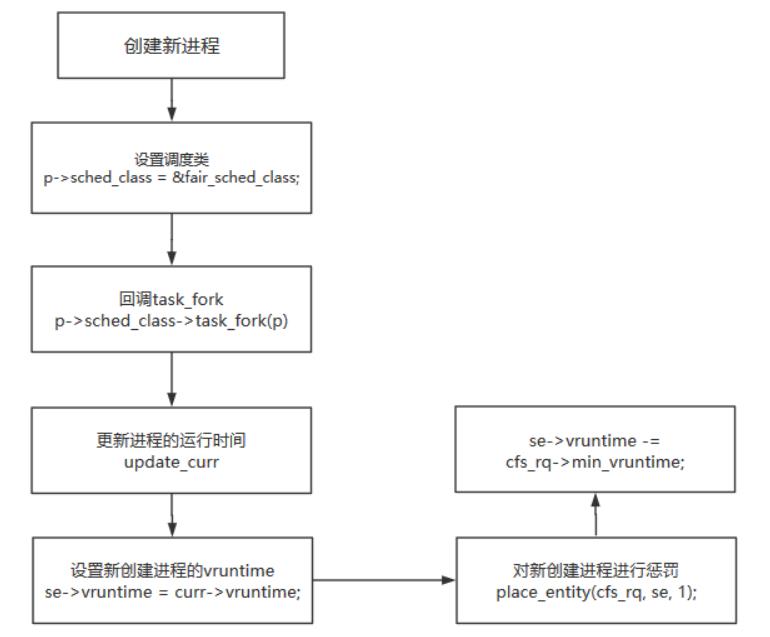
将新进程加入到就绪队列中
在fork一个进程完毕后,会通过wake_up_new_task函数来唤醒一个进程,将新创建的进程加入到就绪队列中
void wake_up_new_task(struct task_struct *p)
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
p->state = TASK_RUNNING;
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected CPU might disappear through hotplug
*
* Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,
* as we're not fully set-up yet.
*/
p->recent_used_cpu = task_cpu(p);
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p, &rf);
update_rq_clock(rq);
post_init_entity_util_avg(&p->se);
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
task_rq_unlock(rq, p, &rf);
- 设置进程的状态为TASK_RUNNING,代表进程已经处于就绪状态了
- 如果打开SMP的话,则会通过__set_task_cpu重新设置一个最优的CPU的,让新进程在其上面运行
- 最后通过activate_task(rq, p, ENQUEUE_NOCLOCK);函数将新创建的进程加入到就绪队列
void activate_task(struct rq *rq, struct task_struct *p, int flags)
if (task_contributes_to_load(p))
rq->nr_uninterruptible--;
enqueue_task(rq, p, flags);
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
if (!(flags & ENQUEUE_NOCLOCK))
update_rq_clock(rq);
if (!(flags & ENQUEUE_RESTORE))
sched_info_queued(rq, p);
psi_enqueue(p, flags & ENQUEUE_WAKEUP);
p->sched_class->enqueue_task(rq, p, flags);
最终会调用到CFS调度类中的enqueue_task函数指针的。
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se)
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
/*
* end evaluation on encountering a throttled cfs_rq
*
* note: in the case of encountering a throttled cfs_rq we will
* post the final h_nr_running increment below.
*/
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running++;
flags = ENQUEUE_WAKEUP;
- 如果调度实体的on_rq已经设置,则代表在就绪队列中,直接跳出
- 通过enqueue_entity函数将调度实体入队
- 增加CFS运行队列的可运行个数h_nr_running
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED);
bool curr = cfs_rq->curr == se;
/*
* If we're the current task, we must renormalise before calling
* update_curr().
*/
if (renorm && curr)
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq);
/*
* Otherwise, renormalise after, such that we're placed at the current
* moment in time, instead of some random moment in the past. Being
* placed in the past could significantly boost this task to the
* fairness detriment of existing tasks.
*/
if (renorm && !curr)
se->vruntime += cfs_rq->min_vruntime;
/*
* When enqueuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Add its load to cfs_rq->runnable_avg
* - For group_entity, update its weight to reflect the new share of
* its group cfs_rq
* - Add its new weight to cfs_rq->load.weight
*/
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH);
update_cfs_group(se);
enqueue_runnable_load_avg(cfs_rq, se);
account_entity_enqueue(cfs_rq, se);
if (flags & ENQUEUE_WAKEUP)
place_entity(cfs_rq, se, 0);
check_schedstat_required();
update_stats_enqueue(cfs_rq, se, flags);
check_spread(cfs_rq, se);
if (!curr)
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1)
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
- se->vruntime += cfs_rq->min_vruntime; 将调度实体的虚拟时间添加回去,之前在fork的时候减去了min_vruntime,现在需要加回去,现在的min_vruntime比较准确
- update_curr(cfs_rq); 来更新当前调度实体的运行时间以及CFS运行队列的min_vruntime
- 通过注释看当一个调度实体添加到就绪队列中去时,需要更新运行队列的负载以及调度实体的负载
- 如果设置了ENQUEUE_WAKEUP,则代表当前进程是唤醒进程,则需要进行一定的补偿
- __enqueue_entity将调度实体添加到CFS红黑树中
- se->on_rq = 1;设置on_rq为1,代表已经添加到运行队列中去了
选择下一个运行的进程
当通过fork创建一个进程,然后将其添加到CFS运行队列的红黑树中,接下来就需要选择其运行了,我们直接看schedule函数。为了方便阅读主干,将代码做下精简
static void __sched notrace __schedule(bool preempt)
cpu = smp_processor_id(); //获取当前CPU
rq = cpu_rq(cpu); //获取当前的struct rq, PER_CPU变量
prev = rq->curr; //通过curr指针获取当前运行进程
next = pick_next_task(rq, prev, &rf); //通过pick_next回调选择进程
if (likely(prev != next))
rq = context_switch(rq, prev, next, &rf); //如果当前进程和下一个进程不同,则发生切换
- 通过pick_next获取下一个运行进程
- 通过context_switch发生上下文切换
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
const struct sched_class *class;
struct task_struct *p;
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running))
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
again:
for_each_class(class)
p = class->pick_next_task(rq, prev, rf);
if (p)
if (unlikely(p == RETRY_TASK))
goto again;
return p;
pick_next主要的两个步骤
- 因为系统中普通进程占多达数,这里通过判断当前进程的调度类以及运行队列的可运行进程个数是否等于CFS运行队列中可运行进程的个数,来做一个优化。如果相同则说明剩余的进程都是普通进程,则直接调用fair_sched_class中的pick_next回调
- 否则跳到again处,老老实实的按照调度类的优先级从高往低依次遍历调用pick_next_task函数指针了
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
if (!cfs_rq->nr_running)
goto idle;
put_prev_task(rq, prev);
do
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
while (cfs_rq);- 如果CFS运行队列中没有进程了,则会返回idle进程
- pick_next_entry会从CFS红黑树最左边节点获取一个调度实体
- set_next_entry则设置next调度实体到CFS运行队列的curr指针上
- 后面再context_switch则会发生切换,切换内容在后面章节介绍
以上是关于CFS调度主要代码分析一的主要内容,如果未能解决你的问题,请参考以下文章