PyTorch快餐教程2019 - Multi-Head Attention
Posted Jtag特工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch快餐教程2019 - Multi-Head Attention相关的知识,希望对你有一定的参考价值。
PyTorch快餐教程2019 (2) - Multi-Head Attention
上一节我们为了让一个完整的语言模型跑起来,可能给大家带来的学习负担过重了。没关系,我们这一节开始来还上节没讲清楚的债。
还记得我们上节提到的两个Attention吗?
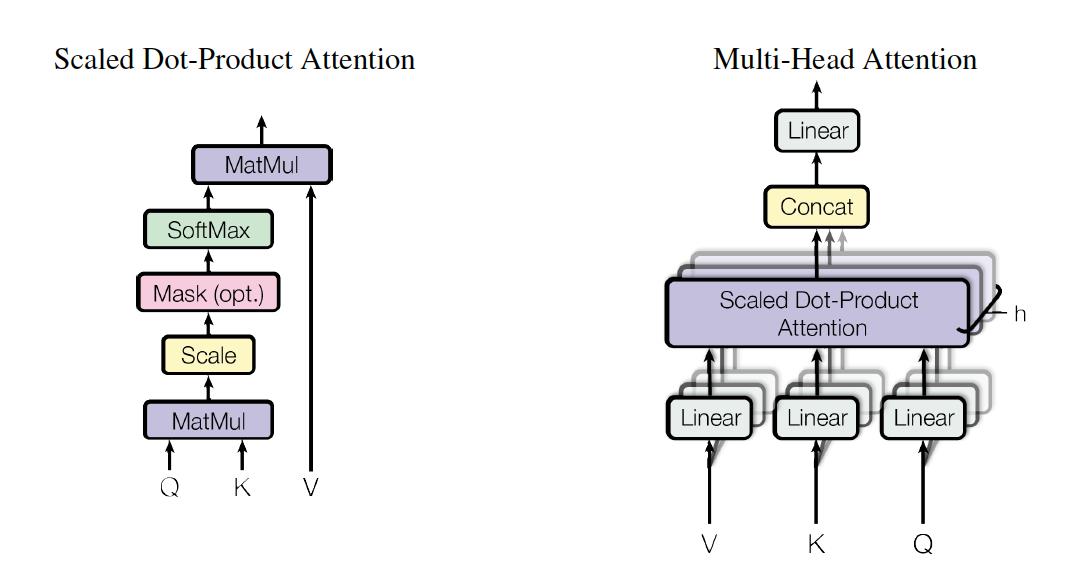
上节我们给大家一个印象,现在我们正式开始介绍其原理。
Scaled Dot-Product Attention
首先说Scaled Dot-Product Attention,其计算公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\\fracQK^T\\sqrtd_k)V
Attention(Q,K,V)=softmax(dkQKT)V
Q乘以K的转置,再除以
d
k
d_k
dk的平方根进行缩放,经过一个可选的Mask,经过softmax之后,再与V相乘。
用代码实现如下:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \\
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
Multi-Head Attention
有了缩放点积注意力机制之后,我们就可以来定义多头注意力。
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
c
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
n
)
W
O
MultiHead(Q,K,V)=concat(head_1,...,head_n)W^O
MultiHead(Q,K,V)=concat(head1,...,headn)WO
其中,
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)
headi=Attention(QWiQ,KWiK,VWiV)
这个Attention是我们上面介绍的Scaled Dot-Product Attention.
这些W都是要训练的参数矩阵。
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
,
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
,
W
o
∈
R
h
d
v
×
d
m
o
d
e
l
W_i^Q\\in \\mathbbR^d_model \\times d_k, W_i^K\\in\\mathbbR^d_model \\times d_k, W_i^V\\in\\mathbbR^d_model \\times d_v, W_o\\in\\mathbbR^hd_v \\times d_model
WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,Wo∈Rhdv×dmodel
h是multi-head中的head数。在《Attention is all you need》论文中,h取值为8。
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
64
d_k=d_v=d_model/h=64
dk=dv=dmodel/h=64
这样我们需要的参数就是d_model和h.
大家看公式有点要晕的节奏,别怕,我们上代码:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"初始化时指定头数h和模型维度d_model"
super(MultiHeadedAttention, self).__init__()
# 二者是一定整除的
assert d_model % h == 0
# 按照文中的简化,我们让d_v与d_k相等
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
其中,clones是复制几个一模一样的模型的函数,其定义如下:
def clones(module, N):
"生成n个相同的层"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
Attention的逻辑主要分为4步。第一步是计算一下mask。
def forward(self, query, key, value, mask=None):
"实现多头注意力模型"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
第二步是将这一批次的数据进行变形 d_model => h x d_k
query, key, value = \\
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
第三步,针对所有变量计算scaled dot product attention
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
最后,将attention计算结果串联在一起,其实对张量进行一次变形:
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
再看一种写法巩固一下
上面引用的代码来自:http://nlp.seas.harvard.edu/2018/04/03/attention.html
为了加深印象,我们再看另一种写法。
这个的命名更偏工程,d_model叫做hid_dim,h叫做n_heads,但是意思是一回事。
class SelfAttention(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super().__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
# d_model // h 仍然是要能整除,换个名字仍然意义不变
assert hid_dim % n_heads == 0
self.w_q = nn.Linear(hid_dim, hid_dim)
self.w_k = nn.Linear(hid_dim, hid_dim)
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads])).to(device)
下面是处理数据的过程:
def forward(self, query, key, value, mask=None):
# Q,K,V计算与变形:
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# Q, K相乘除以scale,这是计算scaled dot product attention的第一步
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 如果没有mask,就生成一个
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
# 然后对Q,K相乘的结果计算softmax加上dropout,这是计算scaled dot product attention的第二步:
attention = self.do(torch.softmax(energy, dim=-1))
# 第三步,attention结果与V相乘
x = torch.matmul(attention, V)
# 最后将多头排列好,就是multi-head attention的结果了
x = x.permute(0, 2, 1, 3).contiguous()
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x
第二种实现取自:https://github.com/bentrevett/pytorch-seq2seq
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于PyTorch快餐教程2019 - Multi-Head Attention的主要内容,如果未能解决你的问题,请参考以下文章