代码质量C++代码质量扫描主流工具深度比较
Posted 腾讯WeTest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了代码质量C++代码质量扫描主流工具深度比较相关的知识,希望对你有一定的参考价值。
本文由腾讯WeTest团队提供,未经授权严禁转载!更多资讯可直接戳链接查看:http://wetest.qq.com/lab/
微信号:TencentWeTest
文/张蓓
引言
静态代码分析是指无需运行被测代码,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,找出代码隐藏的错误和缺陷,如参数不匹配,有歧义的嵌套语句,错误的递归,非法计算,可能出现的空指针引用等等。统计证明,在整个软件开发生命周期中,30% 至 70% 的代码逻辑设计和编码缺陷是可以通过静态代码分析来发现和修复的。
在C++项目开发过程中,因为其为编译执行语言,语言规则要求较高,开发团队往往要花费大量的时间和精力发现并修改代码缺陷。所以C++ 静态代码分析工具能够帮助开发人员快速、有效的定位代码缺陷并及时纠正这些问题,从而极大地提高软件可靠性并节省开发成本。
静态代码分析工具的优势 :
1.自动执行静态代码分析,快速定位代码隐藏错误和缺陷。
2. 帮助代码设计人员更专注于分析和解决代码设计缺陷。
3. 减少在代码人工检查上花费的时间,提高软件可靠性并节省开发成本。
2业界主流静态代码扫描工具概况
目前市场上的C++ 静态代码分析工具种类繁多且各有千秋,本文将分别介绍TSC团队自主研发的tscancode工具和当前4种主流C++静态代码分析工具(cppcheck、coverity、clang、pclint),并从功能、效率、易用性等方面对它们进行分析和比较,以期帮助 C++开发人员更清晰静态代码分析工具的工作效果、适用场景和扩展空间,同时在其对应项目特征中选择合适的工具应用到项目开发环节中。
以下为工具在付费价格、规则数量、准确率、扫描效率、编译依赖、IDE支持、跨平台支持、可扩展开发方面的对比数据。注:本次竞品分析的选择了3款游戏项目(约500万行代码)。
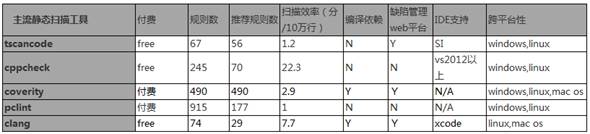
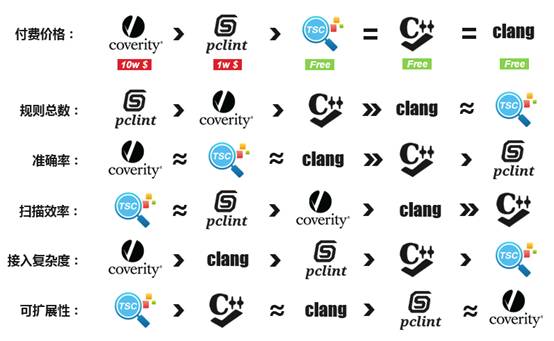
在可扩展性上,TSC有专人维护,定期根据用户需求扩展规则或新增功能特性,cppcheck和clang是开源工具,工具更新较慢,但如果用户有特殊需求可以自己扩展开发,pclint和coverity是商业软件,难以进行功能扩展。
同时,TSC有完整代码质量管理闭环平台QOC支持; coverity和clang可用web端的结果展示,但无法自行管理问题流,需要进行二次开发; cppcheck和pclint缺少web端结果展示。
以下重点比较具体检查规则和有效问题报错率。
3检查规则大比拼
3.1规则大类
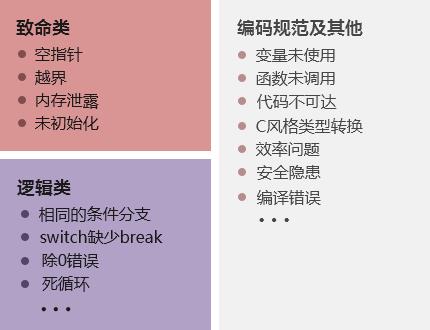
针对业内大量扫描工具在实际项目中扫描结果的影响比较,我们将代码质量问题分为以下几大类:
① 致命类:可能导致程序宕机、无响应等影响范围极大的错误;
② 逻辑类:可能造成程序不能达到预期逻辑结果的错误;
③ 编码规范及其他类:可能造成程序的可读性、可维护性较差的错误(不可达代码,无效的变量声明等);
3.2 规则大类分布
根据3大影响分类,其严重程度分别为高、中、低,各类型规则数量分布为:
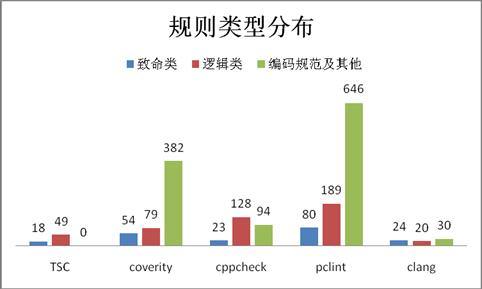
从规则分类占比来看:
① TSC针对互联网产品高效开发修复原则,工具定位为针对致命和逻辑类问题,相对传统、军事、安全领域,并不关注编码规范及编译错误;
② coverity作为商业化软件,在付费后添加规则上,达到覆盖率最全面,除致命和逻辑类规则外,还有大量编码规范、安全和针对其他语言(如java,C#)的规则;
③ cppcheck作为开源工具,应用范围广泛,根据开源社区场景搜集,在各方面都有规则添加,但场景较为粗犷,场景虽多,但有效率不高。例如:cppcheck在初始化检查上有5个子规则,样本代码共扫描出312个问题,其中有效问题仅8个,有效率仅为3%。
④ pclint作为商业化软件,在付费后添加规则上,达到覆盖率最全面,除致命和逻辑类规则外,还有大量编码规范、安全的规则;
⑤ clang作为开源软件,规则较少,但规则类型分布较为均匀,在致命、逻辑类,还有编码规范、安全类都有规则添加。
3.3规则报错数量
整体规则数量上:pclint[915]>coverity[515]>cppcheck[245]>clang[74]>TSC[67]
可以看出pclint和coverity规则最多,TSC和clang规则最少,原因有如下3点:
① pclint和coverity作为商业化软件,需求来源于传统软件、军事、安全各个领域,其规则总数最多,其编码规范类规则数量分别高达646条和382条;排除掉低价值的编码规范类规则,规则数量排序为:pclint[269]>cppcheck[151]>coverity[133]>TSC[67]>clang[44]
② 在规则实际报错数量上,以3款游戏500万行代码的结果覆盖度来看;
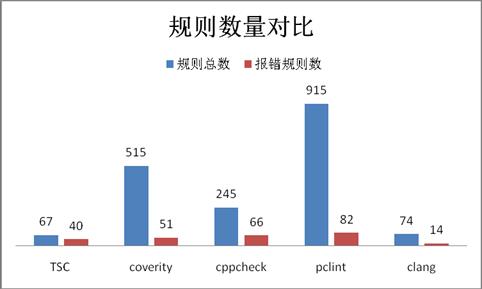
注:规则总数指工具所有的规则总数,报错规则数指开启工具所有规则情况下,扫描样本代码所覆盖的规则数量。
从实际项目扫描结果来看:
扫描出问题的规则数/规则总数:TSC[60%]>cppcheck[27%]>clang[19%]>coverity[10%]>pclint[9%]
pclint、coverity、cppcheck虽然规则数量很多,但因为其定制加入的大部分规则普遍适用度不高,大量规则可能在多个项目中都无法扫描出问题。有些规则却在多个项目中扫描出大量非核心的问题,如:函数没有被调用、未使用的变量、存在多余的头文件等。
③ 规则数量多来源于两个方面,一方面是规则覆盖更全面,另一方面是规则粒度划分得更细;
通过对具体规则进行分析,发现在规则划分粒度由细到出排序为[pclint,coverity,cppcheck,clang,TSC]
pclint和coverity划分粒度最细,cppcheck,clang次之,TSC最粗。
例如:coverity的除0报错分为整型除0,浮点数除0,取模除0;数组下标越界也细分为访问越界、读越界、写越界。Pclint和cppcheck初始化分为变量未初始化、结构体成员未初始化、类成员未初始化、string未初始化、data未初始化、union未初始化、全局静态变量未初始化等;而TSC则合并了一些过细的规则,未初始化上只分为变量未初始化和成员未初始化。
粒度划分越细既有优点也有缺点:
优点:可以针对细分规则灵活配置开关,关掉准确率低的规则
缺点:规则数量太多, 用户配置相当麻烦,新用户很难理解多个相似的规则之前的区别。
TSC为降低用户配置难度,在规则粒度划分上相对粗犷,但会从中提取出其中准确率低的场景,作为单独规则,从而达到可以关掉低准确率规则的目的。
4同类规则效果对比分析
本文针对每个工具在关键报错项,如:空指针、越界、变量未初始化、内存泄露、逻辑上的报错结果进行分析。
样本代码——3款游戏项目(约500万行代码)代码
测试对象——tscancode2.0、coverity7.5、cppcheck1.68、pclint9.0、clang3.4
有效报错数——某类规则在3款游戏项目的有效报错数总和
准确率——某类规则在3款游戏项目的平均准确率,准确率=有效报错数/报错总数*100%
综合评分——综合有效报错数和准确率的评分,有效报错数和准确率的权值暂定为45:55,综合评分=有效报错/最大有效报错数*100*45%+准确率*100*55%
4.1空指针规则
空指针检查规则主要检查是否存在对赋值为空的指针解引用的情况,空指针是c/c++中最大的问题,经常造成程序崩溃的致命错误。因此,C++静态代码分析工具对空指针的检查能力显得尤为重要。
图为五个工具对样本代码扫描结果:
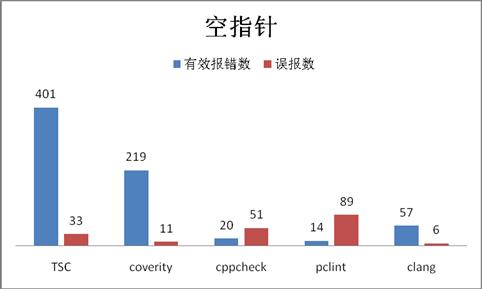
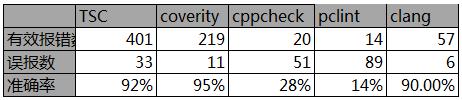
从报错数量和准确率来看:
有效报错数:TSC [401] >coverity[219]>>clang[57] >cppcheck[20]>pclint[14]
准确率: coverity[95%]≈TSC[92%] ≈clang[90%]>>cppcheck[28%]>pclint[14%]
综合评分: TSC[96分] >coverity[77分] >clang[56分]>cppcheck[18分]>pclint[8分]
1. 从准确率来看,在空指针检查方面,不考虑扫描效率和扫描环境搭建复杂度,TSC、coverity和clang都很优秀,三者准确率都很高。cppcheck, pclint在结果准确率上和数量上都较差,不推荐使用。
2. 从空指针规则细分程度来看,TSC和coverity相当,细分场景挖掘更多,cppcheck规则并未细分空指针规则,从实际项目结果来看,只能检查出dereferenceBeforeCheck场景的错误。Clang和pclint在空指针细分上维度跟TSC和coverity不同,比如:它们区分是参数指针解引用还是局部变量解引用,细分粒度不够且覆盖场景较少,其覆盖场景基本都被TSC和coverity包含。
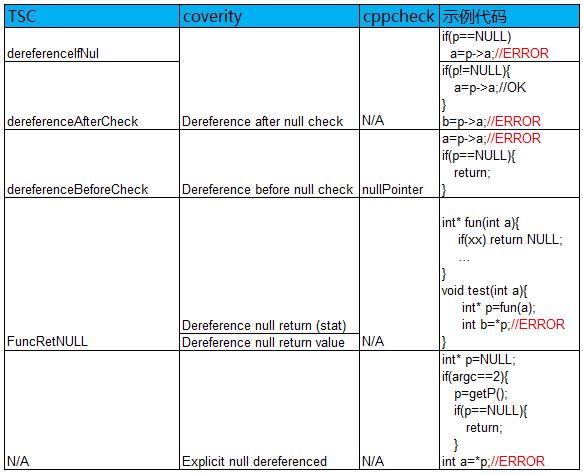
cppcheck扫描出来的问题存在大量误报,误报主要是冗余的判空,并不会引起实际问题,具体误报场景如下:
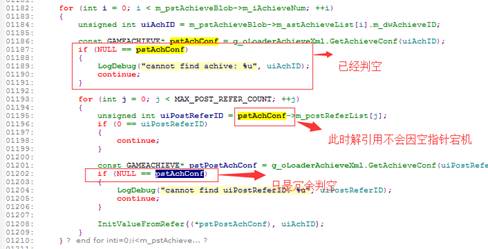
3. 从有效报错数量上,TSC有效报错数量更多,细分场景挖掘更多,无疑是扫描空指针最佳选择;clang覆盖的场景较少,其有效报错基本都能被coverity和TSC覆盖,不过由于其准确率较高且免费,与TSC搭配使用也是不错的选择;而coverity虽然覆盖场景多但因为只会报完全可信的问题,因此会漏掉部分有效报错,例如:指针变量来源于函数返回值,而函数返回值是否为NULL依赖于用户输入,在静态分析中coverity无法判断其是否会为NULL,为保证准确率会漏掉该指针报错。若项目对空指针漏报容忍度较高,且有足够预算采购商业软件,可以选择coverity;而cppcheck和pclint检查出的有效问题极少并伴随大量误报,同上结论,不宜使用。
4. 在易用性上,coverity和clang编译环境构建复杂,编译时长增加较多;TSC在易用性上也有一个缺点,即为提高准确率,在个别项目存在一次性配置工作。原因是个别项目存在自定义判空宏,但由于不依赖编译,TSC扫描的代码可能并不完整,导致个别自定义判空宏找不到,需要在cfg.ini中配置自定义判空宏。当然,如果扫描的代码完整度同编译环境,则无此问题。
4.2越界规则
越界一般来讲是指数组下标越界,或者缓冲区读写越界。这类错误会导致非法内存的访问,引发程序崩溃或者错误。
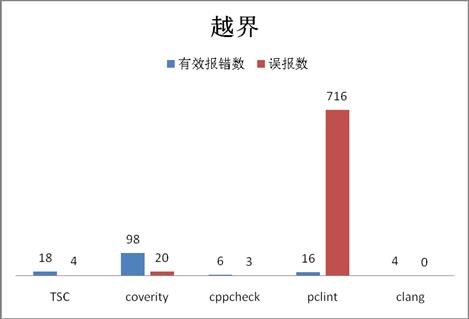
下图是五个工具对样本代码扫描结果:

注:越界对误报判定的规则比较严格,即使场景识别本身无误,但是通过代码逻辑可以推断该场景不会越界的也判定为误报。
例如:

这里由found变量间接推断出data[region_index]不会越界,将其判定为误报。
从报错数量和准确率来看:
有效报错数:coverity[98]>>TSC [18]>pclint[16] >cppcheck[6]> clang[4]
准确率: clang[100%] >coverity[80%]>TSC[70%] >cppcheck[67%]>>pclint[2%]
综合评分:coverity[90分] >TSC[54分]≈clang[55分]>cppcheck[40分]>pclint[1分]
1. 在报错数量上,coverity在越界检查上有较大的优势,因为coverity有较强的符号查找和场景识别能力,能识别相对复杂的越界场景。其他四个工具同coverity相比还有差距,其中pclint存在大量误报,表现最差。如:TSC和cppcheck只能识别数组变量本身越界,但如果是一个指针p指向数组的第一个元素,通过p[i]访问时的越界,TSC和cppcheck都无法检查,而coverity能找到p所指向的数组定义,得到数组大小,从而判断p[i]是否越界。
2. clang越界这块的准确率虽然最高为100%,但其覆盖的场景单一(strncpy使用越界报了4条),其报错都被TSC和coverity覆盖,数量上和其他工具有较大差距。TSC越界检查结果要略好于cppcheck,clang和pclint,TSC增加了对变量取值范围的推断,检测出是否存在越界的风险。比如:

(TSC越界有效报错场景)
对于数组下标iCountry的判定存在风险,代码执行到当前上下文时,iCountry可能取值为MAX_QT_COUNTRY_JIFEN_ITEM_CNT,而这正是数组m_astDataInDB的长度,也就是说在这种边界情况下会造成了数组访问越界。对于如上场景,应该将代码修改为iCountry>= MAX_QT_COUNTRY_JIFEN_ITEM_CNT。
4.3变量未初始化规则
变量未初始化顾名思义:变量声明后没有赋初值,其分配的内存值是随机的。这也是代码中容易出现的问题,会导致不确定的程序行为,造成严重的后果。
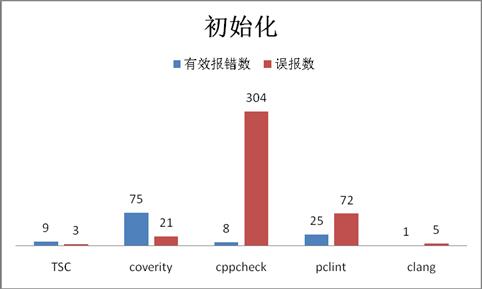
下图是五个工具对样本代码扫描结果:

注:结果排除了3个工具都有的检查项——构造函数中是否存在未初始化成员变量。在实际项目中发现,C++类构造函数中对成员变量不做初始化的情况是普遍的,很多代码会采用“延迟初始化”,即在实际用到该对象的时候调用类似Initialize的方法进行初始化。因此在此次对比中并没有把这条规则纳入进来。
从报错数量和准确率来看:
有效报错数:coverity[75]>>pclint[25] >TSC [9]>cppcheck[8]> clang[1]
准确率: TSC[75%] >coverity[68%]>pclint[26%] > clang[17%] >cppcheck[3%]
综合评分:coverity[82分] > TSC[47分] >pclint[30分] > clang[10分] >cppcheck[6分]
1. 在报错数量上,coverity初始化检查场景覆盖比其他四个工具要全,TSC为保持准确率,规则覆盖上比较保守,而cppcheck存在比较严重的误报问题,准确率仅为3%。pclint的误报也相对很高,clang在初始化这块显得无能为力。从上图可以很容易发现cppcheck的误报数量相当得高,cppcheck会将如下的场景判定为未初始化:

(cppcheck误报场景)
SMD_POS是一个简单的结构体,它包含了一个空的构造函数,cppcheck依据这点判定这是一个未初始化的错误。但这样的场景不会有什么问题,算是一个误报。这导致了cppcheck在未初始化规则的结果可信度大大降低。
2. coverity在未初始化这块的场景覆盖比较全,特别是对结构体对象的字段的初始化情况的检测,因为其基于编译可对变量做路径跟踪,例如:构造函数里面调用了init()函数,coverity会继续跟踪init()函数中是否有对变量的赋值,所以扫描覆盖场景最全。coverity的误报主要分为两类:一类是对几种未初始化场景的识别上存在问题,如:,变量在某个分支的确没有初始化,但用了一个状态标识其未初始化,当使用这个变量前会使用状态标记来判断其是否没有初始化,保证使用的变量都是初始化过了的。另一类就是上面提到的“低价值报错”,即通过代码逻辑或者做了代码保护,保证变量不会因为没有初始化而产生实际的问题。如:一个表示时间的结构体,里面字段有year,month,day,hour,min,day这个字段没有初始化,但实际代码中也没有用到这个字段,因此并不会产生任何问题。
TSC在未初始化变量的检查因不具备路径分析能力,而以分支作用域检查特定变量在各个代码分支的初始化情况,误报率保持在相对低的一个水平。但场景覆盖较少,没有针对结构体字段的初始化场景做覆盖。因为对结构字段的初始化方式相对比较多样:逐个字段初始化,函数调用初始化,构造函数初始化等。
4.4内存/资源泄露规则
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存,从而造成了内存浪费的情况。内存泄漏是静态下很难检测的一种错误,一般需要动态分析工具进行检测,如valgrind工具会捕获malloc()/free()/new/delete的调用,监控内存分配和释放,从动态上检测程序是否存在内存泄漏。因此,静态代码分析能检查的内存泄漏就非常有限了,当前各工具主要是从代码写法上检查内存分配和释放是否配对使用。比如:fopen打开文件后在退出函数前是否有执行fclose,new[]和delete[]是否配对使用等。
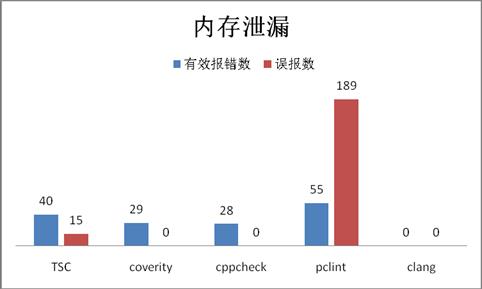
下图是五个工具对样本代码扫描结果:

注:以上数据排除了cppcheck35个低价值报错,这里排除的cppcheck35个报错都是基本数据类型的new和delete不匹配(如char* p=new char[100];delete p;)虽然这种写法不规范,但由于实际上不会造成内存泄漏,很多项目不会对此进行修复。
从报错数量和准确率来看:
有效报错数:pclint[55] >TSC[40]>coverity [29]>cppcheck[28]> clang[0]
准确率: coverity[100%]=cppcheck[100%] >TSC[73%]>pclint[23%] > clang[N/A]
综合评分:coverity[79分] ≈ TSC [73分]≈cppcheck[77分]>pclint[57分]>clang[0分]
从报错数量上看出,在内存泄漏检查方面,pclint虽然发现有效问题最多,但误报很高,不推荐使用。TSC的有效错误数比coverity和cppcheck多,但误报也相对较高。clang则不具备泄露类场景的检测能力。
注:由于静态扫描能检查的内存泄露场景都非常明确,因此一般都不会出现问题,TSC的15个误报也非场景识别有误而是工具底层bug导致,后续会对底层bug进行修复。如:#ifdef 和#else分支中各有一个fopen,实际编译时只会走其中1个分支识别1次fopen,但由于底层bug识别了2次fopen,导致误报。
4.5逻辑错误规则
逻辑错误:指可能存在的逻辑问题,如if不同分支内容相同,在switch内缺少break等,对指针使用sizeof进行空间分配等问题。
下图是五个工具对样本代码扫描结果:
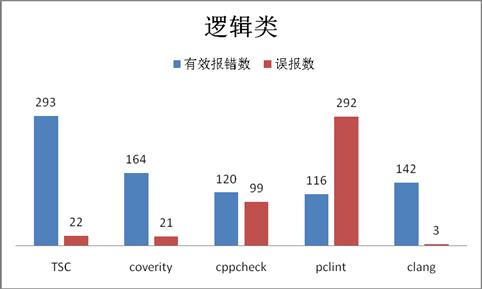

注:这些报错中剔除了一些无修改意义且结果数量很多规则:如:coverity扫描存在7484条Logically dead code(逻辑代码不可达)报错。cppcheck存在2246条unusedFunction(函数未被使用)报错。
从报错数量和准确率来看
有效数量:TSC[293]>coverity[164]>clang[142] >cppcheck [120]>pclint[116]
准确率:clang[97%] >TSC[93%]>coverity(88%)>pclint[72%] >cppcheck[55%]
综合评分:coverity[94分] > TSC[86分] > clang[80分] >cppcheck[63分] >pclint[27分]
从报错数量和准确率上可以看出TSC可以更有效的发现逻辑类问题。但各工具逻辑类场景各有特色,互为互补,可以一同选择扫描,但cppcheck和pclint准确率较低,可以较少选择。clang的准确率最高,但clang扫描出来的逻辑错误中有一大半为低价值的逻辑错误,比如clang扫描出来的142条逻辑错误中就有140条“变量赋值但没有使用”错误。
1. TSC,coverity具备较强宏展开能力
以DuplicateExpression规则为例,TSC发现DuplicateExpression规则报错32条, cppcheck发现DuplicateExpression规则报错12条。因为TSC可以对宏进行更有效展开,例如:
这种报错TSC可以准确的识别出来,宏MAX_TASK_TAB_SIZE和MAX_TASK_RES_NUM为相同的数值,而cppcheck无法区分发现这类问题,只能进行简单的文本匹配。coverity在推断能力上也不差,在这点也明显优于cppcheck。
2. TSC规则类型更有效
经过筛选,TSC只保留价值更高的推断和有效规则;
Ø 增加一些函数检查规则,如:MemsetZeroBytes,这种错误的Memset写法:memset(ctYear, sizeof(ctYear), 0);可疑的数组下标使用等这些规则在coverity逻辑类检查中并没有体现,而coverity只会报出非常准确的报错如:if分支完全相同等检查项。
Ø 剔除价值低的无效规则,如coverity规则Logically dead code,指一些逻辑上不可达的废弃代码;cppcheck规则memsetClassFloatc指对存在Float类型成员变量的Class使用Memset,当时代码中发现基本都是Memset为0,并不会有数据丢失等问题。故这类规则发现有效问题很低,在数量较大的情况下,需要耗费大量的人力来确认,性价比不高,TSC已经将这种规则剔除。
总的来说,TSC在发现问题和准确率方面表现都不错,可以节省大量的人力在锁定逻辑类型错误。
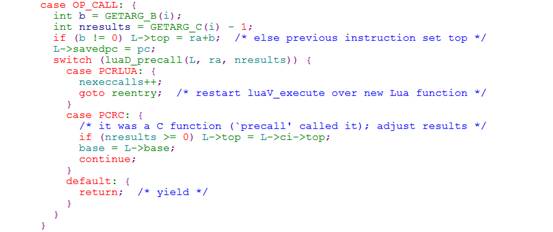
TSC在某些细小规则的推断能力上比coverity要稍微弱一些,如规则Missing break in switch:coverity发现全部准确的报错,TSC存在一定的误报,这些复杂场景需要较强的动态计算如:
5 常见误报场景
5.1 空指针常见误报场景
误报场景一(cppcheck)
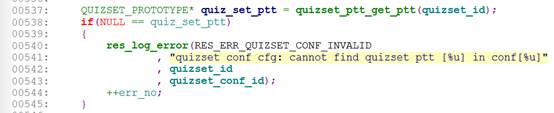
以上538行代码报quiz_set_ptt存在空指针访问。
误报原因:538行只是指针的比较,并没有解引用,这是一个比较低级的误报。
误报场景二(coverity)

以上119行代码报actor存在空指针访问,判定逻辑如下:112行对actor进行了判空,说明actor在当前上下文可能为空。所以119行actor可能为空。
误报原因:xy_assert_retval是个宏,展开后包含有return语句,即如果actor为空115行就返回了,119行actor不会为空。
5.2 越界常见误报场景
误报场景一(TSC)

以上83行代码报第数组访问可能越界,判定逻辑如下:第61行的if语句对req_list.num的取值范围作了限制,req_list.num在当前上下文的最大值可以是MAX_RECRUIT_REQ_LIST_SIZE(4);83行req_list.数组对象用req_list.num作为其数组访问的下标,当req_list.num取值为MAX_RECRUIT_REQ_LIST_SIZE时发生越界(req_list.数组的长度为MAX_RECRUIT_REQ_LIST_SIZE(4))。
误报原因:第79行的if条件保证了之后的代码req_list.num的值不会等于MAX_RECRUIT_REQ_LIST_SIZE,所以这是一个误报。
误报场景二(cppcheck)
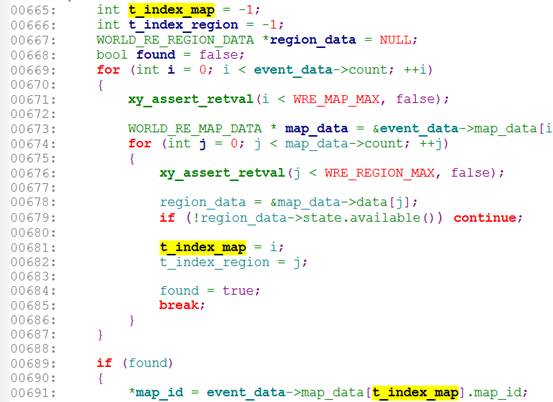
以上第691行代码报t_index_map可能取值-1越界,判定逻辑如下:665行声明t_index_map并赋值为-1,t_index_map的赋值在681行,但681行在for循环里面,而for循环存在不能进入的可能性,所以在691行使用t_index_map可能未初始化。
误报原因:进入691行代码的前提条件是found变量为true,而found为true保证了t_index_map被赋值了。
误报场景三(coverity)

以上第146行代码报src_index + 1可能取值为4越界,判定逻辑如下:139行对src_idx的取值范围进行了限定:0, 3,因此146行src_idx + 1可能为4导致对team_ptr->team_member访问越界。
误报原因:144行对src_idx的取值范围进行了过滤,保证了src_idx+1不会越界。
5.3未初始化常见误报场景
误报场景一(cppcheck)

以上第462行代码报ret未初始化错误,判定逻辑如下:ret变量在第434行声明,在switch中的两个case中均有初始化代码,但是在default分支中没有对ret进行初始化,因此判定462行可能会返回一个没有初始化的ret。
误报原因:default分支中的xy_assert_retval是一个宏,因为cppcheck宏查找策略的原因导致该宏没有展开。实际上宏展开包含了return语句,也就是说如果进入default分支就函数就直接返回而不会执行到462行代码。
误报场景二(coverity)
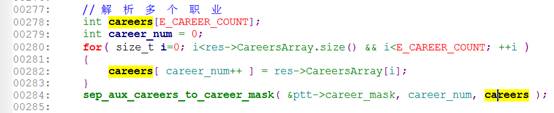
以上第284行代码报careers未初始化错误,判定逻辑如下:careers数组在第278行声明,但在for循环对每个数组成员进行了初始化。这可能造成careers完全没有初始化,或者只初始化了一部分。因此在284行使用careers存在未初始化错误。
误报原因:通过代码逻辑可知,career_num代表的是careers被初始化的长度,在访问careers数组元素的时候,通过career_num进行了保护,因此不会出现未初始化的错误。
5.4泄露类常见误报场景
误报场景一(TSC)
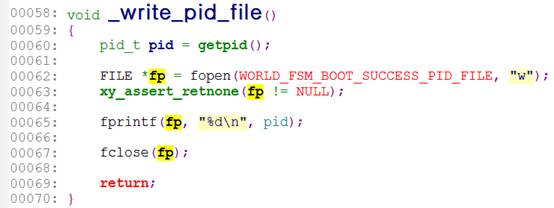
以上第63行代码报fp存在资源泄露风险错误,判定逻辑如下:xy_assert_retnone宏展开后,含有return语句,也就是说fp在调用fclose之前可能返回,存在泄露风险。
误报原因:实际上代码逻辑决定了函数return的前提条件fp为空。这个时候是没有必要调用fclose的,不存在泄露风险。
误报场景二(pclint)

以上第139行代码(~CGIProcessor(), 析构函数)报存在资源泄露风险错误,因为没有释放_cgiContainer。判定逻辑如下:_cgiContainer作为CGIProcessor的一个指针成员(第149行),需要在析构函数中进行释放,否则为内存泄露。
误报原因:CGIProcessor对象并不own _cgiContainer指向的对象,不需要它来释放。
5.5逻辑类常见误报场景
误报场景一(cppcheck)

以上4596行代码报“对包含有float成员的对象调用memset方法”错误。
误报原因:利用memset对一个对象的数据字段清零是比较常见的做法,float成员清零后值也为0,不会造成什么问题。
本文由腾讯WeTest团队提供,未经授权严禁转载!更多资讯可直接戳链接查看:http://wetest.qq.com/lab/
微信号:TencentWeTest
以上是关于代码质量C++代码质量扫描主流工具深度比较的主要内容,如果未能解决你的问题,请参考以下文章