etcd Raft 源码剖析
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了etcd Raft 源码剖析相关的知识,希望对你有一定的参考价值。
文章目录
Raft源码阅读
etcd 是 coreOS 使用 golang 开发的分布式,一致性的 kv 存储系统,因其易用性和高可靠性被广泛运用于服务发现、消息发布和订阅、分布式锁和共享配置等方面,也被认为是 zookeeper 的强有力的竞争者。
作为分布式 kv,其底层使用 raft 算法实现多副本数据的强一致性。etcd 作为 raft 开源实现的标杆,在设计上,将 raft 算法逻辑和持久化、网络、线程等完全抽离出来单独实现,充分解耦,在工程上,实现了诸多性能优化,是 raft 开源实践中较早的工业级的实现,很多后来的 raft 实践者都直接或者间接的参考了 ectd-raft 的设计和实现,例如 kubernetes,TIdb 等。其广泛的影响力和优雅的 golang 代码实践也使得 ectd 成为 golang 的明星项目。
在我们实际的分布式存储系统的项目开发中,raft 也被应用于元信息管理和数据存储等多个模块,因此熟悉和理解 etcd-raft 的实现具有重大意义,本文的主要内容就是分析 raft 在 ectd 中的具体实现。
源码链接:etcd
中文注释:etcd-中文注释
代码结构
首先给出代码结构,然后按照各个模块依次介绍
$ tree --dirsfirst -L 1 -I '*test*' -P '*.go'
.
├── raftpb
├── doc.go
├── log.go
├── log_unstable.go
├── logger.go
├── node.go
├── progress.go
├── raft.go
├── rawnode.go
├── read_only.go
├── status.go
├── storage.go
└── util.go
消息结构
Raft 的序列化是基于 Protocol Buffer 实现的,因此在该目录下就定义了几个需要序列化的数据结构。
Entry
从整体上来说,一个集群中的每个节点都是一个状态机,而 raft 管理的就是对这个状态机进行更改的一些操作,这些操作在代码中被封装为一个个 Entry。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/raftpb/raft.pb.go
type Entry struct
Term uint64 //选举任期,每次选举之后递增1。用于标记信息的时效性
Index uint64 //当前这个entry在整个raft日志中的位置索引
Type EntryType //当前entry的类型,目前etcd支持两种类型:EntryNormal和EntryConfChange,EntryNormal代表当前Entry是对状态机的操作,EntryConfChange则代表对当前集群配置进行更改的操作
Data []byte //被序列化后的byte数组,代表当前entry真正要执行的操作。当Type为EntryNormal时为key-value pair;当Type为EntryConfChange时为ConfChange
Message
Raft 集群中节点之间通过传递不同的 Message 来完成通讯,这个 Message 结构涵盖了各种消息所需的字段。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/raftpb/raft.pb.go
type Message struct
Type MessageType //消息类型(心跳MsgHeartbeat、日志MsgApp、投票MsgVote等)
To uint64 //这个消息的接受者
From uint64 //这个消息的发送者
Term uint64 //这个消息发出时整个集群所处的任期,即逻辑时钟
LogTerm uint64 //消息发出者所保存的日志中最后一条的任期号
Index uint64 //日志索引号。如果当前消息是MsgVote的话,代表这个候选人最后一条日志的索引号
Entries []Entry //需要存储的日志
Commit uint64 //已经提交的日志的索引值,用来向别人同步日志的提交信息
Snapshot Snapshot //快照
Reject bool //对方节点拒绝了当前节点的请求(MsgVote/MsgApp/MsgSnap…)
RejectHint uint64 //对方节点拒绝了当前节点的请求(MsgVote/MsgApp/MsgSnap…)
Context []byte //上下文信息
日志模块
log_unstable.go
unstable 数据结构用于还没有被用户层持久化的数据,它维护了两部分内容 snapshot 和 entries 。由于日志信息不可能无休止的增长,所以超过一定期限后就会被删除。而为了能保证将数据完整的同步到其他节点上,每个一段时间就会将当前的状态存储为快照的形式,此时新节点只需要以快照为基础,再执行快照之后的日志(通过offset确定),就可以完成状态同步。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/log_unstable.go
type unstable struct
// 保存还没有持久化的快照数据
snapshot *pb.Snapshot
// 还未持久化的数据
entries []pb.Entry
// offset用于保存entries数组中的数据的起始index
offset uint64
logger Logger
具体结构关系如下图
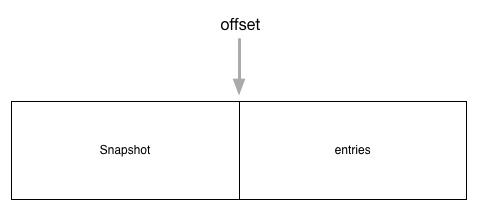
Storage
这个文件定义了一个 Storage 接口,因为 etcd 中的 raft 实现并不负责数据的持久化,所以它希望上面的应用层能实现这个接口,以便提供给它查询 log 的能力。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/storage.go
type Storage interface
// 返回保存的初始状态
InitialState() (pb.HardState, pb.ConfState, error)
// 返回索引范围在[lo,hi)之内并且不大于maxSize的entries数组
Entries(lo, hi, maxSize uint64) ([]pb.Entry, error)
// 传入一个索引值,返回这个索引值对应的任期号,如果不存在则error不为空,其中:
// ErrCompacted:表示传入的索引数据已经找不到,说明已经被压缩成快照数据了。
// ErrUnavailable:表示传入的索引值大于当前的最大索引
Term(i uint64) (uint64, error)
// 获得最后一条数据的索引值
LastIndex() (uint64, error)
// 返回第一条数据的索引值
FirstIndex() (uint64, error)
// 返回最新的快照数据
Snapshot() (pb.Snapshot, error)
另外,这个文件也提供了 Storage 接口的一个内存版本的实现 MemoryStorage,这个实现同样也维护了 snapshot 和 entries 这两部分,他们的排列跟 unstable 中的类似,也是 snapshot 在前,entries 在后。从代码中看来 etcdserver 和 raftexample 都是直接用的这个实现来提供 log 的查询功能的。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/storage.go
// 使用在内存中的数组来实现 Storage 接口的结构体,具体实现参考上面的链接
type MemoryStorage struct
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
ents []pb.Entry
log.go
这个结构体承担了 raft 日志相关的操作。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/log.go
type raftLog struct
// 用于保存自从最后一次snapshot之后提交的数据
storage Storage
// 用于保存还没有持久化的数据和快照,这些数据最终都会保存到storage中
unstable unstable
// committed数据索引
committed uint64
// committed保存是写入持久化存储中的最高index,而applied保存的是传入状态机中的最高index
// 即一条日志首先要提交成功(即committed),才能被applied到状态机中
// 因此以下不等式一直成立:applied <= committed
applied uint64
logger Logger
一条日志数据,首先需要被 committed 成功,然后才能被应用 applied 到状态机中。因此,以下不等式一直成立:applied <= committed。
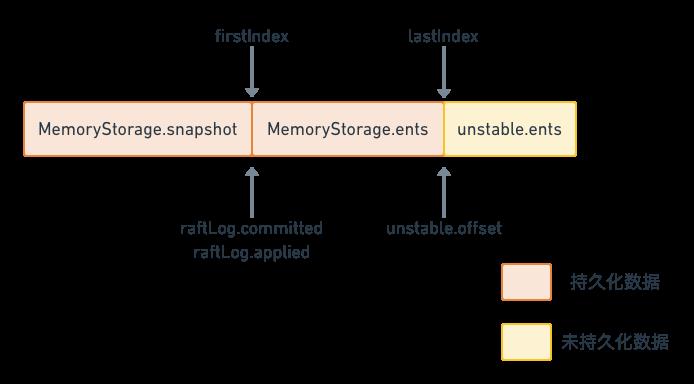
这个数据布局从下面这段初始化函数也可以看出
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/log.go
func newLog(storage Storage, logger Logger) *raftLog
if storage == nil
log.Panic("storage must not be nil")
log := &raftLog
storage: storage,
logger: logger,
firstIndex, err := storage.FirstIndex()
if err != nil
panic(err) // TODO(bdarnell)
lastIndex, err := storage.LastIndex()
if err != nil
panic(err) // TODO(bdarnell)
// offset从持久化之后的最后一个index的下一个开始
log.unstable.offset = lastIndex + 1
log.unstable.logger = logger
// committed和applied从持久化的第一个index的前一个开始
log.committed = firstIndex - 1
log.applied = firstIndex - 1
return log
持久化存储和非持久化存储的分界线其实就是 lastIndex。在此之前都是 Storage 管理的已经持久化的数据,而在此之后都是 unstable 管理的还没有持久化的数据。
状态机
progress.go
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/progress.go
type Progress struct
// Next保存的是下一次leader发送append消息时传送过来的日志索引
// 当选举出新的leader时,首先初始化Next为该leader最后一条日志+1
// 如果向该节点append日志失败,则递减Next回退日志,一直回退到索引匹配为止
// Match保存在该节点上保存的日志的最大索引,初始化为0
// 正常情况下,Next = Match + 1
// 以下情况下不是上面这种情况:
// 1. 切换到Probe状态时,如果上一个状态是Snapshot状态,即正在接收快照,那么Next = max(pr.Match+1, pendingSnapshot+1)
// 2. 当该follower不在Replicate状态时,说明不是正常的接收副本状态。
// 此时当leader与follower同步leader上的日志时,可能出现覆盖的情况,即此时follower上面假设Match为3,但是索引为3的数据会被
// leader覆盖,此时Next指针可能会一直回溯到与leader上日志匹配的位置,再开始正常同步日志,此时也会出现Next != Match + 1的情况出现
Match, Next uint64
// 三种状态
// ProgressStateProbe:探测状态
// ProgressStateReplicate:副本状态
// ProgressStateSnapshot:快照状态
State ProgressStateType
// 在状态切换到Probe状态以后,该follower就标记为Paused,此时将暂停同步日志到该节点
Paused bool
// 如果向该节点发送快照消息,PendingSnapshot用于保存快照消息的索引
// 当PendingSnapshot不为0时,该节点也被标记为暂停状态。
// raft只有在这个正在进行中的快照同步失败以后,才会重传快照消息
PendingSnapshot uint64
// 如果进程最近处于活跃状态则为 true(收到来自跟随者的任意消息都认为是活动状态)。在超时后会重置重置为false
RecentActive bool
// 用于实现滑动窗口,用来做流量控制
ins *inflights
对于不同的状态,其会采取不同的行为:
- ProgressStateProbe:探测状态,当 follower 拒绝了最近的 append 消息时,那么就会进入探测状态,此时 leader 会试图继续往前追溯该 follower 的日志从哪里开始丢失的。在 probe 状态时,leader 每次最多 append 一条日志,如果收到的回应中带有
RejectHint信息,则回退Next索引,以便下次重试。在初始时,leader 会把所有 follower 的状态设为 probe,因为它并不知道各个 follower 的同步状态,所以需要慢慢试探。 - ProgressStateReplicate:当 leader 确认某个 follower 的同步状态后,它就会把这个 follower 的 state 切换到这个状态,并且用
pipeline的方式快速复制日志。leader 在发送复制消息之后,就修改该节点的Next索引为发送消息的最大索引 + 1。 - ProgressStateSnapshot:接收快照状态。当 leader 向某个 follower 发送 append 消息,试图让该 follower 状态跟上 leader 时,发现此时 leader上保存的索引数据已经对不上了,比如leader在index为10之前的数据都已经写入快照中了,但是该 follower 需要的是 10 之前的数据,此时就会切换到该状态下,发送快照给该 follower。当快照数据同步追上之后,并不是直接切换到 Replicate 状态,而是首先切换到 Probe 状态。
从上面我们可以看出 Progress 是个状态机,下面是它的状态转移图:
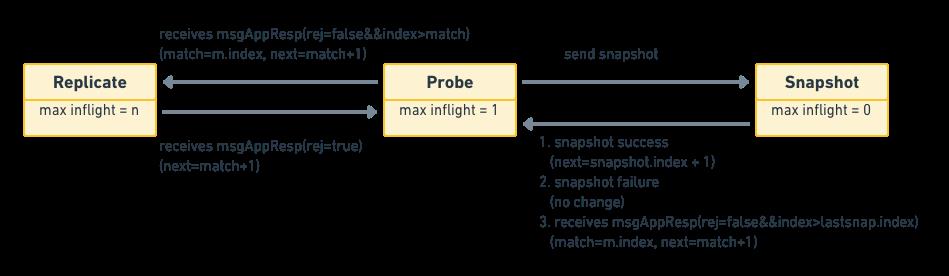
核心算法
raft.go
前面介绍了消息、日志、状态机,接下来就是 raft 的核心实现。其中大部分的逻辑都在状态机函数 Step 中:
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/raft.go
// raft的状态机
func (r *raft) Step(m pb.Message) error
r.logger.Infof("from:%d, to:%d, type:%s, term:%d, state:%v", m.From, m.To, m.Type, r.Term, r.state)
// Handle the message term, which may result in our stepping down to a follower.
switch
case m.Term == 0:
// 来自本地的消息
case m.Term > r.Term:
// 消息的Term大于节点当前的Term
lead := m.From
if m.Type == pb.MsgVote || m.Type == pb.MsgPreVote
// 如果收到的是投票类消息
// 当context为campaignTransfer时表示强制要求进行竞选
force := bytes.Equal(m.Context, []byte(campaignTransfer))
// 是否在租约期以内
inLease := r.checkQuorum && r.lead != None && r.electionElapsed < r.electionTimeout
if !force && inLease
// 如果非强制,而且又在租约期以内,就不做任何处理
// 非强制又在租约期内可以忽略选举消息,见论文的4.2.3,这是为了阻止已经离开集群的节点再次发起投票请求
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: lease is not expired (remaining ticks: %d)",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term, r.electionTimeout-r.electionElapsed)
return nil
// 否则将lead置为空
lead = None
switch
// 注意Go的switch case不做处理的话是不会默认走到default情况的
case m.Type == pb.MsgPreVote:
// Never change our term in response to a PreVote
// 在应答一个prevote消息时不对任期term做修改
case m.Type == pb.MsgPreVoteResp && !m.Reject:
default:
r.logger.Infof("%x [term: %d] received a %s message with higher term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
// 变成follower状态
r.becomeFollower(m.Term, lead)
case m.Term < r.Term:
// 消息的Term小于节点自身的Term,同时消息类型是心跳消息或者是append消息
if r.checkQuorum && (m.Type == pb.MsgHeartbeat || m.Type == pb.MsgApp)
// 收到了一个节点发送过来的更小的term消息。这种情况可能是因为消息的网络延时导致,但是也可能因为该节点由于网络分区导致了它递增了term到一个新的任期。
// ,这种情况下该节点不能赢得一次选举,也不能使用旧的任期号重新再加入集群中。如果checkQurom为false,这种情况可以使用递增任期号应答来处理。
// 但是如果checkQurom为True,
// 此时收到了一个更小的term的节点发出的HB或者APP消息,于是应答一个appresp消息,试图纠正它的状态
r.send(pb.MessageTo: m.From, Type: pb.MsgAppResp)
else
// ignore other cases
// 除了上面的情况以外,忽略任何term小于当前节点所在任期号的消息
r.logger.Infof("%x [term: %d] ignored a %s message with lower term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
// 在消息的term小于当前节点的term时,不往下处理直接返回了
return nil
//核心流程
switch m.Type
case pb.MsgHup:
// 收到HUP消息,说明准备进行选举
if r.state != StateLeader
// 当前不是leader
// 取出[applied+1,committed+1]之间的消息,即得到还未进行applied的日志列表
ents, err := r.raftLog.slice(r.raftLog.applied+1, r.raftLog.committed+1, noLimit)
if err != nil
r.logger.Panicf("unexpected error getting unapplied entries (%v)", err)
// 如果其中有config消息,并且commited > applied,说明当前还有没有apply的config消息,这种情况下不能开始投票
if n := numOfPendingConf(ents); n != 0 && r.raftLog.committed > r.raftLog.applied
r.logger.Warningf("%x cannot campaign at term %d since there are still %d pending configuration changes to apply", r.id, r.Term, n)
return nil
r.logger.Infof("%x is starting a new election at term %d", r.id, r.Term)
// 进行选举
if r.preVote
r.campaign(campaignPreElection)
else
r.campaign(campaignElection)
else
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
case pb.MsgVote, pb.MsgPreVote:
// 收到投票类的消息
if (r.Vote == None || m.Term > r.Term || r.Vote == m.From) && r.raftLog.isUpToDate(m.Index, m.LogTerm)
// 如果当前没有给任何节点投票(r.Vote == None)或者投票的节点term大于本节点的(m.Term > r.Term)
// 或者是之前已经投票的节点(r.Vote == m.From)
// 同时还满足该节点的消息是最新的(r.raftLog.isUpToDate(m.Index, m.LogTerm)),那么就接收这个节点的投票
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] cast %s for %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.MessageTo: m.From, Type: voteRespMsgType(m.Type))
if m.Type == pb.MsgVote
// 保存下来给哪个节点投票了
r.electionElapsed = 0
r.Vote = m.From
else
// 否则拒绝投票
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.MessageTo: m.From, Type: voteRespMsgType(m.Type), Reject: true)
default:
// 其他情况下进入各种状态下自己定制的状态机函数
r.step(r, m)
return nil
将具体逻辑代码去掉,其实我们可以得到以下框架
func (r *raft) Step(m pb.Message) error
//...
switch m.Type
case pb.MsgHup:
//...
case pb.MsgVote, pb.MsgPreVote:
//...
default:
r.step(r, m)
Step 其实就是根据消息类型的不同(MsgHup/MsgVote/MsgPreVote)而去执行对应的逻辑(状态机)。而对于其他状态,此时则会执行 default 中的 step(函数指针,根据节点角色执行不同的函数stepLeader/stepFollower/stepCandidate)
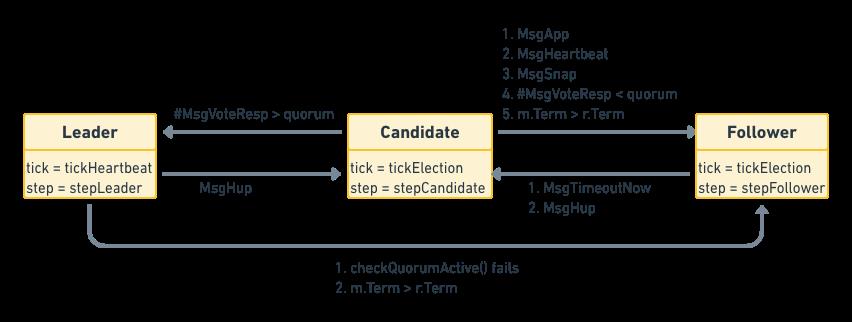
node.go
node 其实是应用层和 Raft 协议层之间的中转站,其将上层应用层的消息传递给底层协议层模块,并将协议层的结果反馈给应用层。从代码后半段中可以看到,这里通过 for-select 从 channel 中不断处理数据。
//https://github.com/lichuang/etcd-3.1.10-codedump/blob/master/raft/node.go
func (n *node) run(r *raft)
var propc chan pb.Message
var readyc chan Ready
var advancec chan struct
var prevLastUnstablei, prevLastUnstablet uint64
var havePrevLastUnstablei bool
var prevSnapi uint64
var rd Ready
lead := None
prevSoftSt := r.softState()
prevHardSt := emptyState
for
if advancec != nil
// advance channel不为空,说明还在等应用调用Advance接口通知已经处理完毕了本次的ready数据
readyc = nil
else
rd = newReady(r, prevSoftSt, prevHardSt)
if rd.containsUpdates()
// 如果这次ready消息有包含更新,那么ready channel就不为空
readyc = n.readyc
else
// 否则为空
readyc = nil
if lead != r.lead
// 如果leader发生了变化
if r.hasLeader() // 如果原来有leader
if lead == None
// 当前没有leader
r.logger.Infof("raft.node: %x elected leader %x at term %d", r.id, r.lead, r.Term)
else
// leader发生了改变
r.logger.Infof("raft.node: %x changed leader from %x to %x at term %d", r.id, lead, r.lead, r.Term)
// 有leader,那么可以进行数据提交,prop channel不为空
propc = n.propc
else
// 否则,prop channel为空
r.logger.Infof("raft.node: %x lost leader %x at term %d", r.id, lead, r.Term)
propc = nil
lead = r.lead
select
// TODO: maybe buffer the config propose if there exists one (the way
// described in raft dissertation)
// Currently it is dropped in Step silently.
case m := <-propc:
// 处理本地收到的提交值
m.From = r.id
r.Step(m)
case m := <-n.recvc:
// 处理其他节点发送过来的提交值
// filter out response message from unknown From.
if _, ok := r.prs[m.From]; ok || !IsResponseMsg(m.Type)
// 需要确保节点在集群中或者不是应答类消息的情况下才进行处理
r.Step(m) // raft never returns an error
case cc := <-n.confc:
// 接收到配置发生变化的消息
if cc.NodeID == None
// NodeId为空的情况,只需要直接返回当前的nodes就好
r.resetPendingConf()
select
case n.confstatec <- pb.ConfStateNodes: r.nodes():
case <-n.done:
break
switch cc.Type
case pb.ConfChangeAddNode:
r.addNode(cc.NodeID)
case pb.ConfChangeRemoveNode:
// block incoming proposal when local node is
// removed
// 如果删除的是本节点,停止提交
if cc.NodeID == r.id
propc = nil
r.