大数据之Spark:Spark面试(高级)
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Spark:Spark面试(高级)相关的知识,希望对你有一定的参考价值。
目录
- 19:RDD、DataFrame和DataSet的区别
- 20:groupbyKey和reduceBykey的区别
- 21:coalesce和repartition的区别
- 22:说说cache和persist的异同
- 23:连续登陆问题SQL
- 24:SparkStreaming怎么保证精准一次消费
19:RDD、DataFrame和DataSet的区别
- RDD和DataFrame、Dataset的共性
三者均为Spark分布式弹性数据集,Spark 2.x 的DataFrame被Dataset合并,现在只有DataSet和RDD。三者有许多相同的算子如filter、map等,且均具有惰性执行机制。

2. DataFrame和DataSet的区别
DataFrame是分布式Row对象的集合,所有record类型均为Row。Dataset可以认为是DataFrame的特例,每个record存储的是强类型值而不是Row,同理Dataframe可以看作Dataset[Row]。
- RDD、DataFrame和Dataset转换
DataFrame/DataSet转换为RDD
val rdd1 = myDF.rdd
RDD转换为DataFrame/Dataset (spark低版)
import spark.implicits._
val myDF = rdd.map line=> (line._1,line._2)
.toDF("col1","col2")
RDD转换为Dataset
import spark.implicits._
case class ColSet(col1:String,col2:Int) extends Serializable
val myDS = rdd.map row=>
ColSet(row._1,row._2)
.toDS
-
Spark SQL中的RDD和Dataset
RDD无法支持Spark sql操作,而dataframe和dataset均支持。
20:groupbyKey和reduceBykey的区别
在介绍groupByKey和reduceByKey的区别之前,首先介绍一下什么是聚合算子:
根据Key进行分组聚合,解决<K, V>类型的数据计算问题

在Spark中存在很多聚合算子,常用于处理分类统计等计算场景。
分组:groupByKey算子
聚合:reduceByKey算子
本地聚合:CombineByKey算子
- CombineByKey算子
聚合算子内部调用的基础算子之一,程序调用CombineByKey算子时会在本地预先进行规约计算,类似于Mapreduce Shuffle中Map阶段的Combine阶段,先看一下执行原理:
为各分区内所有Key创建累加器对象并赋值
每次计算时分区内相同Key的累加器值加一
合并各分区内相同Key的值

2. ReduceByKey算子
内部调用CombineByKey算子实现。即先在本地预聚合,随后在分布式节点聚合,最终返回(K, V) 数据类型的计算结果。通过第一步本地聚合,大幅度减少跨节点shuffle计算的数据量,提高聚合计算的效率。

3. GroupByKey算子
GroupByKey内部禁用CombineByKey算子,将分区内相同Key元素进行组合,不参与聚合计算。此过程会和ReduceByKey一致均会产生Shuffle过程,但是ReduceByKey存在本地预聚合,效率高于GroupByKey。
在聚合计算场景下,计算效率低于ReduceBykey
可以搭配mapValues算子实现ReduceByKey的聚合计算

21:coalesce和repartition的区别
两个算子都可以解决Spark的小文件过多和分区数据倾斜问题。举个例子,在使用Spark进行数据处理的过程中,常常会调用filter方法进行数据预处理,频繁的过滤操作会导致分区数据产生大量小文件碎片,当shuffle过程读取分区文件时极容易产生数据倾斜现象。
Spark通过repartition和coalesce算子来控制分区数量,通过合并小分区的方式保持数据紧凑型,提高分区的利用率。
- 内部实现机制
首先打开repartition的源码,可以看到方法仅存在一个参数: numPartitions(分区数),这里表示需要合并的分区数量。再细看内部调用的是coalesce(shuffle=true)函数,即核心逻辑还是由coalesce()实现,且过程会产生shuffle操作。

再次定位到coalesce()方法内部,可以看到根据shuffle的条件判断,先通过生成随机数将partition重新组合,随后生成CoalesceRDD进行后续的逻辑处理。
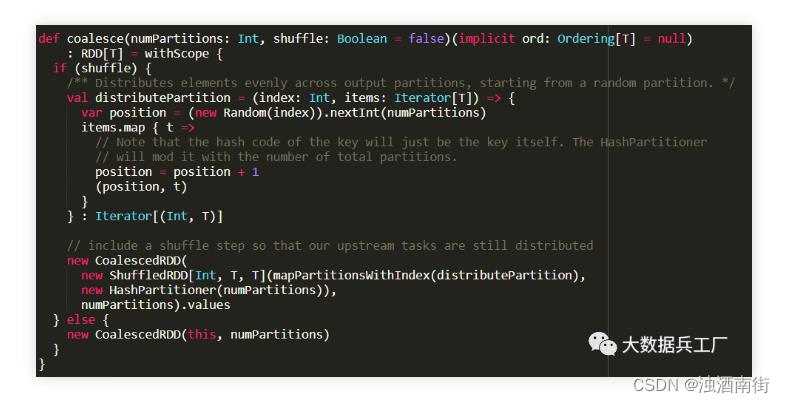
2. 分区重分配原则
当分区数大于原分区时,类型为宽依赖(shuffle过程),需要把coalesce的shuffle参数设为true,执行HashPartition重新扩大分区,这时调用repartition()
当分区数两者相差不大时,类型为窄依赖,可以进行分区合并,这时调用coalesce()
当分区数远远小于原分区时,需要综合考虑不同场景的使用
22:说说cache和persist的异同
-
cache()方法内部调用了persist()
-
persist()方法存在多种缓存级别,默认为Momory
-
cache()只有一个默认的缓存级别MEMORY_ONLY
-
persist()可以根据情况设置其它的缓存级别

23:连续登陆问题SQL
这是一个经典的SQL面试题,例如计算平台连续登陆3天以上的用户统计,诸如此类网上存在很多种答案,这里放上其中一种解题思路的SQL实现和DataFrame实现版本。
- 实现思路
将用户分组并按照时间排序,并记录rank排名
计算dt-rank的差值,差值与用户共同分组
统计count并找出 count > 3的用户
- Spark DataFrame实现

- Spark SQL实现

24:SparkStreaming怎么保证精准一次消费
实时场景下的Spark Streaming流处理,通过Receiver组件实时接收数据,最终将连续的Dstream数据流转换为微批RDD在Spark引擎中执行。Spark Streaming实时场景中最通用数据源是Kafka,一个高性能、分布式的实时消息队列。Spark Streaming最大化实时消费Kafka分区数据,提供秒级响应计算服务。
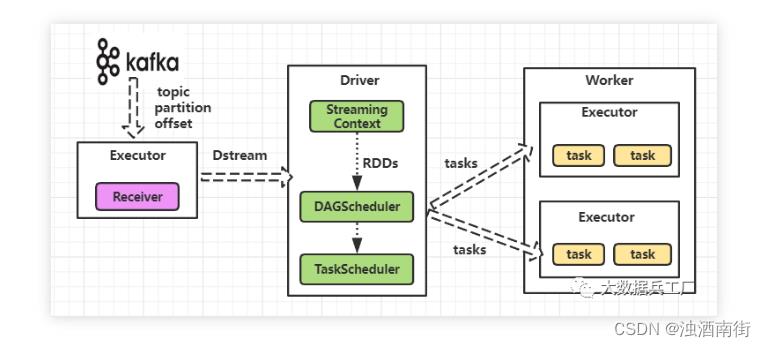
Spark Streaming保证精确一次消费,需要整个实时系统的各环节均保持强一致性。即可靠的Kafka端(数据可重复读取、不丢失)、可靠的消费端(Spark内部精确一次消费)、可靠的输出端(幂等性、事务)。具体细节可查看我的文章:Spark的Exactly-Once一致性。
以上是关于大数据之Spark:Spark面试(高级)的主要内容,如果未能解决你的问题,请参考以下文章