Python爬虫之九阴真经
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之九阴真经相关的知识,希望对你有一定的参考价值。
参考技术A用Python 探索 金庸笔下的江湖!
带你用python看小说, 娱乐 学习两不误。
涉及的知识点有:
本文从传统匹配逻辑分析过渡到机器学习的词向量,全方位进行文本分析,值得学习,干货满满。( 文末点击阅读原文 )
以前金庸小说的网站有很多,但大部分已经无法访问,但由于很多金庸迷的存在,新站也是源源不断出现。我近期通过百度找到的一个还可以访问的金庸小说网址是: aHR0cDovL2ppbnlvbmcxMjMuY29tLw==
不过我已经准备好已经采集完成的数据,大家可以直接下载数据,跳过本章的内容。
数据源下载地址:https://gitcode.net/as604049322/blog_data
下面首先获取这15部作品的名称、创作年份和对应的链接。从开发者工具可以看到每行的a标签很多,我们需要的节点的特征在于后续临近节点紧接着一个创作日期的字符串:
那么我们就可以通过遍历所有的a标签并判断其后续一个临近节点的内容是否符合日期格式,最终完整下载代码为:
可以按照创作日期排序查看:
名称创作时间网址 书剑恩仇录1955年/shujianenchoulu/ 碧血剑1956年/bixuejian/ 射雕英雄传1957—1959年/shediaoyingxiongzhuan/ 神雕侠侣1959—1961年/shendiaoxialv/ 雪山飞狐1959年/xueshanfeihu/ 飞狐外传1960—1961年/feihuwaizhuan/ 白马啸西风1961年/baimaxiaoxifeng/ 倚天屠龙记1961年/yitiantulongji/ 鸳鸯刀1961年/yuanyangdao/ 天龙八部1963—1966年/tianlongbabu/ 连城诀1963年/lianchengjue/ 侠客行1965年/xiakexing/ 笑傲江湖1967年/xiaoaojianghu/ 鹿鼎记1969—1972年/ludingji/ 越女剑1970年/yuenvjian/
下面看看章节页节点的分布情况,以《雪山飞狐》为例:
同时可以看到部分小说的节点出现了倒序的情况,我们需要在识别出倒序时将其正序,完整代码:
测试一下:
可以看到章节已经顺利的正序排列。
小说每一章的详细页最后一行的数据我们不需要:
下载每章内容的代码:
然后我们就可以批量下载全部小说了:
为了更好分析金庸小说,我们还需要采集金庸小说的人物、武功和门派,个人并没有找到还可以访问相关数据的网站,于是自行收集整理了相关数据:
相关数据都以如下格式存储,例如金庸小说的人物:
武功:
数据源下载地址:https://gitcode.net/as604049322/blog_data
定义一个加载小说的方法:
首先我们加载人物数据:
可以预览一下天龙八部中的人物:
下面我们寻找一下每部小说的主角,统计每个人物的出场次数,显然次数越多主角光环越强,下面我们看看每部小说,出现次数最多的前十个人物:
上述结果用文本展示了每部小说的前5个主角,但是不够直观,下面我用pyecharts的树图展示一下:
显然,《神雕侠侣》中的杨过和小龙女,《天龙八部》中的萧(乔)峰,段誉,虚竹,《射雕英雄传》的郭靖和黄蓉,《倚天屠龙记》的张无忌和赵敏 都是主角光环最强的角色。
使用上述相同的方法,分析各种武功的出现频次,首先加载武功数据:
定义计数方法:
每部小说频次前5的武功可视化:
门派分析
加载数据并获取每部小说前10的门派:
可视化:
还可以测试一下树形图:
综合统计
下面我们编写一个函数,输入一部小说名,可以输出其最高频的主角、武功和门派:
例如查看天龙八部:
词云图分析
可以先添加所有的人物、武功和门派作为自定义词汇:
这里我们仅提取词长度不小于4的成语、俗语和短语进行分析,以天龙八部这部小说为例:
修改上述代码,查看《射雕英雄传》:
神雕侠侣:
主角相关剧情词云
我们知道《神雕侠侣》这部小说最重要的主角是杨过和小龙女,我们可能会对于杨过和小龙女之间所发生的故事很感兴趣。如果通过程序快速了解呢?
我们考虑把《神雕侠侣》这部小说每一段中出现杨过及小龙女的段落进行jieba分词并制作词云。
同样我们只看4个字以上的词:
这里的每一个词都能联想到发生在杨过和小龙女背后的一个故事。
同样的思路看看郭靖和黄蓉:
最后我们看看天龙八部的三兄弟相关的词云:
关系图分析
金庸小说15部小说中预计出现了1400个以上的角色,下面我们将遍历小说的每一段,在一段中出现的任意两个角色,都计数1。最终我们取出现频次最高的前200个关系对进行可视化。
完整代码如下:
这次我们生成了html文件是为了更方便的查看结果,前200个人物的关系情况如下:
门派关系分析
按照相同的方法分析所有小说的门派关系:
Word2Vec分析
Word2Vec 是一款将词表征为实数值向量的高效工具,接下来,我们将使用它来处理这些小说。
gensim 包提供了一个 Python 版的实现。
之前我有使用 gensim 包进行了相似文本的匹配,有兴趣可查阅:《批量模糊匹配的三种方法》
首先我要将所有小说的段落分词后添加到组织到一起(前面的程序可以重启):
接下面我们使用Word2Vec训练模型:
我这边模型训练耗时15秒,若训练耗时较长可以把训练好的模型存到本地:
以后可以直接从本地磁盘读取模型:
有了模型,我们可以进行一些简单而有趣的测试。
首先看与乔(萧)峰相似的角色:
再看看与阿朱相似的角色:
除了角色,我们还可以看看门派:
还可以看看与降龙十八掌相似的武功秘籍:
在 Word2Vec 的模型里,有过“中国-北京=法国-巴黎”的例子,我们看看"段誉"和"段公子"类似于乔峰和什么的关系呢?
类似的还有:
查看韦小宝相关的关系:
门派武功之间的关系:
之前我们使用 Word2Vec 将每个词映射到了一个向量空间,因此,我们可以利用这个向量表示的空间,对这些词进行聚类分析。
首先取出所有角色对应的向量空间:
聚类算法有很多,这里我们使用基本的Kmeans算法进行聚类,如果只分成3类,那么很明显地可以将众人分成主角,配角,跑龙套的三类:
我们可以根据每个类别的角色数量的相对大小,判断该类别的角色是属于主角,配角还是跑龙套。
下面我们过滤掉众龙套角色之后,重新聚合成四类:
每次运行结果都不一样,大家可以调整类别数量继续测试。从结果可以看到,反派更倾向于被聚合到一起,非正常姓名的人物更倾向于被聚合在一起,主角更倾向于被聚合在一起。
现在我们采用层级聚类的方式,查看人物间的层次关系,这里同样龙套角色不再参与聚类。
层级聚类调用 scipy.cluster.hierarchy 中层级聚类的包,在此之前先解决matplotlib中文乱码问题:
接下来调用代码为:
然后我们可以得到金庸小说宇宙的人物层次关系地图,结果较长仅展示一部分结果:
当然所有小说混合产生的平行宇宙中,人物关系变得有些混乱,读者有兴趣可以拿单本小说作层次分析,就可以得到较为准确的人物层次关系。
对各种武功作与人物层次聚类相同的操作:
结果较长,仅展示部分结果:
可以看到,比较少的黄色部分明显是主角比较厉害的武功,而绿色比较多的部分基本都是配角的武功。
最后我们对门派进行层次聚类:
比较少的这一类,基本都是在某几部小说中出现的主要门派,而大多数门派都是打酱油的。
本文从金庸小说数据的采集,到普通的频次分析、剧情分析、关系分析,再到使用词向量空间分析相似关系,最后使用scipy进行所有小说的各种层次聚类。
Linux九阴真经之九阴白骨爪残卷2(SSH)
SSH
ssh:安全的远程登录
两种方式的用户登录认证
基于passwork
基于key
客户端
常见的客户端工具有:Windows版的putty、securecrt、xshell;linux中有ssh、sftp、scp、slogin等
配置文件: /etc/ssh/ssh_config
ssh命令
用法:ssh [email protected] CMD
选项:
-p port : 远程服务器监听端口
-b : 指定连接的源IP
-v : 调试模式
-C : 压缩方式
-X : 支持x11转发
-Y :支持信任x11转发
-t :强制伪tty分配 例: ssh -t remoteserver1 ssh remoteserver2
ssh 客户端
当客户端第一次连接服务器时,服务器会发送自己的公钥给客户端,并保存在客户端的~./ssh/know_hosts中。下次连接时不会再询问。
SSH服务登录验证
基于密码登录验证
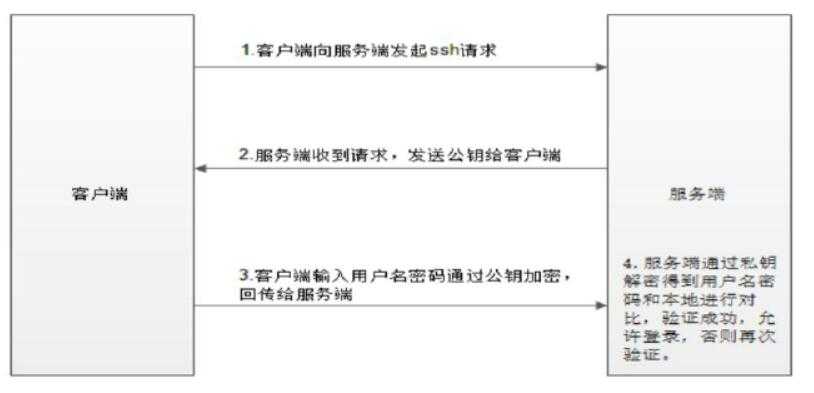
由上图我们总结出如下步骤
(1)客户单向服务器发起SSH请求,服务器会把自己的公钥发送给客户端
(2)用户根据服务器发送的公钥,对密码进行加密
(3)加密后的信息回传给服务器,服务器用自己的私钥解密,如果密码正确,则用户登录成功
基于秘钥的登录方式验证
(1)首先在客户端生成一对密钥(ssh-keygen)
(2)并将客户端的公钥拷贝(ssh-copy-id) 到服务器
(3)当客户端再一次发送连接请求,包括IP,用户名
(4)服务器得到客户端的请求后,会到authorized——keys中查找,如果有响应的IP和用户, 就会随机生成一个字符串,利如:acdf
(5)服务器将使用客户端拷贝过来的公钥对字符串进行加密,然后发送给客户端
(6)得到服务器发来的消息后,客户端会使用私钥进行解密,然后将解密后的字符串发送给服务端
(7)服务器接受到客户端发来的字符串后,跟之前的字符串进行对比,如果一致就允许免密码登录

基于key认证
基于密钥的认证:
(1)在客户端生成密钥对
ssh-keygen -t rsa(指定加密方式) -p‘‘(指定空密码) -f "~/.ssh/id_rsa"
(2)把公钥文件传输至远程服务器对应用户的家目录
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
(3)测试
(4)在SecureCRT或Xshell实现基于key验证
在SecureCRT工具—>创建公钥—>生成Identity.pub文件
转化为openssh兼容格式(适合SecureCRT,Xshell不需要转化格式),并复制到需登录主机上相应文件authorized_keys中,注意权限必须为600,在需登录的ssh主机上执行:
ssh-keygen -i -f Identity.pub >> .ssh/authorized_keys
(5)重设私钥口令:
ssh-keygen –p (为私钥加密)
(6)验证代理(authentication agent)保密解密后的密钥
这样口令就只需要输入一次
在GNOME中,代理被自动提供给root用户
否则运行ssh-agent bash
(7)钥匙通过命令添加给代理
ssh-add
例:配置基于密钥的免密登录
1、在客户端A生成密钥对,按3次回车键
[[email protected] ~/.ssh]#ssh-keygen
2、把公钥传给客户端B对应的家目录,并重命名为 authorized_keys

3、在客户端Bde ~/.ssh 的目录下检查是否有authorized_keys 文件
![]()
4、在客户端A测试连接客户端B,发现无需输入密码,直接登录
![]()
以上是关于Python爬虫之九阴真经的主要内容,如果未能解决你的问题,请参考以下文章