r语言如何求矩阵中某一列的总和
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了r语言如何求矩阵中某一列的总和相关的知识,希望对你有一定的参考价值。
设矩阵为A
方法一:colSums(A)
方法二:apply(A,2,sum)
> x<-matrix(c(1,1,2,1,2,3,4,1),4,2)
> x
[,1] [,2]
[1,] 1 2
[2,] 1 3
[3,] 2 4
[4,] 1 1
> length(which((x[,1]==1)))
[1] 3
> length(which((x[,2]==1)))
[1] 1
#x[,1]==1判断是否为1,返回True或False
# which((x[,1]==1))返回为True的行号
#length(which((x[,1]==1)))返回为True的行数,即1的个数
简正模式
矩阵在物理学中的另一类泛应用是描述线性耦合调和系统。这类系统的运动方程可以用矩阵的形式来表示,即用一个质量矩阵乘以一个广义速度来给出运动项,用力矩阵乘以位移向量来刻画相互作用。求系统的解的最优方法是将矩阵的特征向量求出(通过对角化等方式),称为系统的简正模式。
以上内容参考:百度百科-矩阵
参考技术A第一步,声明矩阵t,利用矩阵函数matrix,nrow为5,ncol为5,并打印矩阵t,如下图所示:

第二步,获取矩阵t第四列数据,可以直接使用t[,4],这样可以获取到第四列数据,如下图所示:

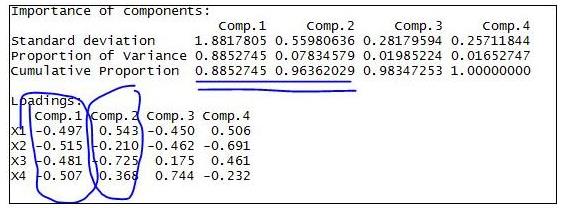
第三步,如果想要获取第五列数据,可以使用t[5,],如下图所示:
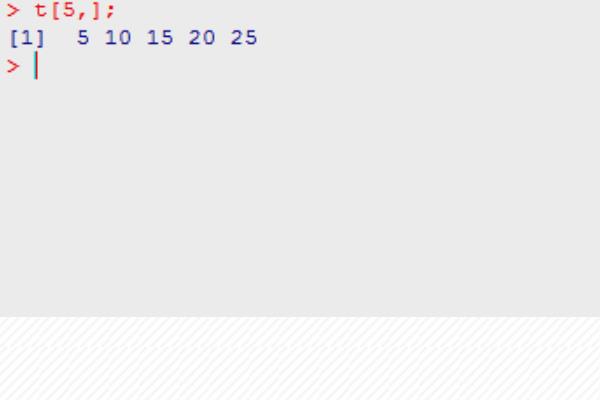
第四步,如果想要获取第三行和第四列交叉点的数据,使用t[3,4],如下图所示:
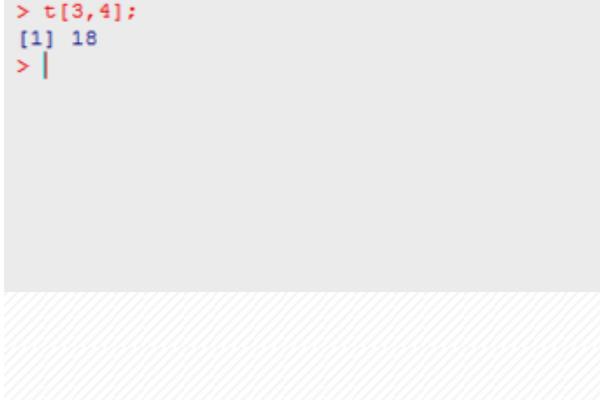
第五步,获取某一行的一列或两列以上的数据,使用t[1,c(3,5)],表示获取第一行和第三行、第五个交叉点的数据,如下图所示:
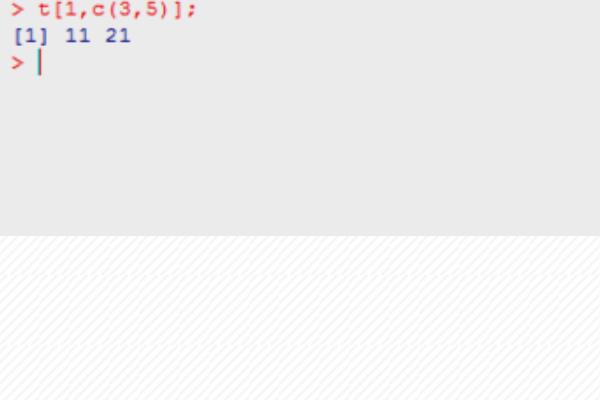
第六步,如果想要获取第二行、第三行和第二列的数据,利用t[c(2,3),2],如下图所示:

方法一、
colSums(A)
方法二、
apply(A,2,sum) 参考技术C sum(a〔:,i〕)
Pandas:如何修改DataFrame中某一列的值?
写这篇博客主要是因为在修改DataFrame列值的时候经常遇到bug,但到目前还没把这种错误复现出来。
DataFrame是Pandas中的主要数据结构之一,本篇博客主要介绍如何DataFrame中某一列的值进行修改。
1 常规方法
这部分主要介绍修改DataFrame列值的常规方法。为了方便后续说明先构建如下数据:
import pandas as pd
import numpy as np
df=pd.DataFrame([['A',1],['B',2],['C',5],['D',4],['E',10],['F',13],['G',8]],
columns=['col_1','col_2'],
index=list('abcdefg'))
df结果如下:

- 使用常量修改DataFrame列的值
使用一个常量对DataFrame列中的数据进行修改时,代码举例如下:
df1=df.copy()
df1['col_1']='H'
df1.loc[['a','c','d'],'col_2']=100 #将指定索引的列值进行修改
df1.iloc[4:,-1]=200
df1的结果如下:

- 使用List\\array修改DataFrame列的值
当需要对DataFrame列中的多个值进行修改时,可以使用List或array等变量型数据来对其进行修改。具体代码如下:
df2=df.copy()
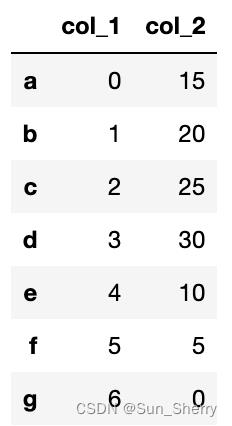
df2['col_1']=list(range(7))
df2.loc[df2.index<='d','col_2']=np.array([15,20,25,30])
df2.iloc[4:,-1]=np.array([10,5,0])
df2的结果如下:
- 使用Series/DataFrame修改DataFrame列的值
除了以上两种数据类型之外,还可以使用Series型数据来修改DataFrame列的值。但使用这种方法时,需要索引对齐,否则会出错。具体举例如下:
df3=df.copy()
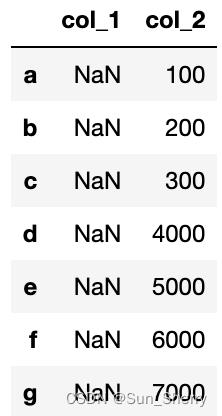
df3['col_1']=pd.Series([1,2,3,4,5,6,7]) #索引不对齐时不会报错,但没有成功修改列值。
df3.loc[['a','b','c'],'col_2']=pd.Series([100,200,300],index=list('abc'))
df3.iloc[3:,-1]=pd.DataFrame([[4000],[5000],[6000],[7000]],index=list('cdef'))
其结果如下:
2. replace方法
DataFrame对象自带的方法replace()也可以实现列值的修改。该方法中的参数主要有以下几个:
| 参数 | 作用 |
|---|---|
| to_replace | 确定需要修改列值的数据。可接受的数据类型有:str, regex, list, dict, Series, int, float, or None |
| value | 指定修改后的值。可接受的数据类型有:scalar, dict, list, str, regex, default None |
| inplace | 是否本地置换 |
| limit | 指定前后填充的最大次数 |
| regex | 正则表达式符号。如果需要在to_replace中使用字符串形式的正则表达式对数据进行筛选的话,需要将其设置为True。 |
| method | 填充方式。‘pad’, ‘ffill’, ‘bfill’, None |
创建如下数据,具体如下:
df=pd.DataFrame([['A','A'],['B','B'],['C',5],['D',4]],
columns=['col_1','col_2'],
index=list('abcd'))
df的结果如下:

- 对整个DataFrame中的指定数据进行替换
#A替换为aaa,B替换为bbb,4替换为100
df_1=df.replace(to_replace=['A','B',4],value=['aaa','bbb',100])
#将A替换为AAAA
df_2=df.replace(to_replace='A',value='AAAA')
#将A替换为AAAAA,5替换为2000
df_3=df.replace(to_replace="A":'AAAAA',5:2000)
其结果如下:

- 对DataFrame中的不同列指定不同的替换方式
#对于col_1列:将A替换为1,B替换为2
#对于col_2列:将A替换为100,B替换为200
df_4=df.replace("col_1":'A':1,'B':2,"col_2":"A":100,"B":200)
其结果如下:

- 使用正则表达式筛选数据
#将A\\B替换成new
df_5=df.replace(to_replace=r'[AB]',value='new',regex=True)
其结果如下:

以上是关于r语言如何求矩阵中某一列的总和的主要内容,如果未能解决你的问题,请参考以下文章