2022电工杯数学建模-思路&程序文档-在线看在线写
Posted 小叶的趣味数模
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022电工杯数学建模-思路&程序文档-在线看在线写相关的知识,希望对你有一定的参考价值。
关注我的CSDN,每个比赛都会发布链接提示,助力各位拿奖
【金山文档】 2022电工杯思路&程序&数据-实时更新文档 https://kdocs.cn/l/chUyVh0R44JB
https://kdocs.cn/l/chUyVh0R44JB
下面是去年电工杯思路
A题
问题1:电能质量评估
1)
a.
各工况abc电压

各工况abc电流
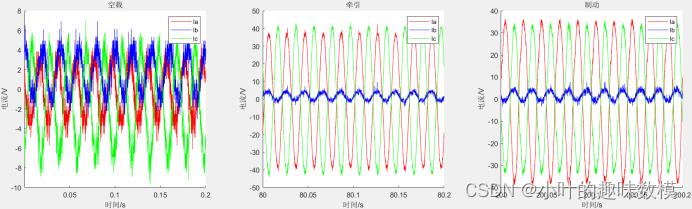
以上数据均为正弦波,符合y=Asin(wx+b)经验公式,其中w可以直接通过每条波的周期确定,就看与x轴交点的间距可确定出T,其他参数可以通过lsqcurvefit函数拟合出关系式
正序:A相领先B相120度,B相领先C相120度,C相领先A相120度。
负序:A相落后B相120度,B相落后C相120度,C相落后A相120度。
零序:ABC三相相位相同,哪一相也不领先,也不落后。
求零序分量:把三个向量相加求和。即A相不动,B相的原点平移到A相的顶端,注意B相只是平移,不能转动。同方法把C相的平移到B相的顶端。此时作A相原点到C相顶端的向量,这个向量就是三相向量之和。最后取此向量幅值的三分一,这就是零序分量的幅值,方向与此向量是一样的。
求正序分量:对原来三相向量图先作下面的处理:A相的不动,B相逆时针转120度,C相顺时针转120度,因此得到新的向量图。按上述方法把此向量图三相相加及取三分一,这就得到正序的A相,用A相向量的幅值按相差120度的方法分别画出B、C两相。这就得出了正序分量。
求负序分量:注意原向量图的处理方法与求正序时不一样。A相的不动,B相顺时针转120度,C相逆时针转120度,因此得到新的向量图。下面的方法就与正序时一样了。
有关系式后可以就上述各分量解释,更新相应公式,相加得到新的分量,并绘制曲线图。,这里注意是计算每个电压电流的三个分量
分析本段内电压和电流不平衡程度的差异,电压还算比较稳定,主要是空载、牵引、制动三个时段时的电流波动比较大,可以通过Lyapunov指数确定三个状态下不同相电流的不平衡度并进行比较,分析说明哪一个状态下对电流影响比较大。除了Lyapunov指数也可以通过常规的平滑算法得到平滑曲线然后取误差作为不平衡度的体现,或者是通过附录2中不平衡度的公式来做均可行。
Lyapunov指数法介绍:

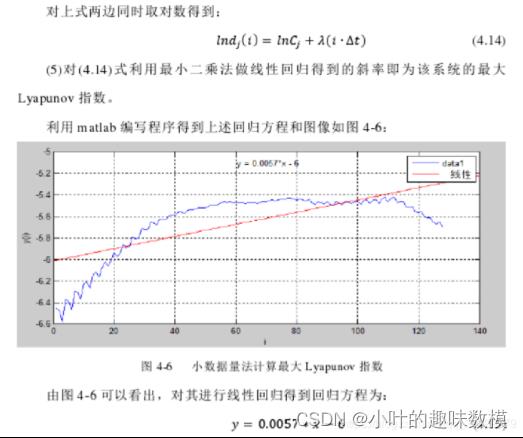
用其他可以计算数据紊乱程度的方法都行
b.
绘制电流的频谱图,通过fft变化,并通过fftshift修正,案例程序
load('Data.mat')
Fs=50;%频率根据上一问中不同波形填入,这里仅给个案例,这个频率是波的频率不是采样频率
H=4000;%采样个数
x=1:4000;%取数
y=Ia(x);%取数
y0=abs(fft(y,H));%快速傅里叶变换的幅值
y1=fftshift(y0);%幅值修正得到真实幅值
f=x*Fs/H;%将横坐标转化,显示为频率f= n*(fs/N)
figure
subplot(121)
plot(x,y)
subplot(122)%直接FFT结果
plot(f(1:H/2),y0(1:H/2))
xlabel('Frequency');
ylabel('Amplitude');
Z=[f(1:H/2)',y0(1:H/2)];%储存频率及谐波
%以幅值为主进行排序
[~,a]=sort(y0(1:H/2),'descend');%降序
Z=Z(a,:);
Z=[a,Z];Ia、Ib、Ic电流,三个工况下共9个电流,基波就是这9个电流的波形,分别通过fft变化求最大的5个谐波分量幅值及频率,上述程序结果为Z矩阵中的前五个,第一列为第几次波,第二列为对应频率,第三列为幅值,以幅值为优先条件排序取前五个。本问的目的是选出主要的五个谐波的频率和幅值。一幅图了解基波与谐波。
c.
第二问中找到了9个电流的5个主要谐波,有振幅和频率,基波就是这9个电流的波形,选择基波上某个与0的交点带入经验公式可以得到5个谐波的波形公式,同样的求得各工况各电压的5各主要谐波波形公式,附录2中h次就是上方Z矩阵中第一列的数值。本问只带入主要谐波进行质量计算即可,不同工况下的电压和电流结果,可以看作为一个正交实验,附录2主要计算畸变率和不平衡度两个指标,计算结果作为正交实验结果,不同工况作为影响因素,可通过方差分析探讨运行工况对电压、电流的影响程度。谐波畸变如下图所示

接下来探讨Ia、Ib、Ic三个电流的谐波不同工况下,前5的谐波次级、振幅、频率的变化,同样是方差分析法分析影响是否显著,还可以得出对哪个次级的影响最大最小,还有其他可分析的都可以再加上。
2)注意是全数据做分析
a.
这个问要我们绘制电流正序、负序、零序分量的幅值,本问的基波为电流正序、负序、零序分量波形,频幅图为右图,分别带入电流正序、负序、零序分量的曲线进程序求得对应的频幅图,右图怎么看,横坐标每个数据依次为第几次波的频率,纵坐标对应的是幅值,题目要求计算3次谐波的含有率,那么就记录下Z矩阵中的第三个波的频率和幅值,通过上文的方法得出谐波波形公式
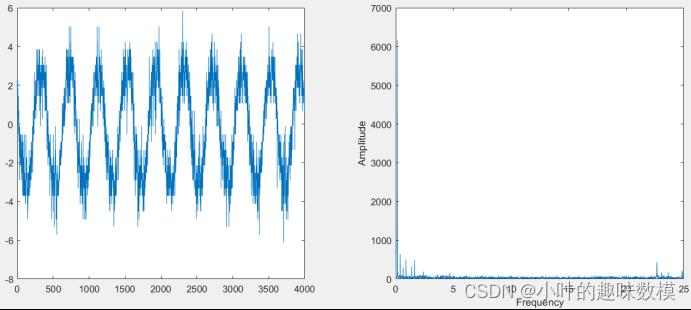
本问的程序就不需要进行排序了
load('Data.mat')
Fs=50;%频率根据上一问中不同波形填入,这里仅给个案例,这个频率是波的频率不是采样频率
H=4000;%采样个数
x=1:4000;%取数
y=Ia(x);%取数
y0=abs(fft(y,H));%快速傅里叶变换的幅值
y1=fftshift(y0);%幅值修正得到真实幅值
f=x*Fs/H;%将横坐标转化,显示为频率f= n*(fs/N)
figure
subplot(121)
plot(x,y)
subplot(122)%直接FFT结果
plot(f(1:H/2),y0(1:H/2))
xlabel('Frequency');
ylabel('Amplitude');
Z=[f(1:H/2)',y0(1:H/2)];%储存频率及谐波谐波含有率为第h次谐波分量的均方根值与基波分量的均方根值之比,用百分数表示。

方均根值公式:1/N)×√(∑Xn^2)
时间段可以自取,0.2s就有4000个数据,分别取各时间段内的谐波和基波波形数据,计算出每段时间下的方均根值,最后绘制成曲线,与此同时还要通过1)a问模型计算相应时间段下的不平衡度。最后给出平衡度最大的几个时段及对应3次谐波的含有率。
b.
计算列车瞬时功率需要得到U和I数据,分别通过Ua、Ub、Uc和Ia、Ib、Ic波形相加即得到不同时刻的U和I数据,相乘就得到瞬时功率,绘制成虚线。
牵引时段和制动时段肯定不止1)a中提到的时段,这需要绘制出功率曲线后观察,确定牵引和制动有哪些时段,从中找出牵引时段和制动时段功率最大的时刻,接下来分别划分牵引、制动时段为若干个单位时段,分别整理出对应时段的Ua、Ub、Uc、Ia、Ib、Ic不平衡度以及Ua、Ub、Uc、Ia、Ib、Ic平均值。做相关性分析。
问题2:节能降耗方案
a.
功耗就是上一问中的瞬时功率*单位时间(0.2s/4000),回馈电量就是在制动阶段将动能转化为电能,回馈的电能计算,题目讲到电力机车运行的 27.5kV ,电流大小不会变,那么就可以求得制动理想情况下可以回馈的电能,但是这里还需要注意三项电压波形之和得到的电压值并不等于供电系统高压侧(220kV),中间有电阻损耗,这里的电压差结合电流值,可以得到不同时刻电阻的损耗能,最后减去损耗能即为最后回馈到电力系统的电能。
b

本问的目的是设计一个车载储能系统,以减少来回能量传输的消耗
附录2有相应的电价,和设备的各项成本,乘以从车载系统中使用的电能就是收入,收益就是收入-设备成本,其实设计含储能系统的功率电量配置及电力电子接入,就假设设计的系统的能承受动车的U动车,具体各装置参数需要网上查符合U动车规格的装置,主要是确定能量储存损耗相关的参数,并且电容量尽可能要大。b问为将转化的能量储存于车载系统中,储存电能=回馈电能-转化损耗,制动阶段充能结束后,在牵引阶段,制定输出电流大小,假设动车组上传输电流无损耗,使用的电能=储存电能,车载储能的功耗会随储电量的降低而减少,直到电容为0。本问需要做优化设计的是传输的电流大小。
c.
本问则是考虑将回馈的电能直接传输到外部的牵引变压器中,此时车载储能系统不考虑储能的能量损耗,但需要考虑转化损耗和a中的电阻损耗,本问不需要做优化设计,c问的收益=(回馈电能-传输损耗)*电价-设备成本。
最后比较bc的收益,技术、安全可靠、储能容量利用率无相关数据可进行计算,就不用管,或者用文字说明下。
c就不需要电容装置,设备成本要低于b
问题3:动态牵引负荷精确预测
a.
下图为P_TPSN数据,0线以上为牵引作功,0线以下为减速制动,一天运行动车组29躺,P_TPSN数据中不存在同时给两趟动车组供电,如果是按登顿间隔分割下图数据,可以分割出30多组,但是我们仔细看有些间隔小有些间隔大,制动在中途站台停靠也会有制动阶段,但靠站时间和发车间隔明显后者要更长一点,因此可以直接通过设置间隔临界值对下图数据进行划分

划分示意图:

调整间隔临界值,直到能够划分出29组为止
b.
首先统计29组数据中以下指标(供电最高幅值;制动最低幅值;动车运营时长也就是每组曲线长度,间隔时间为1s,可以直接算的每趟动车时长;几次停战,一般都制动一次,这里就看划分的29组中,有制动线段多少个),有了这些指标就可以进行相关性分析,求29组之间的相关性,接下来相关性的倒数作为距离矩阵,附表2中按运行方向和车型划分有6中类别,然后可以参考选址问题,设计启发式算法,目标函数为各点到各自的中心点距离总和最小。中心点个数为6个,划分六类,附表2中编号并不是和P_TPSN数据中划分的29组依次对应,肯定顺序是不一样的,不然题目也不会让进行辨识,最后得到的分类结果中就看每类中有多少个动车组,可能会有差别,差几个都可以接受。
c.
牵引阶段就是大于0的部分,每个动车组的运行时间其实是不一样的,如果要进行拟合,也只能做每个动车组牵引阶段负荷的曲线拟合,然后题目想要的是6类的曲线模型,那就随便挑一个曲线出来做就行,直接通过多项式拟合,作为该类动车组的牵引负荷曲线。
d.
正常列车都是8编组、如果是16编组,负荷×2就行,根据c的结果匹配相应的负荷曲线,最后总的结果图应该类似于P_TPSN数据但没有制动部分。
问题4:高铁牵引变电所-牵引负荷等值建模
本问主要区别是增设多条传输线,相比一条外网输电线,虽然最终到达动车的电流都是一样得,我们直到电阻损耗公式为I²R,多条输电线可以平摊电流,这样总的损耗就会降低。损耗少了,能提供给动车的电能就更多,这样电流的波动就不会太大,安全性也能得到改善,本问的损耗也可以算出来,原本是I²R,现在是三个I²R/9,减少了2/3的损耗。
电能较多的情况,实测电压电流的曲线更为平滑,上文思路中已经提到了实测数据的公式拟合,其实如果按理论情况下,无损耗下的U和I应该为光滑曲线,本问需要用到前面问题一1)a得到的U和I公式减去实测数据,计算绝对误差,取个平均值,在本问的绝对误差就取其1/3倍,然后本问的U和I就是公式+randn*1/3绝对误差,最后在于Data实测数据进行对比。
就是说本问通过比较法去说明图2的该进是可行的。
B题
第一问题目提示很明显了,移动平均线,还有股票市场中有板块指数(将同一板块的个 股按不同的权重方式生成相关指数),它是对该板块走势的整体反映。移动平均就是取前5日、10日、20日数据的平均值作为下一时间节点的值,这本身就是一种预测算法,附件1中有37个小表,每个小表中可能大家还会关心交易时间,要取什么时段的数据直接匹配相应字符串即可,注意每个人电脑打开文件日期格式可能不太一样,因此在字符串匹配的时候需要注意下;然后需要注意的是,股票开盘是周一到周五,所以不存在周六周天缺失数据,也会存在部分股票在周一至周五停盘的现象,停盘不是数据缺失,别瞎搞;各股票入市时间也不一样,在识别字符串的时候一定要看有没有对应的字符,如果觉得日期格式麻烦,excel表中可以将日期格式转换为数值型。
我电脑打开日期格式是XXXX-XX-XX,有些小伙伴的是XXXX/XX/XX,以XXXX-XX-XX为例,通过find函数把后续需要用到的数据位置找到:
a=find(X(:,3)=='2019-03-04'); % 2019年4月1日前20个交易日
b=find(X(:,3)=='2021-04-30');
c=find(X(:,3)=='2019-04-01');
既然题目说到了K线,论文里怎么能没有K线图呢,其实绘不绘制K线图都不影响结题,K线是炒股软件中必备的参考,绘制出来显得图更专业点,这不就和其他参赛者拉开差距了吗。
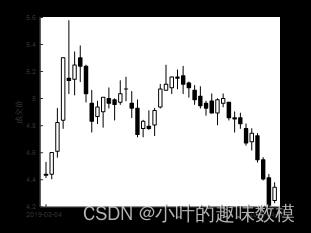
绘制代码样例,是绘制单支股票的,如果文章页输不够,可以绘制几个单个股票图凑凑数
X=[];
i=1;
[~,~,X]=xlsread('附件1.xlsx',['Sheet0 (',num2str(i),')']);%很多人这里报错,是因为文件中第一个小表命名和其他小表的不一样,自己改下就好了
X=string(X);
X=rmmissing(X);%删除<missing>行
X(2,8)=0;X(2,9)=0;
a=find(X(:,3)=='2019-03-04');%很多人这里也报错,自己去看看那支股票有没有这个时间的数据,如果是之后才入市的,就换成最新入市时间
b=find(X(:,3)=='2021-04-30');
c=find(X(:,3)=='2019-04-01');
Y=double(X(a:b,[4 5 6 7]));%开盘价、最高价、最低价、收盘价
figure
Kplot(Y(:,1),Y(:,2),Y(:,3),Y(:,4))%这里报错是因为ab未识别到字符串
ylabel('成交价')
title([X(2,2)+'--K线图'])
xlim([0,length(Y)+1])
XTick=[1;length(Y)-1];%
XTickLabel=['2019-03-04'
'2021-04-30'];
XTickLabel=string(XTickLabel);
set(gca,'XTick',XTick);
set(gca,'XTickLabel',XTickLabel);接着说第一问的板块指数,题目有说是将同一板块的个股按不同的权重方式生成相关指数,附件中的开盘、最高最低、收盘数据已经是指数了,这是股票指数,不需要你再去算什么,板块指数又是另一码事,是通过加权和之后乘以基点数算出来的,基点数股票都是100,外汇才是1000,不了解的可以去问问会炒股的。权重我们一般参考成交量或成交额的比例做归一化之和为1来定;如果想从算法角度出发,可以通过熵权法求得权重乘以原有数值,加权和之后乘以基点数得到光伏建筑一体化板块指数。板块指数使用收盘价来算,炒股我们业主要看重收盘价,除了收盘价,还是建议绘制出K线图,因此开盘价、最高价、最低价的板块指数可以采用同样的方式进行计算。通过四个特征指标的指数值,可以绘制出K线更直观的体现出趋势,如果觉得K线图没必要画,可以就绘制一条板块收盘价指数曲线就行。接下来题目要求做移动平均,数据准备按2019-04-01到2021-04-30取历史最近5个、10个、20个取数,每近5个、10个、20个数据取平均算下一个数,以此类推,最后hold on加一条曲线到K线图上,例如下图,移动平均又叫简单移动均线法(SMA),加个名称显得有格调一些。

第二问,SMA是一个参考,也是一个预测模型,作为参考线的时候主要是观察股价是否还有上涨的潜力,做预测时看效果误差肯定不行,误差分析比如说可以做下残差图、误差棒图等等,也可以通过计算F、t、R检验值反映误差很大。修正模型很简单,时间序列方法基本框架都很相似,换一种时间序列方法就行,推荐几个方法及效果,均在《量化投资__以MATLAB为工具_李洋-郑志勇》第四章中,第二问采用的新方法要与第一问移动平均做对比,突出第二问模型的优势。
①指数移动平均法(EMA),效果

②自适应移动平均法(AMA),下图中的数据预测的效果要比EMA要差点,可以从多对比几个算法选最好的用

确定好了新模型,然后预测5月28日后的20个交易日的收盘价数据,如果觉得有绘制K线图的必要,可以在将最高价、最低价、开盘价也预测出来,预测难免有误差,如果预测出的最高价低于了开盘价或者收盘价其中一个,就取开盘价和收盘价中最大的一个作为最高价。预测出了20个交易日的各指标数据,通过SMA算下周月的移动平均数,基于收盘价绘制出每日平均线(日平均线就是原数据)、周平均线(取历史近5个交易日取平均)、月平均线(可以取历史近22个工作日取平均),最好是绘制出K线做参考。移动平均很好理解,就是依次向后遍历取n个数据进行计算。
第三问数据连接

会模拟点击爬虫就用程序爬取数据,不会就手动统计
本文还是考虑的是37支股票的整体,还是基于第一问的结果数据,注意这里是以没两个月为一个时间段,该时间段的数据取平均或者是取时间段末数据都可以,数据大小和相关性没什么影响,如果数据变化趋势越相近,相关性就越大, 求相关性方法有常用的三大相关系数法(皮尔逊、Kendall、Spearman)可用corr函数实现,还有余弦相似度
余弦相似度代码:
D=(x‘*y)/(norm(x)*norm(y))
或
D = 1- pdist([x',y'], 'cosine')
第四问,首先是对37支股票的投资风险进行评估,评估最好是采用最近三个月数据实际中最有效,一种方法是从开盘和收盘价格角度去考虑,当日收益=收盘-开盘,可以通过Var风险价值公式进行计算,参考《金融数量分析:基于MATLAB编程》第二章;第二种是从数据波动角度去衡量,简单的可以先对数据做平滑处理然后去做误差,相互比较进行排序;还有个方法是股票Lyapunov指数法,该方法也是股票界比较认可的方法,Lyapunov指数值越大,股票风险越高,该方法主要描述股票的混沌离散状态。如果有其他能描述数据的混沌情况都可以。
算法步骤


指数值为最后回归方程的x系数
效果图

如图两个股票某指标的变化曲线,Lyapunov指数结果如下
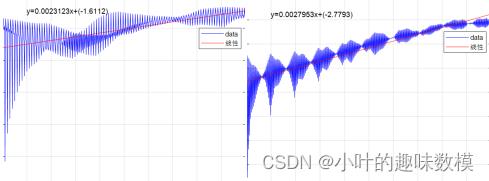
从结果来看后者风险要高于前者
股票为T+1模式,第一天买第二天开盘才可以卖,如果要做的理想化可以假设卖出价格为第二天的开盘价。胡总和假设当天收盘价买入或者是最低点买入,第二天最高点抛出,怎么来自己决定。
在实际炒股中,一般做投资不超过本金的15%,至多不超过20%,每从一支股票买入1股是100个点,不一定需要购买整数股,买0.01股也行,买入股的花费=股数*单价*100,100为基点数,就比如南玻A在2021-05-27最高价买入1股,单价为10.22,那么就需支付1022元。
一个月投资为短期投资,上一步已经确定好了股票排序,接下来在预测下六月份每个交易日的开盘价、收盘价、最高价、最低价,投资固有策略:拿本金的15%出来选择当前最好的5支潜力股,这里的潜力股,第一天就以排名来看,资金分配比例可以参考各股的日涨幅、收益率等比例进行划分,股票不可能一直盯着数据看,也不可能有跌就立即卖出,这里有一个平仓线概念,就是说设置一个涨幅线和跌幅线,涨了15%或跌了15%,直接卖掉,涨幅和跌幅线可以自行设置。当有卖出决策发生时,可以视为股票发生明显,需要重新排名分析,重新取近3个月数据计算Lyapunov指数重新排名。投资还有一个衡量股票存在潜力的指标是MACD,见《量化投资__以MATLAB为工具_李洋-郑志勇》第四章,该指标主要衡量的是买入和卖出的趋势,侧面可以反映出涨跌的增长率,当大量投资者买入股票时,股票价格会增长,同样的大量投资者卖出,那么股票价格会降低,MCAD与DEA(指数移动平均线)的交点被投资者们作为买入和卖出的切入点。
第四问思路是实际中的决策,就别用全局用优化算法寻优了。构建好规则后就按时间模拟就行,唯一需要做优化设计的就是涨跌两条平仓线,一般范围在10%-20%之间,决策触发点要么为达到平仓线,要么参考MCAD与DEA得交点,设置平仓线也是一项重要的决策,现实中也很难保证能在最高点抛出。当然也可以按理想状态来,但最终得给出结果并说明,金融行业检验职业操盘手的一项参考为总资产的变化曲线。总资产=手上剩余资金+买入股票的价值,一般总资产的变化曲线呈梯度向上形,如果最后出来的曲线分布类似,那么可以直接吹自己的模型很优秀了。
如果有懂炒股的小伙伴可以设置跟复杂的决策,每到一个决策点,如果是涨到平仓线可以选择继续加仓,而不是卖了之后再买入,这样可以赚到更多,如果跌至平仓线,如果股票存在潜力,可以选择性平掉50%仓位。甚至可以增设平仓线的调整决策,例如股票一直涨,达到一定程序后,重新规划平仓线。
为什么说建议绘制K线,下面有两篇文章介绍了K线几组合形态的看涨看跌信号,这也是众多炒股高手们参考的重要信号。如果还想模型跟复杂化,可以参考下。
https://zhuanlan.zhihu.com/p/58824781https://zhuanlan.zhihu.com/p/58824781
其实第四问参考的角度很多,思路举了几种参考方式,也可以参考三本电子书:
《精通MATLAB金融计算》
《金融数量分析:基于MATLAB编程》
《量化投资__以MATLAB为工具》
最后一问就是写建议,关于行业的发展,投资只是其中一部分,更多的还是政府的扶持。
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于2022电工杯数学建模-思路&程序文档-在线看在线写的主要内容,如果未能解决你的问题,请参考以下文章