无监督预训练在Re-ID任务上的应用
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无监督预训练在Re-ID任务上的应用相关的知识,希望对你有一定的参考价值。
转载自
Unsupervised Pre-training for Person Re-identification
Unleashing the Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
最近无监督预训练在CV领域取得了较好的效果,主要用来学习好的特征以用于特定的下游任务,比如MoCo, SimCLR, BYOL等,但由于这些模型都是在ImageNet上预训练的,而行人图片和ImageNet数据集有较大的的域差异。因此,最近有好几篇文章针对Re-ID任务提出了对应的无监督预训练方法和数据集。下面主要介绍三篇在Re-ID任务上进行无监督预训练的文章。
- Unsupervised Pre-training for Person Re-identification
- Unleashing the Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification
- Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Unsupervised Pre-training for Person Re-identification

Publication: CVPR_2021
key words: unsupervised pre-training person ReID, Large scale unlabeled person Re-ID dataset
abstract: 在该文章中,作者提出了一个大型的无标签行人重拾别数据集“LUPerson"。 并且首次使用无监督预训练去提高学到的行人表征的泛化能力。之前的预训练通常是在ImageNet上预训练好参数,但是由于ImageNet图片和person图片有着比较大的domain gap, 因此,使用它们收集的”LUPerson“数据集来尝试无监督预训练。LUPerson是一个无标签的数据集,包括了200K个ID的4百万张图片,比现有最大的ReID数据集还大30背。同时,它也包括了各种各样的环境(不同的摄像头,场景)。基于该数据集,作者主要探究了数据增强和对比学习两个方面探究了如何学到一个更鲁棒的ReID特征。实验表明,在”LUPerson“预训练的数据集在各个场景下都有明显的提升。
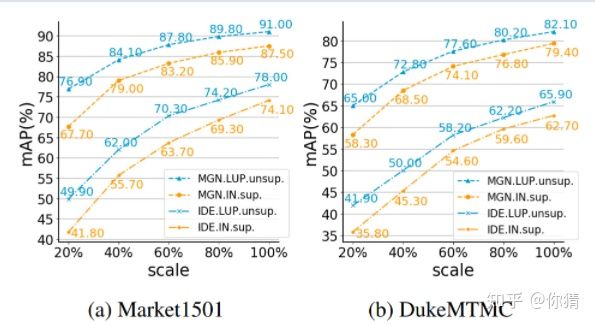
经过预训练后的性能
solution:
- 数据集的收集:LUPerson包含200K个ID的4百万张图片。作者从7万个街景YouTube街景视频中收集,这些街景视频是由”城市+街道名“搜索而来。为了提高数据集的多样性,作者选择了全世界100个大城市的街景图片。然后使用YOLO-v5检测得到行人图片,并使用HRNet去检测行人关节点,排除遮挡过于严重的图片。因此,这个数据集包含了大量不同环境,不同设备和光照以pose的行人图片
- Re-ID 无监督预训练:如下图所示,作者主要采用了MoCo的方式进行无监督预训练。这在个框架中,作者主要探究了数据增强和对比损失这两个特性在无监督预训练中的作用。对于数据增强,做i这发现不同的数据增强:随机灰度,高斯模糊,颜色抖动和随机擦除对Re-ID任务都有着不同的效果。最后得到随机擦除对Re-ID无监督预训练起着重要的效果,而颜色抖动则会损害性能。对于对比学习,作者则探究了不同的环境温度变量对Re-ID任务的影响。最后得出t在0.07的时候效果最好。
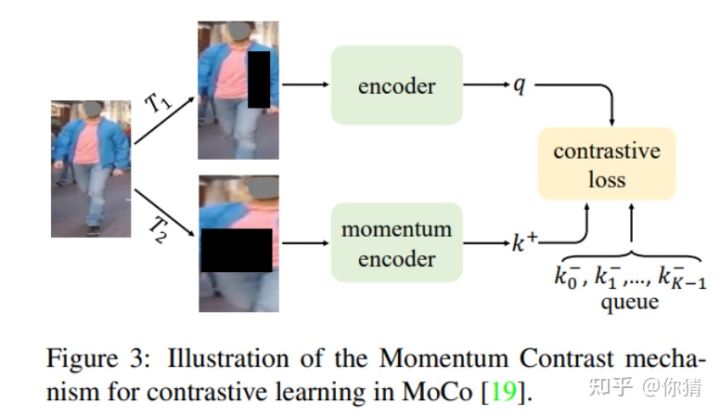
experiment:
组后实验表明,使用在LUP数据集上无监督预训练的模型能够在各个任务上大大提升模型的性能。



Unleashing the Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification

这篇文章则是在上面一篇的基础上,继续探究无监督预训练在Re-ID任务上的作用。并根据Re-ID任务的特殊性,提出了几点改进
Publication: arxiv_2021
abstract: 现有的行人重识别模型通常直接加载在ImageNet上预训练好的权重来及性能初始化。然而,作为一个细粒度分类任务,与ImageNet的分类任务他有着不同的挑战和domain gap。收到最近自监督表征学习的启发,在本文找那个,我们提出了一个专门针对行人重识别任务的无监督预训练框架,UP-ReID. 在预训练期间,我们试图解决学习细粒度 ReID 特征的两个关键问题:(1)无监督预训练中的增强可能会扭曲人物图像中的判别线索。 (2) 没有充分挖掘人物图像的细粒度局部特征。 因此,我们在 UP-ReID 中引入了内部身份 (I2 -) 正则化,它被实例化为来自全局图像方面和局部方面的两个约束:使用全局一致性来加强增强和原始人物图像之间的鲁棒性,而每个图像的局部patch快之间的内在对比约束被用来充分探索局部判别线索。
motivation : a图中两张在对行人图片增强之后,可能与不是同一个id的图片更加相近。此外对人ReID任务,局部的细节,分块显得至关重要。因此,文章针对这两点不足提出了对应的全局一致性和局部对比学习的方法来改进无监督对比学习在Re-ID上的应用。

针对特定的ReID任务,作者引入了一个inter-identity正则项(I^2 正则项),分别从全局图片和局部图片上对ReID进行约束。此外,在I^2 正则化中,一个基于局部快的难样本挖掘策略被引入来探索局部线索。
methods:

overview:整体的网络结构如上图所示。还是依然采用MoCo的框架,其中的k0和q0分别表示全局特征,在上面使用的对比损失和MoCo一致。此外,使用没用数据增强得到的全局特征qr和kr进行一致性约束。此外,对图片进行分块,对分块的图片特征也进行对比损失。最后总损失为:- Consistency over Augmented-Original Images:这个损失是一致性损失,主要是让进行数据增强的前后图片id的一致性。对于一个batch中的图片,q为数据增强的图片,qr是未做过增强的图片,k为ema模型中做过数据增强的图片特征,kr为未做过数据增强的特征。分别对做过数据增强的特征计算相似度和未做过数据增强的特征计算相似度,得到两个相似度矩阵: 在使用MMD距离对其进行约束. 得到一致性损失
- Intrinsic Contrastive Constraint: 对于对比损失, 则是由全局特征对比损失和局部特征对比损失构成.局部特征对比损失是由一个个patch快的特征构成的,两个损失分别为: .最后的对比损失可以表示为:
- Hard Mining for Local Feature Exploration:这个是对patch块进行难样本挖掘.作者对图片进行了水平和竖直分块,在垂直方向对图片分成了两块, .由于人体有对称性, 对同一张图片的左右两块patch,作者将其作为正样本对待, 而负样本对应着不同图片同一个位置的patch.
experiments: 也在各个数据集各个setting下做了对应的实验,针对ReID任务做出的改进确实有一定的作用.

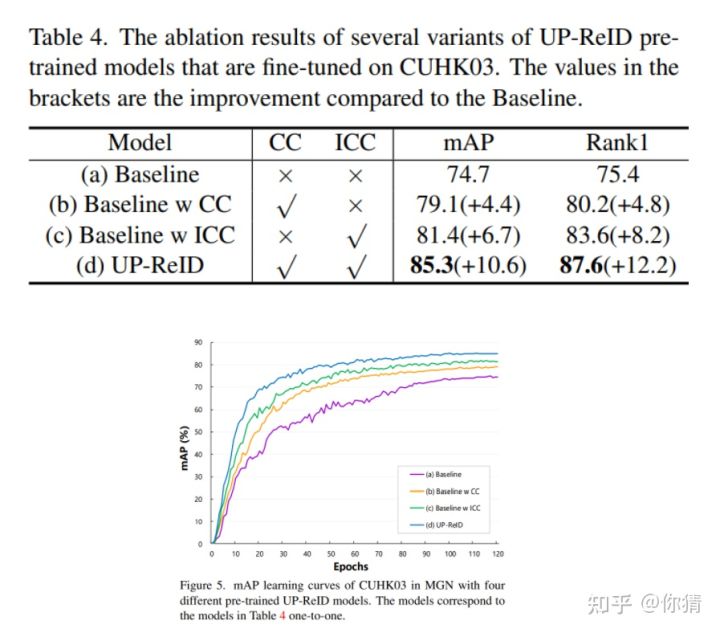
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification

publication: arxiv2021
abstract: 基于 Transformer 的监督预训练在人员重新识别 (ReID) 方面取得了出色的表现。然而,由于 ImageNet 和 ReID 数据集之间的领域差距,由于 Transformer 强大的数据拟合能力,它通常需要更大的预训练数据集(例如 ImageNet-21K)来提升性能。为了应对这一挑战,这项工作旨在分别从数据和模型结构的角度缩小预训练和 ReID 数据集之间的差距。我们首先研究了在未标记人物图像(LUPerson 数据集)上预训练 Vision Transformer (ViT) 的自我监督学习 (SSL) 方法,并根据经验发现它在 ReID 任务上明显优于 ImageNet 监督预训练模型。为了进一步缩小领域差距并加速预训练,提出了灾难性遗忘分数(CFS)来评估预训练和微调数据之间的差距。基于CFS,通过对下游ReID数据附近的相关数据进行采样并从预训练数据集中过滤不相关数据来选择一个子集。对于模型结构,提出了一个名为基于 IBN 的卷积干 (ICS) 的特定于 ReID 的模块,通过学习更多不变的特征来弥合领域差距。已经进行了广泛的实验来微调监督学习、无监督域适应 (UDA) 和无监督学习 (USL) 设置下的预训练模型。我们成功地将 LUPerson 数据集缩小到 50%,而没有性能下降。最后,我们在 Market1501 和 MSMT17 上实现了最先进的性能
code: https://github.com/michuanhaohao/TransReID-SSL
motivation: 探究了不同基于transformer的自监督学习方法在行人数据集上的应用。
method:
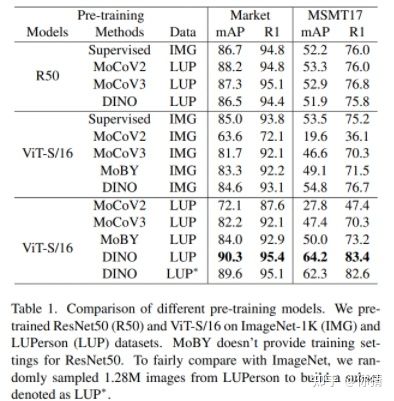
- 探究了transformer在不同的自监督学习方法在ReID数据集的作用。在使用DINO框架得到最好的结果后,基于DINO继续分别进行了在数据挑选和网络架构上的探究。 结论:DINO是最适合transformer-based ReID进行自监督学习的方法。预训练在transformer上的作用比在CNN上重要的多。基于transformer自监督预训练好的模型能够显著的提升ReID任务的性能。
2.为了加速网络的训练,甚至提高预训练的效果,作者提出了 一个灾难遗忘分数(CFS)来评估预训练的数据和目标数据的相似度。并通过这个分数挑选一半的数据进行预训练,达到了使用全部数据的效果,甚至更好。CFS算法如下

简单来说,就是使用在source data(预训练的数据)上预训练的模型和之后在target domain data(比如:MSMT17)上finetune的模型输出的向量计算相似度,通过这样来判断对应的图片对目标域的相似度: .由于用来评估相似度的模型可以采用更小的模型,也不用训练那么长时间,所以耗时并没有那么多。作者在文章中还对CFS进行了理论分析,有兴趣可以阅读原文。
3.此外,针对patchity stem采用卷积的结构能够提高模型训练的稳定性和提升性能。由于IBN对reid任务有着很好的效果,因此,作者在最开始的patchify stem中加入了他们提出的ICS结构:
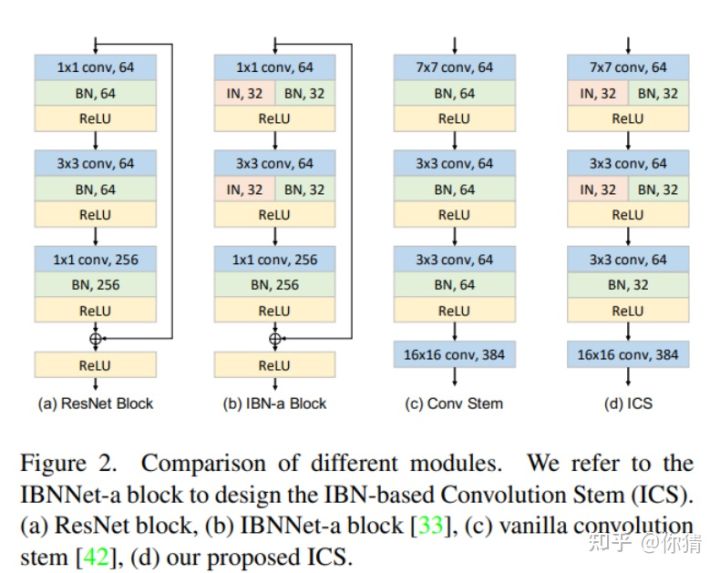
Experiments:
各种任务setting下的性能


以上是关于无监督预训练在Re-ID任务上的应用的主要内容,如果未能解决你的问题,请参考以下文章