“Oracle数据库并行执行”技术白皮书读书笔记
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“Oracle数据库并行执行”技术白皮书读书笔记相关的知识,希望对你有一定的参考价值。
本文为白皮书Parallel Execution with Oracle Database(2019年2月20日版本)的读书笔记。
简介
数据快速增长,但业务仍要求数据的快速处理。
并行执行是大规模数据处理的关键。并行执行使用多个进程来处理单个任务。
数据库越能有效地利用所有硬件资源——多个 CPU、多个 IO 通道、多个存储单元、集群中的多个节点——处理查询和其他数据库操作的效率就越高。
大型数据仓库应始终使用并行执行来获得良好的性能。 OLTP 应用程序中的特定操作(例如批处理操作)也可以从并行执行中显著受益。 本文涵盖三个主要主题:
- 并行执行的基本概念——为什么要使用并行执行以及它背后的基本原则是什么。
- Oracle 的并行执行实现和增强 ——在这里,您将熟悉 Oracle 的并行架构,学习有关并行执行的 Oracle 特定术语,并了解如何控制和识别并行 SQL 处理的基础知识。
- 控制 Oracle 数据库中的并行执行——最后一部分展示了如何在 Oracle 环境中启用和控制并行性,让您大致了解 DBA 需要考虑的问题。
并行执行的概念
并行执行是通过将任务拆分为更小的子任务(分而治之)来加速操作的常用方法。
为何使用并行执行
假设您的任务是计算街道上的汽车数量(停泊的,而不是运行的)。 有两种方法可以做到这一点,您可以自己过马路并数汽车数量,也可以招募朋友,然后你们两个可以从街道的两端开始数汽车直到相遇,并将两个计数的结果相加以完成任务。如果你和你朋友的速度相当,则用2倍的资源将时间减少了一半。
与之类似,如果数据库也用双倍的资源将处理时间减少一半,我们称此操作是线性扩展的。线性扩展是并行处理的终极目标。
并行执行理论
在计数汽车的例子中,我们做了一些基本的假设来达到线性可扩展性。 这些假设反映了并行处理背后的一些理论。
首先,我们选择只用我们两个人来计数。 此即数据库中所说的“并行度”(DOP)。 那么,要多少人才能最快的将车数完?显然,工作量越大,我们应使用的人就越多。当然,如果有一条只有 4 辆车的短街,我们应该避免任何并行,因为决定谁从哪里开始会比直接开始数需要更长的时间。
我们认为让我们两个人计数和协调的“开销”是值得的。 在数据库中,数据库引擎应根据操作的总成本做出此决定。
其次,在汽车示例中,我们将工作分成两个相等的部分,因为我们每个人都从街道的一端开始,我们假设每个人都以相同的速度计数。 数据库中的并行处理也是如此:第一步是将数据工作划分为大小相似的块,以便在相同的时间内处理它们。 通常使用某种形式的散列算法来平均划分数据。
这种用于并行处理的“数据分区”通常以两种基础的但根本不同的方式完成。 主要区别在于物理数据分区(放置)是否用作并行化工作的基础(因此是静态先决条件)。
这些在概念上基本不同的方法分别被称为全共享架构和无共享架构。
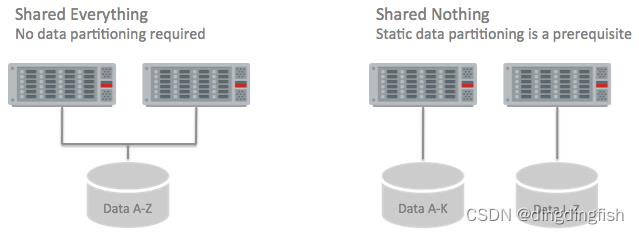
图 1:共享所有内容(全共享)与不共享任何内容(无共享)
在无共享系统中,系统在物理上被划分为单独的并行处理单元。
每个处理单元都有自己的处理能力(CPU 内核)和自己的存储组件;它的 CPU 内核独自负责其存储在其自身存储上的个人数据集。访问特定数据的唯一方法是使用拥有该数据子集的处理单元。这种系统通常也称为大规模并行处理 (MPP) 系统。数据分区是这些系统的基本前提。为了实现良好的工作负载分发,无共享系统必须使用散列算法在所有可用处理单元之间均匀地静态划分数据。控制数据放置的数据分区策略必须在系统初始创建时确定。
因此,无共享系统在其系统中引入了强制性的、固定的最小并行性,以便执行涉及表扫描的操作。固定并行度完全依赖于在数据库或对象创建时固定的静态数据分区:并行处理单元的数量决定了访问数据所有分区的最小并行度。大多数非 Oracle 数据仓库系统都是无共享系统。
Oracle 数据库依赖于全共享架构。这种架构不需要任何预定义的数据分区来启用并行性;所有数据都可以不受限制地从所有处理单元访问;操作的并行度与实际数据存储分离。但是,通过使用 Oracle 分区,Oracle 数据库可以在相同的处理范例上运行,提供与无共享系统完全相同的并行处理能力。值得注意的是,它不受数据布局中包含的固定并行访问的限制。因此,除了无共享系统的并行功能之外,Oracle 可以以各种方式和程度并行化几乎所有操作,而与底层数据布局无关。通过使用全共享架构,Oracle 允许灵活的并行执行和高并发性,而不会使系统过载,较无共享系统提供更多的并行执行能力。
Oracle数据库中的并行执行
Oracle 数据库提供并行执行复杂任务的功能,无需人工干预。 可以并行执行的操作包括但不限于:
- 数据加载
- 查询
- DML 语句
- RMAN 备份
- 对象创建,例如 索引或表创建
- 优化器统计信息收集
本文只关注 SQL 并行执行,它由并行查询、并行 DML(数据操作语言)和并行 DDL(数据定义语言)组成。
处理并行SQL语句
当您在 Oracle 数据库中执行 SQL 语句时,它会分解为单独的步骤或行源,它们在执行计划中被标识为单独的行。 下面是一个简单的 SQL 语句示例,它只涉及一个表及其执行计划。 该语句返回 CUSTOMERS 表中的客户总数:
set pages 9999
select count(*) from customers c;
select * from table(dbms_xplan.display_cursor);
Plan hash value: 1718497476
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 3 (100)| |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | BITMAP CONVERSION COUNT | | 55500 | 3 (0)| 00:00:01 |
| 3 | BITMAP INDEX FAST FULL SCAN| CUSTOMERS_GENDER_BIX | | | |
----------------------------------------------------------------------------------------------
图 2:CUSTOMERS 表上 COUNT(*) 的串行执行计划
再来看一个复杂的带Join的例子:
select c.cust_first_name, c.cust_last_name, s.amount_sold
from customers c, sales s
where c.cust_id=s.cust_id;
select * from table(dbms_xplan.display_cursor);
Plan hash value: 1163973071
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 1998 (100)| | | |
|* 1 | HASH JOIN | | 918K| 26M| 1736K| 1998 (2)| 00:00:01 | | |
| 2 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1083K| | 423 (1)| 00:00:01 | | |
| 3 | PARTITION RANGE ALL| | 918K| 8973K| | 523 (3)| 00:00:01 | 1 | 28 |
| 4 | TABLE ACCESS FULL | SALES | 918K| 8973K| | 523 (3)| 00:00:01 | 1 | 28 |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("C"."CUST_ID"="S"."CUST_ID")
Note
-----
- this is an adaptive plan
图 3:显示两个表连接的更复杂的串行执行计划
如果加上hint /*+ parallel(4) */让其并行执行,Oracle 数据库将尽可能多地并行化各个步骤,并将其反映在执行计划中。
Plan hash value: 1718497476
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 2 (100)| | | | |
| 1 | SORT AGGREGATE | | 1 | | | | | |
| 2 | PX COORDINATOR | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | | | Q1,00 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | 1 | | | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 55500 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 6 | BITMAP CONVERSION COUNT | | 55500 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
|* 7 | BITMAP INDEX FAST FULL SCAN| CUSTOMERS_GENDER_BIX | | | | Q1,00 | PCWP | |
-------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 1163973071
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 264 (100)| | | | | | |
| 1 | PX COORDINATOR | | | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 918K| 26M| 264 (2)| 00:00:01 | | | Q1,01 | P->S | QC (RAND) |
|* 3 | HASH JOIN | | 918K| 26M| 264 (2)| 00:00:01 | | | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 55500 | 1083K| 117 (0)| 00:00:01 | | | Q1,01 | PCWP | |
| 5 | PX SEND BROADCAST | :TQ10000 | 55500 | 1083K| 117 (0)| 00:00:01 | | | Q1,00 | P->P | BROADCAST |
| 6 | PX BLOCK ITERATOR | | 55500 | 1083K| 117 (0)| 00:00:01 | | | Q1,00 | PCWC | |
|* 7 | TABLE ACCESS FULL| CUSTOMERS | 55500 | 1083K| 117 (0)| 00:00:01 | | | Q1,00 | PCWP | |
| 8 | PX BLOCK ITERATOR | | 918K| 8973K| 145 (3)| 00:00:01 | 1 | 28 | Q1,01 | PCWC | |
|* 9 | TABLE ACCESS FULL | SALES | 918K| 8973K| 145 (3)| 00:00:01 | 1 | 28 | Q1,01 | PCWP | |
----------------------------------------------------------------------------------------------------------------------------------
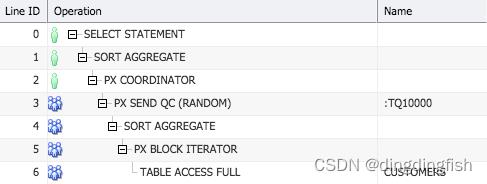
图 4:CUSTOMERS 表上 COUNT(*) 的并行执行计划
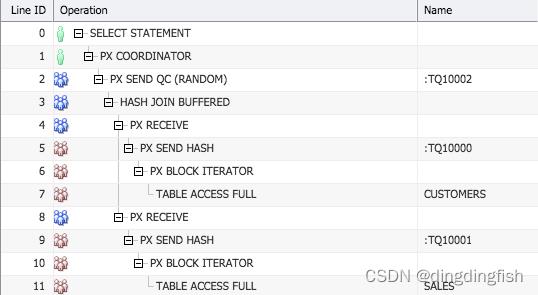
图 5:客户购买信息,并行计划
查询协调 (QC) 和并行执行 (PX) 服务器
Oracle 数据库中的 SQL 并行执行基于协调器(通常称为查询协调器 - 简称 QC)和并行执行 (PX) 服务器进程。 QC 是启动并行 SQL 语句的会话,而 PX 服务器是代表启动会话并行执行工作的各个进程。
QC 将工作分配给 PX 服务器,并且可能必须执行无法并行执行的最小(主要是后勤)部分工作。 例如,具有 SUM() 操作的并行查询需要将每个 PX 服务器计算的所有单独的小计最终相加,这由 QC 完成。
QC 在执行计划中被标识为“PX COORDINATOR”。 充当并行 SQL 操作的 QC 的进程是实际的用户会话进程本身。
PX 服务器取自全局可用的 PX 服务器进程池,并在操作的生命周期内分配给给定的操作(设置将在后面的部分中讨论)。 在示例并行计划中,PX 服务器执行 QC 条目下方显示的所有工作。
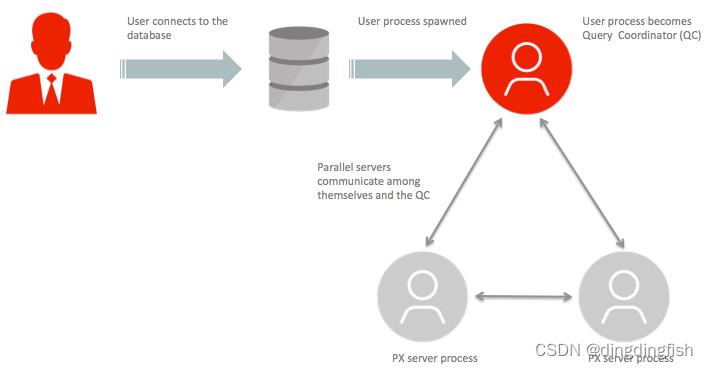
图 6:使用查询协调器和一组 PX 服务器进程并行执行
在操作系统中,很容易找到这些并行进程:
oracle 1140 1 0 May23 ? 00:00:00 ora_p000_ORCLCDB
oracle 1148 1 0 May23 ? 00:00:00 ora_p001_ORCLCDB
oracle 1153 1 0 May23 ? 00:00:00 ora_p002_ORCLCDB
oracle 1160 1 0 May23 ? 00:00:00 ora_p003_ORCLCDB
图 7:使用“ps -ef”在 Linux 操作系统级别上看到的 PX 服务器进程
他们的数量是由初始化参数设置的:
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
parallel_min_servers integer 4
回到汽车计数的例子:您和您的朋友充当 PX 服务器,并且会有第三人 - QC - 告诉您和您的朋友继续计数汽车。
如果我们用数据库来模拟这个例子,在下图中。您和您的朋友将继续数数您身边的汽车; 这相当于 Line ID 4、Line ID 5 和 Line ID 6 的操作,其中 Line ID 5 相当于告诉你们每个人只计算自己所在路侧的汽车。
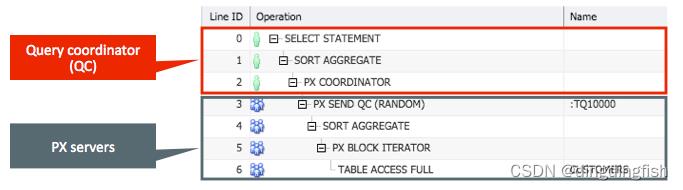
图 8:执行计划中显示的 QC 和 PX 服务器进程
在计算完你的路段后,你们每个人都会告诉第三个人 - QC - 你的个人小计(第 3 行),然后他或她将你的两个小计相加以获得最终结果(第 1 行)。 这是从 PX 服务器(进行实际工作的进程)到 QC 的移交,以对结果进行最终“组装”,然后将其返回给用户进程。 使用 SQL Monitor有助于轻松识别 PX 服务器正在完成的工作(在给定操作前有许多蓝色或红色的小人),以及串行执行(绿色小人)。
生产者/消费者 模型
继续我们的汽车计数示例,假设工作是计算每种颜色的汽车总数。 如果您和您的朋友各自负责道路的一侧,那么你们每个人都可能看到相同的颜色并获得每种颜色的小计,但不是给定颜色在整个街道的完整结果。 你可以继续,记住所有这些信息,然后告诉第三个人(“负责人”)。 但是这个可怜的人必须自己总结所有的结果——如果街上所有的汽车都是不同的颜色怎么办(这个假设太极端了)? 第三个人会重做与您和您的朋友刚才所做的完全相同的工作。
要在每个颜色的基础上并行计算,您只需再请两个朋友帮助您:这些朋友都和您一起走在路中间,其中一个从您和您的朋友处获得所有深色的计数,另一个获取所有明亮颜色的计数。
每当你计算一辆新车时,你都会告诉负责这种颜色的人关于新的计数——你产生信息,根据颜色信息重新分配它,然后颜色计数器消费信息。 最后,两位负责颜色汇总的朋友将他们的结果告诉负责人:QC,然后就完成了; 我们有两组并行工作人员,每组都有两个朋友一起肩并肩的做部分工作。
这正是数据库的工作方式:为了有效地并行执行语句,PX 服务器成对工作:一组生产行(生产者),一组消费行(消费者)。 例如,对于 SALES 和 CUSTOMERS 表之间的并行联结,一组 PX 服务器读取表并将数据发送到另一组:接收数据(消费者)并联结两个表。
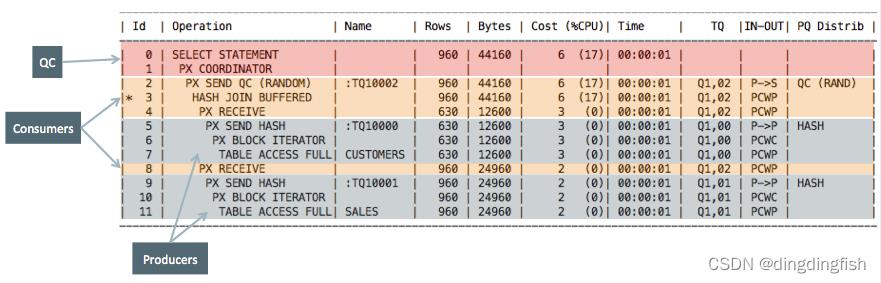
图 9:生产者和消费者
通过查看 TQ 列,可以在执行计划中识别由同一组 PX 服务器处理的操作(行源)。 如上图所示,第一个 PX 服务器集 (Q1,00) 正在并行读取表 CUSTOMERS 并生成发送到 PX 服务器集 2 (Q1,02) 的行,后者使用这些记录并将它们与来自销售表 (Q1,01)的记录进行联结。
SQL Monitor 以交替颜色显示在并行语句上工作的不同 PX 服务器集,从而更容易识别工作单元的边界以及必须重新分配数据的位置。 每当数据从生产者分发到消费者时,您都会在 NAME 列中看到格式为 :TQxxxxx(表队列 x)的条目作为数据输出。 请暂时忽略图 9 中其他列的内容。
这种生产者/消费者模型中,分配给指定并行操作的 PX 服务器数量具有非常重要的影响。生产者/消费者模型需要两组 PX 服务器进行并行操作,所以 PX 服务器的数量是请求的并行度 (DOP) 的两倍。例如,上图 中的并行连接以 4 的并行度运行,则此语句将使用 8 个 PX 服务器,4 个生产者和 4 个消费者。
PX 服务器不成对工作的唯一情况是,如果语句非常简单,以至于只有一组 PX 服务器可以并行完成整个语句。 例如,SELECT COUNT(*) FROM customers; 只需要一套 PX 服务器(参见之前的执行计划)。
颗粒(GRANULES)
颗粒是访问数据时的最小工作单元。 Oracle 数据库使用全共享架构,从存储的角度来看,这意味着配置中的任何 CPU 内核都可以访问任何数据; 这是 Oracle 与大多数其他数据库供应商之间最基本的架构差异。 与这些其他系统不同的是,Oracle 可以并且将完全根据查询的要求选择这个最小的工作单元。
Oracle 数据库用于为并行执行分配工作的基本机制是块范围,即所谓的基于块的粒度。 这些块可能驻留在存储中,或者在In-Memory并行执行的情况下驻留在内存中,这将在本文后面讨论。 这种方法是 Oracle 独有的,与对象是否已分区无关。 对底层对象的访问被划分为大量的颗粒,这些颗粒被分配给 PX 服务器进行处理(当 PX 服务器处理完一个颗粒时,即分配下一个)。
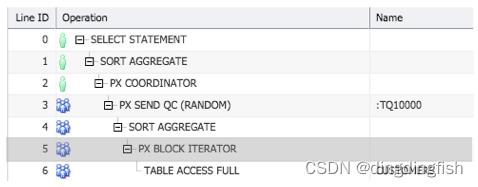
图 10:客户计数示例中基于块的粒度。
为了在 PX 服务器之间获得均匀的工作分配,颗粒的数量总是比请求的 DOP 高得多。 上图显示的操作“PX BLOCK ITERATOR”实际上是对所有生成的块范围颗粒的迭代。
尽管基于块的粒度是为大多数操作启用并行执行的基础,但仍有一些操作可以从底层分区数据结构中受益,并将各个分区用作工作粒度。 使用基于分区的粒度,只有一台 PX 服务器为单个分区中的所有数据执行工作。 如果操作中访问的(子)分区数至少等于 DOP(如果单个(子)分区的大小可能存在偏差,则理想情况下要高得多),Oracle 优化器会考虑基于分区的粒度。 使用基于分区的粒度最常见的操作是分区联结,稍后将讨论。
Oracle 数据库根据 SQL 语句和 DOP 决定颗粒是基于块还是基于分区,已得到更优化的执行; 你不能影响这种行为。
在汽车计数的例子中,街道的一侧——甚至是一条长街的一个街区——可以被认为相当于一个基于块的颗粒。 现有的数据量(街道)被细分为物理部分,PX 服务器(您和您的朋友)在这些物理部分上独立工作。 漫长的道路上有许多街区,我们只能让您和您的朋友在上面工作,每个人都覆盖一半的街区(“颗粒”)。 或者,我们可以让你和三个朋友一起工作,每个人都覆盖四分之一的街区。 您可以选择与您一起工作的朋友的数量,这样您的计数是可扩展的。
如果我们将道路视为“静态分隔”,左右两侧的路缘作为分隔,那么您只能请一个朋友帮助您:您的其他朋友没有什么可做的。 使用这种静态方法是纯无共享系统的工作方式,并显示了这种架构的局限性。
数据重新分配
并行操作——除了最基本的操作——通常需要重新分配数据,以执行并行排序、聚合和连接等操作。
在块颗粒级别,无法知道单个粒度中包含的实际数据; 块颗粒只是没有逻辑内涵的物理块。 因此,一旦后续操作依赖于实际内容,就必须重新分配数据。 在汽车按颜色计数的示例中,您不知道(甚至无法控制)街道上停放什么颜色的汽车。 您根据颜色责任将每种颜色的汽车数量信息重新分配给另外两个朋友,使他们能够对他们负责的颜色进行总计。
数据重新分配发生在单个机器内或者跨多台机器(节点)的 Real Application Clusters (RAC) 系统间的各个 PX 服务器集之间进行。 当然,在后一种情况下,需要互连通信用于数据重新分配。
数据重新分配并不是 Oracle 数据库独有的。 事实上,这是并行处理最基本的原则之一,被每个提供并行能力的产品所使用。 然而,Oracle 功能的根本区别和优势在于并行数据访问(在前面的粒度部分中讨论过)以及因此必要的数据重新分配不受任何给定硬件架构或数据库设置(数据分区)的限制。
像全共享系统一样,无共享系统也需要重新分配数据,除非操作可以完全依赖分区联结(如本节后面所述)。 在无共享系统中,无法从分区连接中受益的并行操作——例如在两个不同联结键上的简单三向表联结——总是需要重新分配数据,并且总是大量使用互连通信。 由于 Oracle 数据库可以在节点的上下文中启用并行执行,因此并行操作不一定总是必须使用互连通信,从而避免了互连处的潜在瓶颈。
以下部分将使用一个简单的表联结示例来解释 Oracle 的数据重新分配功能,该示例没有任何辅助数据结构,例如索引或物化视图,以及其他优化。
串行联结
在串行两路联结中,单个会话读取涉及的两个表并执行联结。 在此示例中,我们假设联结中涉及两个大表 CUSTOMERS 和 SALES。 数据库使用全表扫描来访问这两个表。
对于串行联结,单个串行会话扫描两个表并执行完全连接,如下图。
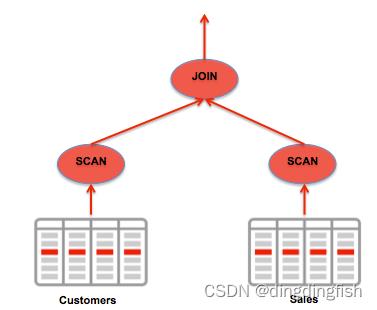
图 11:串行联结
并行联结
并行处理相同的简单两路联结,行的分发将成为确保数据被正确划分以进行后续并行处理的必要条件。 在此示例中,PX 服务器根据块范围扫描任一表的物理部分,为了完成联结,必须根据 PX 服务器集之间的联结键值分发行; 您必须确保相同的联结键值由同一个 PX 服务器处理,并且每一行只处理一次。
图 12 描绘了之前图 9 中所示的并行联结在 DOP 为 2 时的数据分发。
由于此联结需要两组 PX 服务器,实际上为此查询分配了四台 PX 服务器,PX1 和 PX2 读取表,PX3 和 PX4 执行联结。 PX1 和 PX2 都使用块范围粒度并行读取这两个表,然后每个 PX 服务器根据联结键的值将其结果集分发给后续的并行联结运算符; 必须将两个表中的相同联结键的值发送到执行联结操作的同一个 PX 服务器,以确保正确联结数据。
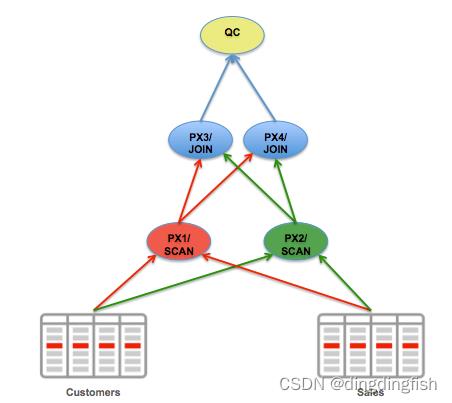
图 12:并行联结
有许多数据分发方法。 以下是最常见的:
哈希:哈希发在并行执行中非常常见,以便基于哈希函数实现各个 PX 服务器的工作平均分配。 哈希发是大多数数据仓库系统的基本并行执行启用机制。
下面的图 13 显示了一个使用哈希发方法的执行计划。 这实际上是图 12 中所示的联结计划。
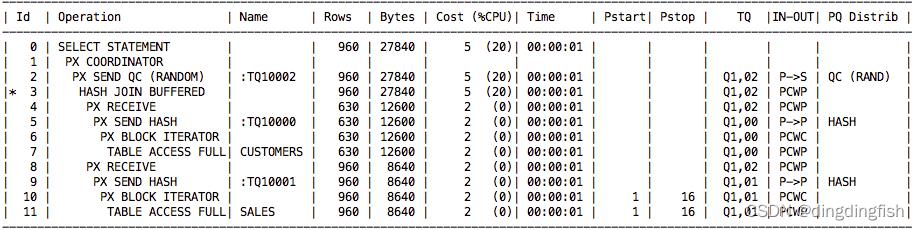
图 13:哈希发的执行计划
假设此计划的 DOP 为 2,一个 PX 集(PX1 和 PX2)读取 CUSTOMERS 表,对联结列应用哈希函数并将行发送到另一个 PX 集(PX3 和 PX4)的 PX 服务器,这 PX3 获取一些行,PX4 获取其他行的方式取决于计算的哈希值。 然后 PX1 和 PX2 读取 SALES 表,对联结列应用哈希函数并将行发送到另一个 PX 集(PX3 和 PX4)。 PX3 和 PX4 现在都有来自两个表的匹配行并且可以执行联结。
每个表的分配方法可以在 PQ Distrib 和 Operation 列的计划中看到,这里 PQ Distrib 两个表都显示了 HASH,而 Operation 在第 5 行和第 9 行显示了 PX SEND HASH。
广播:当联结操作中的两个结果集之一远小于另一个结果集时,就会发生广播分发。 数据库不会从两个结果集中分配行,而是将较小的结果集发送到所有 PX 服务器,以确保各个服务器能够完成它们的联结操作。 联结操作中广播较小表的优点是根本不必重新分配较大的表。
下面的图 14 显示了一个使用广播分发方法的执行计划。
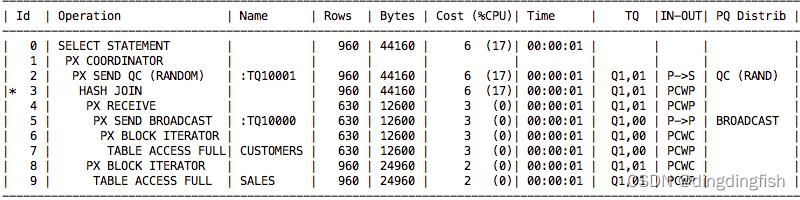
图 14:广播分发的执行计划
假设此计划的 DOP 为 2,一个 PX 集(PX1 和 PX2)读取 CUSTOMERS 表并将其所有结果集广播到另一个 PX 集(PX3 和 PX4)。 PX3 和 PX4 现在可以读取 SALES 表并执行联结,因为它们都具有 CUSTOMERS 表中的所有行。在执行计划中我们可以看到第 5 行的分发方式,PQ Distrib 列显示 BROADCAST,Operation 列显示 PX SEND BROADCAST。
范围:范围分发一般用于并行排序操作。 单独的 PX 服务器在数据范围内处理,因此 QC 不必进行任何排序,而只需以正确的顺序显示单独的 PX 服务器结果。
图 15 显示了使用范围发方法进行简单 ORDER BY 查询的执行计划。

图 15:范围分发的执行计划
假设此计划的 DOP 为 2,一个 PX 集(PX1 和 PX2)读取 SALES 表,PX1 和 PX2 根据 ORDER BY 子句中列的值将它们读取的行发送到 PX3 或 PX4。PX3 和 PX4 中的每一个都拥有一个数据范围,因此它们对获取的行进行排序并将结果发送给 QC,QC 不需要进行任何排序,因为这些行已经按 PX3 和 PX4 排序。QC 只需保证首先从工作在必须首先返回的范围的 PX 服务器返回行。 例如,如果排序是基于time_id,最新数据优先,PX3拥有1月之前的数据范围,PX4拥有更新的数据,那么QC首先将PX4的排序结果返回给最终用户,然后再将结果从PX3返回给最终用户。 确保整个结果的正确排序。
在执行计划中我们可以看到第 5 行的分发方法,PQ Distrib 列显示 RANGE,Operation 列显示 PX SEND RANGE。
键:键分发确保单个键值的结果集聚集在一起。 这是一种优化,主要用于部分分区连接(请参阅下文),以确保连接中只有一侧必须分发。
图 16 显示了使用键分发方法的执行计划。

图 16:键分发的执行计划
CUSTOMERS 表在联结列上进行了哈希分区,而 SALES 表没有进行分区。 该计划显示,一个 PX 集(PX1 和 PX2)读取 SALES 表并根据 CUSTOMERS 表的分区将行发送到其他 PX 集服务器(PX3 和 PX4)。这样 PX3 和 PX4 可以同时在单独的分区上工作,因为它们具有来自 SALES 的所有匹配行,用于它们需要联结的分区。 PX3 和 PX4 没有行重新分配。
在执行计划中我们可以看到第 5 行的分发方式,PQ Distrib 列显示 PART (KEY),Operation 列显示 PX SEND PARTITION (KEY)。
混合哈希:Oracle Database 12c 中引入的混合哈希方法是一种自适应分发技术,它将最终分发方法的决策延迟到执行时间,并且基于结果集的大小。 一个名为 STATISTICS COLLECTOR 的新计划步骤放置在新的混合哈希分发之前,它计算从 PX 服务器返回的行数,并根据最大阈值检查计数。 如果达到阈值,则基于哈希分发方法分发行更具成本效益。 如果完整结果集的大小低于阈值,则使用广播分发方法。
图 17 显示了使用混合哈希分发方法的执行计划。
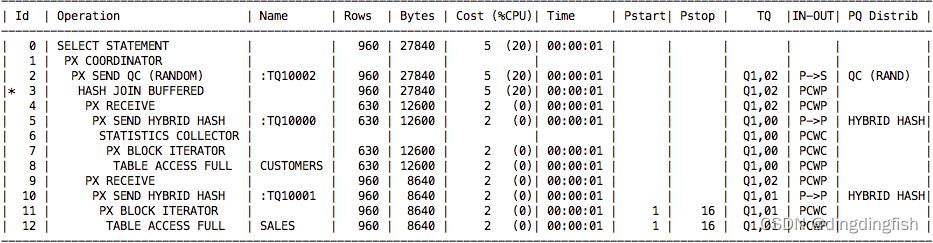
图 17:混合哈希分发的执行计划
在执行计划中我们可以看到第 5 行和第 10 行的分发方式,PQ Distrib 列显示 HYBRID HASH,Operation 列显示 PX SEND HYBRID HASH。 在第 6 行可以看到新的计划步骤 STATISTICS COLLECTOR。
作为数据分发方法的一种变体,您可能会在 Real Application Clusters (RAC) 数据库的并行执行计划中看到 LOCAL 后缀。 LOCAL 分布是针对 RAC 环境的优化,可最大限度地减少节点间并行查询的互连流量。 例如,您可能会在执行计划中看到 BROADCAST LOCAL 分布,指示行集是在本地节点上生成的,并且仅发送到该节点上的 PX 服务器。
并行分区联结
即使数据库尝试根据优化器统计信息选择最佳分布方法,在 PX 集之间分布行也需要进程间或有时是实例间通信。完全或部分的分区连接等技术可以最小化甚至阻止数据分发,从而潜在地显著提高并行执行的性能。
如果联结中至少有一个表在联结键上进行了分区,则数据库可能会决定使用分区联结。 如果两个表在联结键上均等分区,则数据库可以使用完全分区联结。 否则,可以使用部分分区联结,其中一个表在内存中动态分区,然后是完全分区连接。
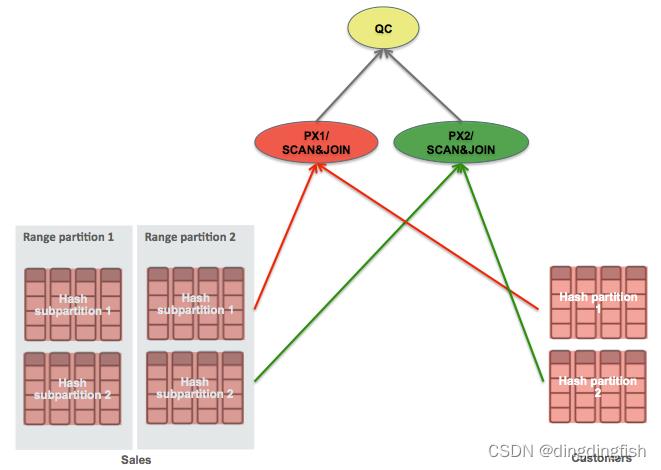
图 18:完全分区联结无需数据分布
分区联结不需要任何数据分布,因为单个 PX 服务器将在两个联结表的对等分区上工作。图 18 显示了与图 12 相同的联结语句,但这次,这些表在联结列 cust_id 上进行了对等分区,在此示例中,CUSTOMERS 表按 cust_id 列进行哈希分区,而 SALES 表首先按日期列进行范围分区 ,然后按 cust_id 列进行哈希子分区。如图 PX1 读取 SALES 表的一个范围分区的所有子分区,然后读取 CUSTOMERS 表的等效散列分区。(这在图 19 中执行计划中表示为 SALES 表的全表扫描顶部的 PARTITION RANGE ALL 迭代器);联结键上两个表的对等分区保证了在这些分区之外没有匹配的行联结。PX 服务器将始终能够通过仅读取这些匹配分区来完成完全联结。 PX2 和这两个表的任何对等分区也是如此。 请注意,分区联结使用基于分区的粒度而不是基于块的粒度。 与图 12 相比,您还可以看到分区联结使用单个 PX 服务器集而不是两个。

图 19:分区联结的执行计划
Operation 和 PQ Distrib 列表示没有数据分布,TQ 列表示只使用了一个 PX 集。
分区连接是无共享系统的基本推动力。 无共享系统通常可以很好地扩展,只要它们可以利用分区联结。 因此,在无共享系统中选择分区(分布)是关键,表的访问路径也是一样。 在 MPP 系统中不使用智能分区的操作通常不能很好地扩展。
In-Memory 并行执行
与数据绕过任何共享缓存并直接传输到 PX 服务器进程的内存 (PGA) 的传统并行处理不同,内存中并行执行 (in-memory PX) 利用共享内存缓存 (SGA) 存储数据以供后续并行处理。 in-memory PX 充分利用了当今数据库服务器不断增加的内存; 这在大规模集群环境中特别有用,即使单个数据库服务器“仅”拥有数十或数百 GB 的内存,总内存量也可能达到数 TB。 借助in-memory PX,Oracle 使用 Real Application Clusters (RAC) 环境中服务器的聚合内存缓存来确定性地缓存分布在所有节点内存中的对象。 这确保了后续的并行查询将从所有节点的内存中读取数据,而不是从存储中读取数据,从而大大加快处理时间。
借助 Oracle Database In-Memory 选件,一种专为内存处理而设计的列式内存数据存储,可实现对大量数据的实时分析。 其针对内存的压缩列格式和优化的数据处理算法提供了可能最佳的内存处理。 利用 Oracle 新的 Database In-Memory 技术是内存处理的推荐方法。
没有 Database In-Memory 选项的系统也可以利用内存 PX,但不能使用内存压缩的列式存储和优化的内存算法。在这种情况下,数据库使用内存 PX 的标准数据库缓冲区缓存,与用于在线事务处理的缓存相同。
由于它们使用相同的缓存,因此在 OLTP 和并行操作之间存在“竞争”缓冲区缓存的风险,为确保并行操作不会占用整个缓存,Oracle 数据库将in-memory PX 可以使用的缓冲区缓存的百分比限制为 80%。
根据并行处理的数据量和 OLTP 应用程序的内存需求, in-memory PX 的优势可能会受到此模型的限制。 大多数情况下,具有较小数据量和更多混合(和不断变化)的工作负载特征的系统会从这种方法中受益。
为了扩大内存中 PX 的适用性,无论是在符合内存处理条件的对象大小方面,还是为了提供优化的全表扫描感知缓存,自动大表缓存 (ABTC) 功能都在缓冲区缓存中保留了区域专门用于并行内存处理。
使用 ABTC,保留一部分数据库缓冲区缓存以在内存中存储大对象(或其中的一部分),以便更多查询可以利用内存中的并行执行。 符合缓存条件的对象的大小最多可以是可用保留内存的三倍。 ABTC 使用优化的分段和基于热度的算法来确保可用缓存的最佳使用。
使用 ABTC 启用内存 PX 需要设置以下两个参数:
- PARALLEL_DEGREE_POLICY:必须设置为 AUTO 或 ADAPTIVE
- DB_BIG_TABLE_CACHE_PERCENT_TARGET:指定为内存中PX 保留的数据库缓冲区缓
以上是关于“Oracle数据库并行执行”技术白皮书读书笔记的主要内容,如果未能解决你的问题,请参考以下文章