分支预测
Posted linhaostudy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分支预测相关的知识,希望对你有一定的参考价值。
分支预测( Branch predictor):当处理一个分支指令时,有可能会产生跳转,从而打断流水线指令的处理,因为处理器无法确定该指令的下一条指令,直到分支指令执行完毕。流水线越长,处理器等待时间便越长,分支预测技术就是为了解决这一问题而出现的。因此,分支预测是处理器在程序分支指令执行前预测其结果的一种机制。在ARM中,使用全局分支预测器,该预测器由转移目标缓冲器( Branch Target Buffer,BTB)、全局历史缓冲器( Global History Buffer,GHB) MicroBe,以及 Return Stack组成。
采用分支预测,处理器猜测进入哪个分支,并且基于预测结果来取指、译码。如果猜测正确,就能节省时间,如果猜测错误,大不了从头再来,刷新流水线,在新的地址处取指、译码。
分支预测算法:
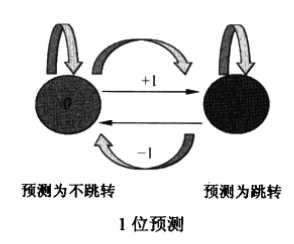
无条件跳转指令必然会跳转,而条件跳转指令有时候跳转,有时候不跳转,一种简单的预测方式就是根据该指令上一次是否跳转来预测当前时刻是否跳转。如果该跳转指令上次发生跳转,就预测这一次也会跳转,如果上一次没有跳转,就预测这一次也不会跳转。这种预测方式称为:1位预测(1- bit prediction)
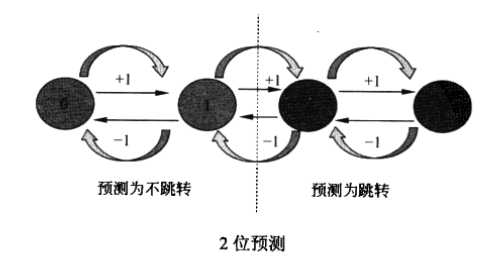
2位预测(2- bit predictor)。每个跳转指令的预测状态信息从1bit增加到2bit计数器,如果这个跳转执行了,就加1,加到3就不加了,如果这个跳转不执行,就减1,减到0就不减了,当计数器值为0和1时,就预测这个分支不执行,当计数器值为2和3时,就预测这个分支执行。2位的计数器比1位的计数器拥有更好的稳定性。
通常商用的处理器会使用多种策略的组合,来获得更好的预测结果;
分支预测实现
算法是基础,有了算法后,就可以在处理器中实现分支预测功能。 Intel的分支预测模块包含了3个单元:
- Branch Target Buffer(BTB)
- The Static Predictor
- Return stack
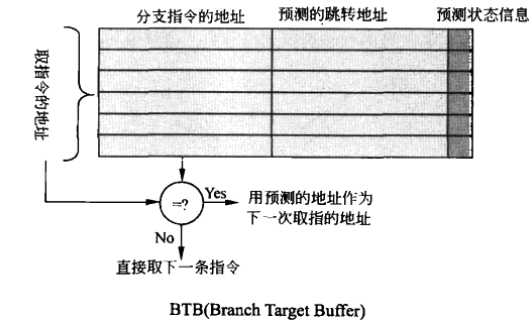
基本的BTB结构如下:
分支指令在执行后,会将这条指令的地址及它的跳转信息记录在BTB中。 BtB buffer不会太大,不能将所有的分支指令都存进去,通常采用Hash表的方式存入。在取指时,先将PC(程序指针)和BTB中的分支指令的地址进行比较,如果找到了,说明这条指令是分支指令,并且在BTB中有记录,就使用BTB预测出来的跳转地址。如果没有记录,就不能使用BTB的信息了,取指下一条指令。
Intel的 Branch Target Buffer还包含了历史跳转信息,用于预测分支指令是否发生跳转。
The Static Predictor
当分支指令在BTB中记录了历史信息才能使用BTB进行预测,当分支在BTB中找不到记录时,可以使用 The Static Predictor(静态预测器)。人们将分支指令的执行情况做了大量的统计,从中总结出一些特征,并将这些特征总结为一些固定的策略,这就是静态预测器.
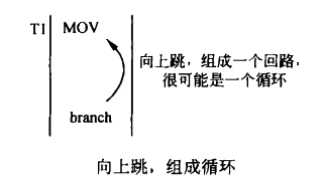
当指令被解码后,它是不是分支指令,以及要跳转的地方就知道了,只是不知道是否该跳。一般来说,向上的跳转,常用来组织成循环,这个跳转应该被预测为执行。
Return Stack
函数调用在程序中大量出现,函数调用与返回也都是通过跳转来实现的。例如,有3个函数调用了 printf函数,pinf函数地址固定,调用时知道地方,但是在返回时,并不知道该返回到哪个地方, Retum Stack(返回栈)可以用于解决这个问题。在函数调用时,将函数的返回地址压栈到 Retum Stack中,当遇到函数返回指令时,就从 Retum Stack中取出地址。
部分来自《大话处理器》这本书;
以上是关于分支预测的主要内容,如果未能解决你的问题,请参考以下文章