介绍 Pandas 实战中一些高端玩法
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了介绍 Pandas 实战中一些高端玩法相关的知识,希望对你有一定的参考价值。

作者 | 俊欣
来源 | 关于数据分析与可视化
相信大家平常在工作学习当中,需要处理的数据集是十分复杂的,数据集当中的索引也是有多个层级的,那么今天小编就来和大家分享一下DataFrame数据集当中的分层索引问题。
什么是多重/分层索引
多重/分层索引(MultiIndex)可以理解为堆叠的一种索引结构,它的存在为一些相当复杂的数据分析和操作打开了大门,尤其是在处理高纬度数据的时候就显得十分地便利,我们首先来创建带有多重索引的DataFrame数据集
多重索引的创建
首先在“列”方向上创建多重索引,即我们在调用columns参数时传递两个或者更多的数组,代码如下
df1 = pd.DataFrame(np.random.randint(0, 100, size=(2, 4)),
index= ['ladies', 'gentlemen'],
columns=[['English', 'English', 'French', 'French'],
['like', 'dislike', 'like', 'dislike']])output

那么同理我们想要在“行”方向上存在多重索引,则是在调用index参数的时候传递两个或者更多数组即可,代码如下
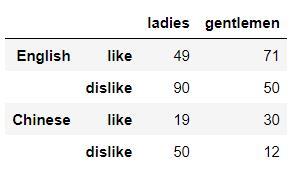
df = pd.DataFrame(np.random.randint(0, 100, size=(4, 2)),
index= [['English','', 'Chinese',''],
['like','dislike','like','dislike']],
columns=['ladies', 'gentlemen'])output
除此之外,还有其他几种常见的方式来创建多重索引,分别是
pd.MultiIndex.from_arrayspd.MultiIndex.from_framepd.MultiIndex.from_tuplespd.MultiIndex.from_product
小编这里就挑其中的一种来为大家演示如何来创建多重索引,代码如下
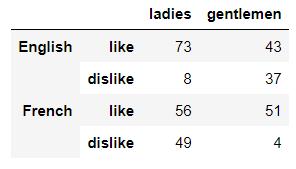
df2 = pd.DataFrame(np.random.randint(0, 100, size=(4, 2)),
columns= ['ladies', 'gentlemen'],
index=pd.MultiIndex.from_product([['English','French'],
['like','dislike']]))output
获取多重索引的值
接下来我们来看一下怎么获取带有多重索引的数据集当中的数据,使用到的数据集是英国三大主要城市伦敦、剑桥和牛津在2019年全天的气候数据,如下所示
import pandas as pd
from pandas import IndexSlice as idx
df = pd.read_csv('dataset.csv',
index_col=[0,1],
header=[0,1]
)
df = df.sort_index()
dfoutput
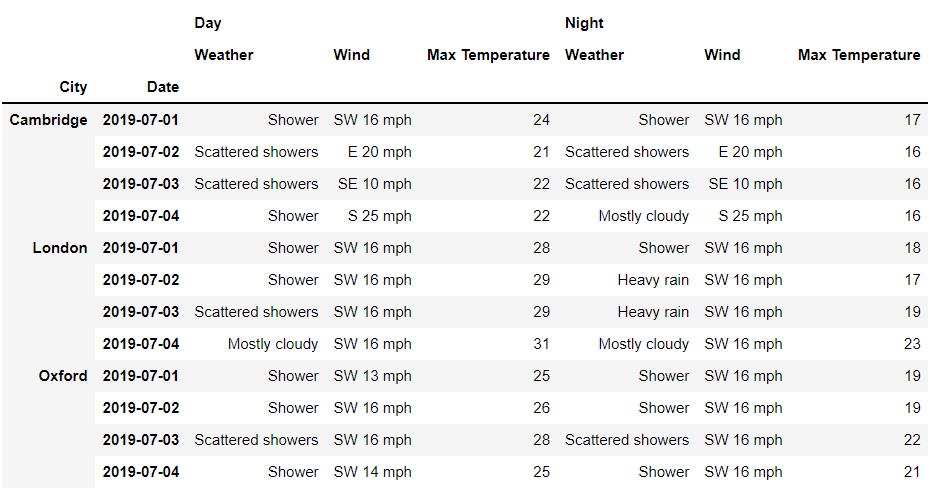
在“行”索引上,我们可以看到是“城市”以及“日期”这两个维度,而在“列”索引上,我们看到的是则是“不同时间段”以及一些“气温”等指标,首先来看一下“列”方向多重索引的层级,代码如下
df.columns.levelsoutput
FrozenList([['Day', 'Night'], ['Max Temperature', 'Weather', 'Wind']])我们想要获取第一层级上面的索引值,代码如下
df.columns.get_level_values(0)output
Index(['Day', 'Day', 'Day', 'Night', 'Night', 'Night'], dtype='object')那么同理,第二层级的索引值,只是把当中的0替换成1即可,代码如下
df.columns.get_level_values(1)output
Index(['Weather', 'Wind', 'Max Temperature', 'Weather', 'Wind',
'Max Temperature'],
dtype='object')那么在“行”方向上多重索引值的获取也是一样的道理,这里就不多加以赘述了
数据的获取
那么涉及到数据的获取,方式也有很多种,最常用的就是loc()方法以及iloc()方法了,例如
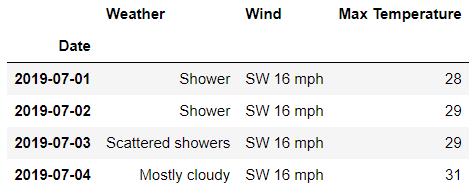
df.loc['London' , 'Day']
## 或者是
df.loc[('London', ) , ('Day', )]output
通过调用loc()方法来获取第一层级上的数据,要是我们想要获取所有“行”的数据,代码如下
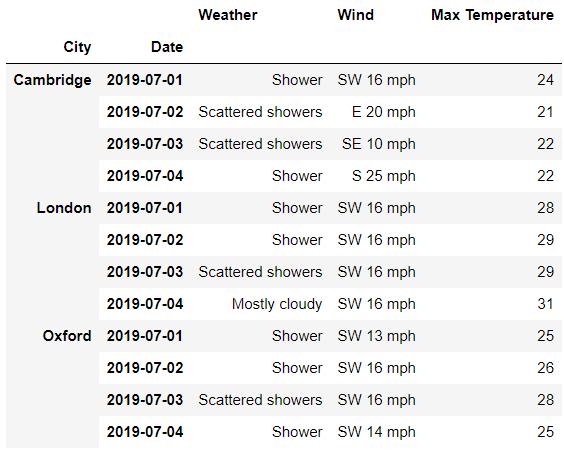
df.loc[:, 'Day']
## 或者是
df.loc[:, ('Day',)]output
或者是所有“列”的数据,代码如下
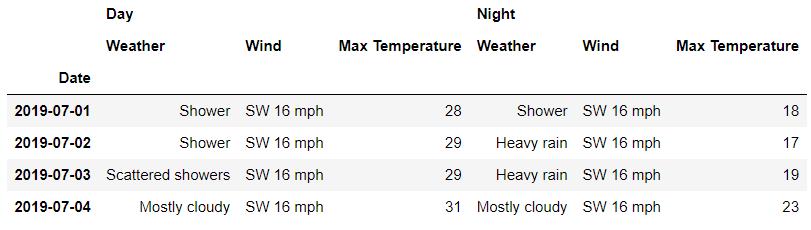
df.loc['London' , :]
## 或者是
df.loc[('London', ) , :]output
当然我们也可以这么来做,在行方向上指定第二层级上的索引,代码如下
df.loc['London' , '2019-07-02']
## 或者是
df.loc[('London' , '2019-07-02')]output

多重索引的数据获取
假设我们想要获取剑桥在2019年7月3日白天的数据,代码如下
df.loc['Cambridge', 'Day'].loc['2019-07-03']output

在第一次调用loc['Cambridge', 'Day']的时候返回的是DataFrame数据集,然后再通过调用loc()方法来提取数据,当然这里还有更加快捷的方法,代码如下
df.loc[('Cambridge', '2019-07-01'), 'Day']我们需要传入元祖的形式的索引值来进行数据的提取。要是我们不只是想要获取单行或者是单列的数据,可以这么来操作
df.loc[
('Cambridge' , ['2019-07-01','2019-07-02'] ) ,
'Day'
]output

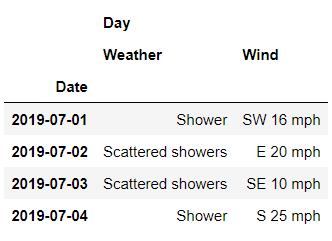
或者是获取多列的数据,代码如下
df.loc[
'Cambridge' ,
('Day', ['Weather', 'Wind'])
]output
我们要是想要获取剑桥在2019年7月1日到3日,连续3天的白天气候数据,代码如下
df.loc[
('Cambridge', '2019-07-01': '2019-07-03'),
'Day'
]output

这么来写是会报语法错误的,正确的方法应该是这么来做,
df.loc[
('Cambridge','2019-07-01'):('London','2019-07-03'),
'Day'
]xs()方法的调用
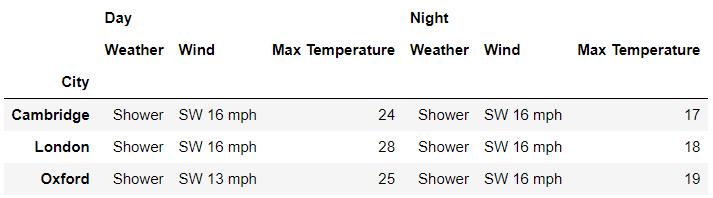
小编另外推荐xs()方法来指定多重索引中的层级,例如我们只想要2019年7月1日各大城市的数据,代码如下
df.xs('2019-07-01', level='Date')output
还能够接受多个维度的索引,例如想要获取伦敦在2019年7月4日的全天数据,代码如下
df.xs(('London', '2019-07-04'), level=['City','Date'])output

另外还有axis参数来指定是获取“列”方向还是“行”方向上的数据,例如我们想要获取“Weather”这一列的数据,代码如下
df.xs('Weather', level=1, axis=1)output
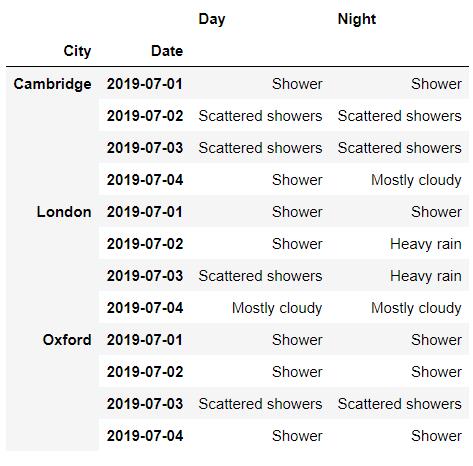
当中的level参数代表的是层级,我们将其替换成0,看一下出来的结果
df.xs('Day', level=0, axis=1)output
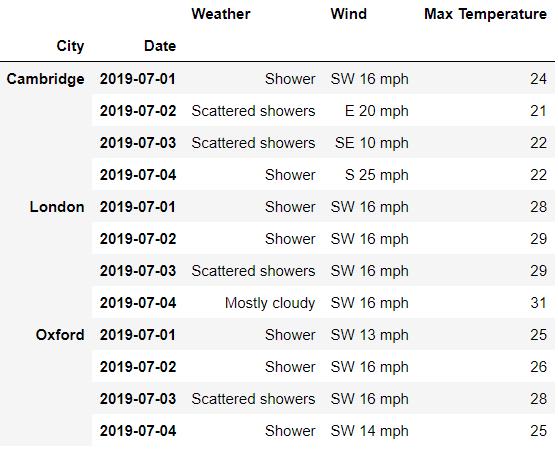
筛选出来的是三个主要城市2019年白天的气候数据
IndexSlice()方法的调用
同时Pandas内部也提供了IndexSlice()方法来方便我们更加快捷地提取出多重索引数据集中的数据,代码如下
from pandas import IndexSlice as idx
df.loc[
idx[: , '2019-07-04'],
'Day'
]output
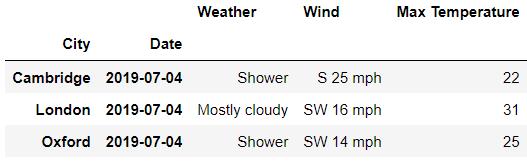
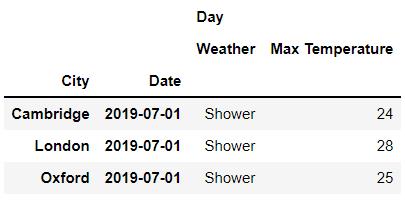
我们同时可以指定行以及列方向上的索引来进行数据的提取,代码如下
rows = idx[: , '2019-07-02']
cols = idx['Day' , ['Max Temperature','Weather']]
df.loc[rows, cols]output


往期回顾
分享
点收藏
点点赞
点在看以上是关于介绍 Pandas 实战中一些高端玩法的主要内容,如果未能解决你的问题,请参考以下文章