资深开发者弃用Julia,联合创始人:对所列的问题感到痛心
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资深开发者弃用Julia,联合创始人:对所列的问题感到痛心相关的知识,希望对你有一定的参考价值。
【CSDN 编者按】搜索Julia你会发现,与其相伴的还有另一个编程语言,Python。这些文章的标题往往是Julia与Python有何不同?对比Julia和Python之后,Julia性能比Python高出了多少多少。Julia官方团队在采访中也曾表示:“Julia在简单的机器学习任务上可与Python媲美,而在复杂的机器学习任务上甚至优于Python。”
作者 | Yuri Vishnevsky 编译 | 梦依丹
出品 | CSDN(ID:CSDNnews)
尽管这门于2009年研发,2012年开源的Julia一经推出便获得了不少开发者的青睐,其语言生态更是涉及众多领域,如数据可视化、通用编程、数据科学、机器学习、科学计算等。
然而本文作者Yuri Vishnevsky作为众多Julia追随者中的一员,他对Julia的感情并没有随着开发时间的增长而浓烈,反而是发文倾述不会在推荐Julia,为何会有如此大的反转,笔者对原文进行了编译,为更好地贴近原文,译文将以第一人称阐述。

1、因正确性和可组合错误,我停用了Julia
多年以来,我一直使用Julia对数据进行转换、清理、分析和可视化操作,还有统计、模拟。我也发布了一些开源包,例如符号距离场(SDF)、最近邻搜索和图灵模式等,还有对Julia概念进行可视化解释、如广播和数组,并使用Julia在我的名片上制作生成艺术。
但在不久前,我已经停用Julia。但它还会时不时出现在我的生活之中,当有人问起时,我会回答,我已经不再推荐这门编程语言了。
在使用Julia多年以后,我得出了这样的结论:在整个生态系统中存在太多正确性(correctness)和可组合性错误,以至于对正确性有要求的情况下,都没有理由使用它。
2、Julia软件包的正确性错误率最高
就我经验来说,在我使用过的所有编程系统中,Julia及其软件包的正确性错误率是最高的,我在2005年左右开始使用 Visual Basic 6 进行编程。
下面列举一些我发现的关于正确性方面的问题:
-
对概率密度采样会产生错误结果
-
对数组采样,结果会存在偏差
-
对于8位、16位和32位整数,乘积函数结果存在错误情况
-
对64位数组拟合直方图会产生不正确的结果
-
基本函数sum!、prod!、any!和all!可能会默默地返回错误结果。
以下是其他人列出的一些可比较性问题:
-
Summarystats对均值为0的数组返回NaN量值
-
OrderedDict 会破坏keys
-
闰年dayofquarter()存在误差
-
使用带误差线的数字类型时,模拟结果会不正确
-
使用stdout=iostream的管道不按顺序书写
-
因为一些copyto!方法不会对别名进行检查,所以会返回错误结果
-
错误的if-else控制流程
我经常会遇到这种严重性的错误,也让我对Julia进行任何适度复杂计算的结果产生怀疑。在尝试新包或者函数组合时尤其如此,将多个来源的功能组合在一起是该类错误的重要来源。
有时,问题会出现在那些不能组合在一起的包上,而有时,Julia 功能在单包中意外组合也会意想不到地失败。
例如,我发现来自Distances包的Euclidean距离对Unitful向量不起作用。还有人发现,Julia运行外部命令功能对子串失效。还有人发现,Julia 对缺失值的支持在某些情况下会破坏矩阵乘法。还有,标准库的@distributed宏不能与OffsetArrays 一起工作。
需要强调的是,OffsetArrays被证明是正确性错误的一个重要来源。这个包提供了一个数组类型,它利用Julia自定义索引功能来创建数组,其索引不必从0或1开始。使用后常常会导致越界内存访问,就像在C或者C++中遇到的那样。
幸运的话会导致segfaults错误,不幸则可能会产生错误结果。我曾在Julia核心处发现一个错误,即用户和库作者都编写了正确的代码,但依然会产生越界的内存访问。
我向JuliaStats组织提交了一些与索引有关的问题,该组织管理着945个软件包所依赖的Distributions和1660个软件包所依赖的StatsBase统计包。例如下面这些:
-
在存在偏移轴的情况下,大多数采样方法都是不安全和不正确的
-
拟合离散均匀分布会默默地返回一个错误答案
-
counteq, countne, sqL2dist, L2dist, L1dist, L1infdist, gkldiv, meanad, maxad, msd, rmsd和psnr在有偏移指数的情况下可能会返回错误的结果
-
对@inbounds误用会导致统计数字计算错误
-
Colwise和pairwise可能会返回不正确的距离
-
显示一个Weights向量包装offset数组会导致访问越界内存错误
这些问题的背后并非出自单独的索引,而是与 @inbounds特性一起使用时产生,它允许Julia从数组访问中移除边界检查。
例如:
function sum(A::AbstractArray)
r = zero(eltype(A))
for i in 1:length(A)
@inbounds r += A[i] # ← 🌶
end
return r
end上面的代码是对数组长度进行遍历,如果给它传递一个索引范围不寻常的数组,它就会访问越界内存:因为数组访问被@inbounds注释了,所以它取消了边界检查。
该案例是典型的@inbounds误用,然而,这也是如何正确使用@inbounds的官方例子。该案例位于一个警告的正上方,解释了其错误的原因。
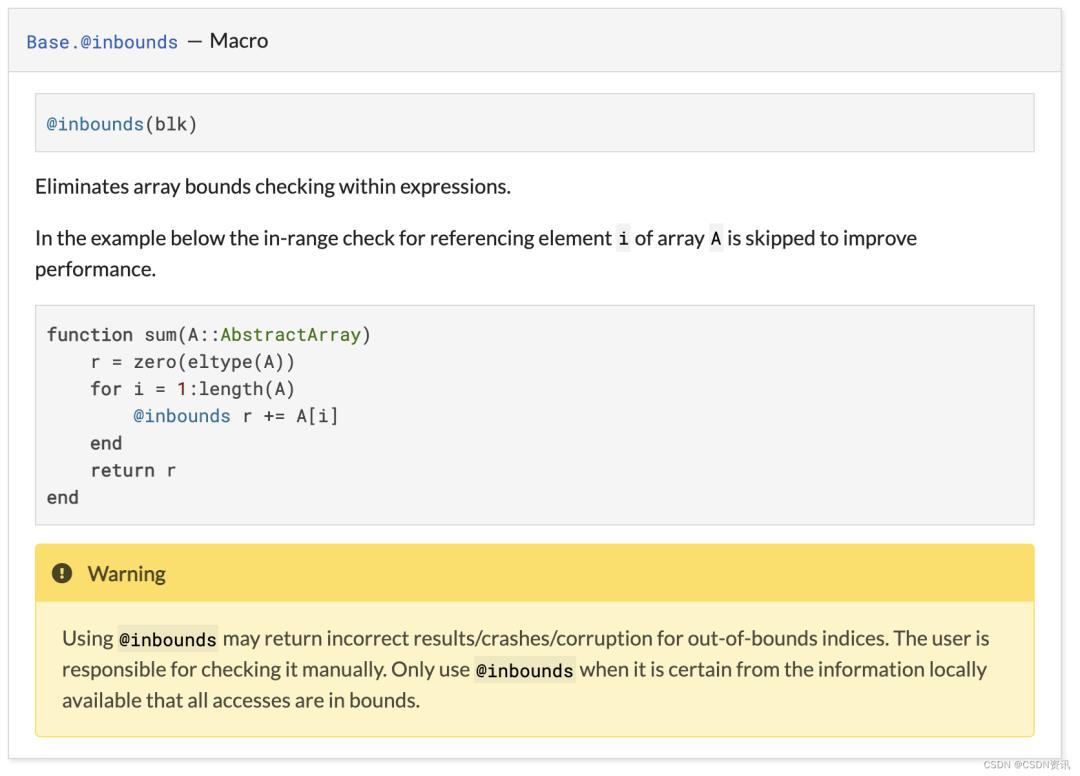
尽管该问题目前已解决,但令人担忧的是,@inbounds可以如此轻易地被滥用,悄无声息地进行数据损坏和返回错误的数学计算结果。
依我的经验来看,类似的问题并不局限于Julia生态系统的数学部分。例如对JSON 进行编码,发出HTTP请求,将Arrow文件与DataFrames一起使用,以及用Pluto.jl编辑Julia代码等,也都会遇到一些库错误。
3、不止我一人发现这些问题
在我好奇本人的经历是否具备代表性时,一些Julia用户在私下也分享了类似的事情,并且一些公开报道也开始出现。
例如在这篇文章中,Patrick Kidger描述了尝试使用Julia进行机器学习研究时所观察到的:
在Julia Discourse上经常可以看到这样的帖子:“XYZ库不能用了”,随后某个库的维护者就会回复说:“这是ABC库的新版本a.b.c中的一个上游错误,XYZ依赖于此。我们会尽快推送一个修复方案。”
下面是Patrick追踪一个正确性错误的经验分享(重点是我的):
我的一个Julia模型在训练时失败了,这让我非常难过。我断断续续花了好几个月的时间试图让它正常工作,尝试了我能想到的所有技巧。
最终!我发现了错误所在。Julia/Flux/Zygote返回了不正确的梯度。在花了那么多精力与上面的第1和第2点搏斗之后,我果断放弃了对Julia模型的调试。两个小时过后,我用PyTorch成功地训练了这个模型。
在该文评论处,其他人也分享了类似的经历:
@Samuel_Ainsworth:
和@patrick-kidger一样,我也被Zygote/ReverseDiff.jl中不正确的梯度bug所困扰。这花费了我数周的时间,并彻底动摇了我对整个Julia AD的信心。[…]在我使用PyTorch/TF/JAX的这么多年里,我还没有遇到过一次不正确的梯度错误。
@JordiBolibar:
我自从使用Julia工作以来,我在Zygote上遇到了两个bug,导致我的工作延期了几个月。从积极的方面看,这迫使我投入到代码中,并学习了很多关于我所使用库的知识。但我发现自己正处于这样一种情况:需要研究的库变得越来越多,我需要花大量的时间来调试代码,而不是做气候研究。
鉴于Julia的极端通用性,对我来说,这些正确性问题并非能显而易见解决。Julia没有正式的接口概念,通用函数倾向于在边缘情况留下它们的语义,而且许多常见的隐式接口性质还没有被精确化(例如,在Julia社区中对什么是数字没有一致的看法)。
4、官方始终没有承认与解决
Julia社区充满了有能力、有才华的人,他们慷慨地提供时间、工作和专业知识。但是像这样的系统性问题很少能够自下而上地解决。我的感受是,项目领导层并不承认存在一个严重的正确性问题。他们接受个别孤立问题的存在,但不接受这些问题所暗示的模式。
例如,在Julia的机器学习生态系统还不成熟的时候,该语言的一位联合创始人曾热情地谈到将Julia用于自动驾驶汽车的生产。
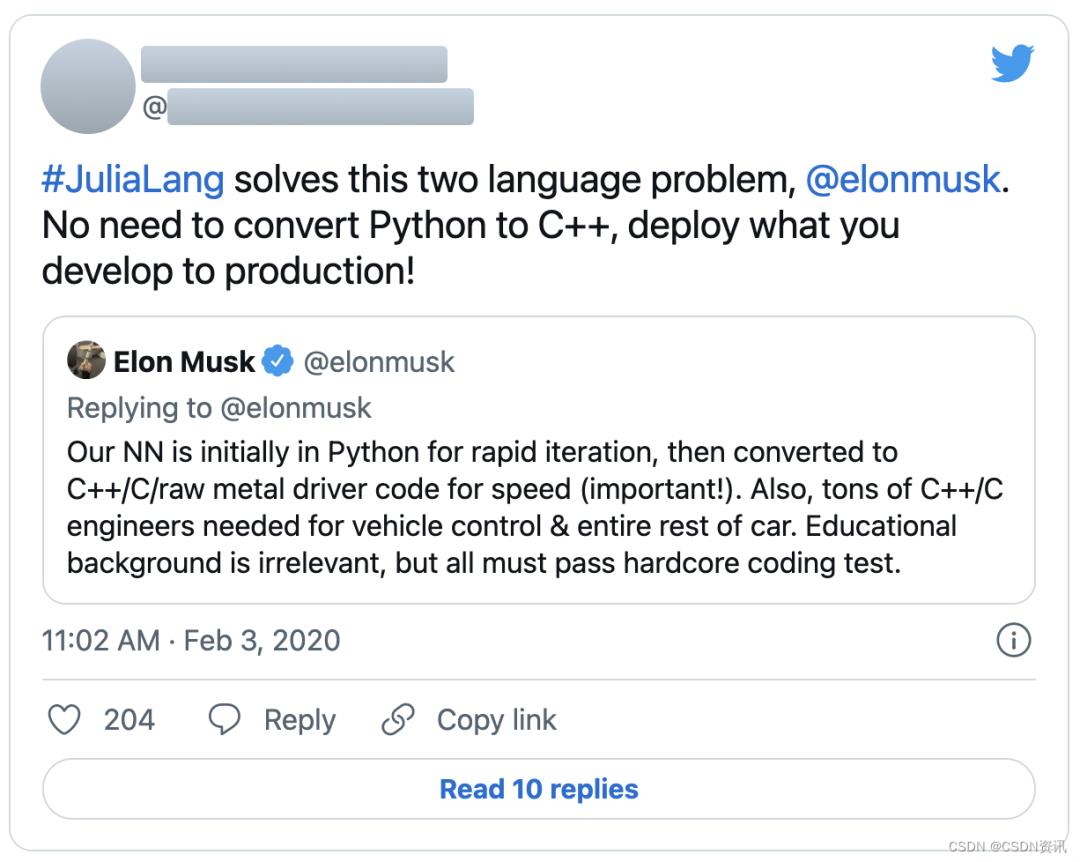
而另一位创始人在同时期所表达的,可能很好地说明了人们之间的认知差距(尤其是我):
他认为,Julia语言最大的收获并不是作为一门伟大的语言(尽管它是),而是应该用它去做所有的事情(尽管这并不是最糟糕的想法),并且Julia的设计在实现代码重用能力方面已经达到了一定的高度。实际上,在Julia中,用户可以把一个人写的通用算法和其他人写的自定义类型放在一起,并有效地使用它们。这在很大程度上提高了编程语言中代码重用。语言设计者不应该复制Julia的所有功能,而是应该理解这样做的效果为什么会这么好,并且能够在未来的设计中实现高水平的代码重用。
每当有批评Julia的帖子在社区开始流传后,很快就会有回应,尽管历史上存在一些合理的问题,但情况已经有了很大的改善,而且大多数问题都已得到解决。
比如:
-
2016年:“该篇博文中提出的合理问题已得到解决。”
-
2018年:“我也抱怨过我刚开始接触Julia时看到的’牛仔’文化[…]但那些日子已经过去了。”
-
2020年:“在2016年,但这已经得到了很好的解决。”
-
2021年:“在Julia中,没有技术上的一致性执行,但通用函数的语义得到了广泛的尊重,通用代码也可以使用。”
-
2022年:“当然有bug,但都不严重。”
这些回答在其狭隘的背景下往往看起来是合理的,但最终的效果却是人们的合法体验被削弱或淡化了,而更深层次的问题却没有得到承认和解决。
以我在过去十年对Julia以及社区的了解,其在正确性方面依然是不可靠的,或者正在朝可靠方面前进,而对于Julia团队想要服务的大多数用例来说,其风险是大于回报。
十年前,Julia被介绍给了世界,并提出了一系列鼓舞人心和雄心勃勃的目标。我仍然相信,这些目标有朝一日可以实现,但是,如果不重新审视和修改那些将项目带到今天这个状态的模式,就无法实现。
最后,我要感谢Mitha Nandagopalan、Ben Cartwright-Cox、Imran Qureshi、Elad Bogomolny、Zora Killpack、Ben Kuhn和Yuriy Rusko对本文早期草稿的讨论和评论。
5、Julia联合创始人回应:对所列问题感到痛心
Yuri Vishnevsky的这篇文章在HN上引起了广泛的讨论,并引来了Julia联合创始人KenoFischer的回应,他首先肯定Yuri在Julia上花费了大量的时间,并认为Yuri是一位非常有能力的程序员,所以文中提出的问题应当被认真对待,但对最终得出的结论感到很很难过。
Yuri在帖子中罗列了不少问题,KenoFischer有点不知从哪个角度去下手回答,但他还是决定试一试。在他看来,本文有几个不同的投诉线索,其中一类是Julia产生的仅仅是Bug(例如提到的HTTP、JSON等问题)的数量要比其他系统中要多的多,这样的结论不知从何得出。不可否认,Julia中肯定会存在一些Bug,但依他来看,每当尝试一个新软件时,或多或少地会存在2-3个关键性问题,不管它们是基于何种语言开发。
而就“很难知道预期会发生什么”这一类批评在KenoFischer看来却是合理的,并且他也表示同意。这是一些基本设计决策所引发的错误。事实上,Julia正在就可组合性工作进行努力,即使用户所组合包的作者对对方一无所知。这是Julia的一大关键特性,也让Julia愈加强大。与此同时,也很容易出现以下情况,一个或者另一个包正在做没有记录的隐含假设(因为作者认为这些假设在他们自己包的上下文中并不重要),从而导致正确性问题产生。这是一个非常棘手的设计问题。当然,为接口和验证添加更多的语言支持是有帮助的,但并不是所有的隐含假设都能在接口中轻易捕捉到。也许需要有更明确的文件来说明哪些包的组合是被 "支持 "的。通常来说,现在最好的方法是看看在CI上做了哪些下游测试,以及是否有任何针对这两个包的集成测试。如果有的话,它们可能应该是可以正常工作。
KenoFischer坦言,他对文章所罗列的问题清单感到痛心,他相信这些问题会被社区很快地修复(尤其是引起广泛讨论的帖子)。目前应该对语言进行一些更基本的改进来解决这些问题,但还不是Julia语言的最优先事项。在过去两年,Julia更关注一些“旗舰”应用的开发,因为它们能真正推动Julia向前一步发展。这是一个好的发展,因为这些应用证明了Julia正在被许多全身心的关注和进行改进。一枚硬币总有两面,这些应用也面临一些问题,例如例如"LLVM太慢了",更好的可观察性工具,GC延迟问题等,它们与普通开源的Julia开发者所遇到的问题完全不同。在1.0之前(即2018年),有1-2年的时间,Julia所做的就是思考并彻底改造语言中的通用接口。在他看来,大家现在可以使用其中的另一项努力,但至少在这个确切的时刻,还没有足够的带宽来做这件事。希望在未来,一旦事情稳定下来能进行改进,这大概就是 Julia 2.0 的样子。
最后,KenoFischer认为HN上有些吹毛求疵,这个链接中的问题(https://github.com/JuliaLang/julia/issues/41096)实际上是编程语言中的一个错误,其余才是各种生态系统问题。
KenoFischer表示他并不想推卸责任,因为这些包中有很多也是由Julia的核心开发者共同维护,有责任让这些包运行良好。但如果你想说我的孩子丑陋,至少要指出正确的孩子。
6、网友:Julia语言非常棒,但生态系统需要被重写
除了KenoFischer的评论,第二个高赞评论则是ID为patrickkidger的留言:
在他看来,Yuri不是在表达 “有太多的 bug”,而是在表达围绕Julia本身的文化问题。
但像这样的系统性问题很少能自下而上地解决,我的感受是,项目领导层并不承认存在一个严重的正确性问题。
patrickkidger总结道:
-
Julia生态系统的组合很差。(它是由学者而不是专业的软件开发者制作的)
-
该语言没有提供什么工具来保证正确性。(没有静态类型;没有接口)
就个人而言,最希望看到的是某个大的科技公司加入进来,并直接编写他们自己的生态系统。Julia语言非常棒,但生态系统需要被重写。
原文链接:https://yuri.is/not-julia/
HN热议:https://news.ycombinator.com/item?id=31396861
本文已获作者授权,CSDN编译整理,未经授权,禁止转载!
以上是关于资深开发者弃用Julia,联合创始人:对所列的问题感到痛心的主要内容,如果未能解决你的问题,请参考以下文章