HDFS RPC限流方案实践探索
Posted Android路上的人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS RPC限流方案实践探索相关的知识,希望对你有一定的参考价值。
文章目录
前言
在前面的一篇关于分布式集群下的限流方案文章里,笔者阐述了一种在HDFS集群里的RPC限流架构。其间也提到了很多关于分布式限流架构里的关键要素,包括用户区分,分级队列的概念等等。不过上次文章更多偏向于理论原理篇,本文笔者将结合实际生产环境的特点,来给大家讲讲如何真正将限流方案实施到生产集群,并能够达到预期的效果。
HDFS RPC限流方案
这里要首先聊聊笔者目前集群所将要采用的HDFS RPC限流方案。和上篇文章所设计的略有不同 ,在最新的方案设计里面暂时不考虑Router的服务。这里主要出于2点理由:1)我们目前单Router的处理速度非常快,很少出现请求积压的情况,这样不太容易触发到FairCallqueue的限流效果。2)Router服务目前不支持refreshCallqueue的动态刷新功能。FairCallqueue的功能需要不断进行调参优化改进,如果不支持动态刷新的功能,将会带来比较高的部署成本。
所以目前我们是完全在下游NameNode做的限流设计,限流的结构依然采用的是社区比较成熟的FairCallqueue的功能。FairCallqueue的功能在设计上与我们的使用场景极为吻合,再加上社区在此功能上进行了不断地完善,使得集群admin管理员能够更加方便,灵活地在NameNode上使用此功能。FairCallqueue目前不仅对于其内部priority queue的数量能进行配置化设置之外,还能够对RPC优先级设置的阈值进行调整。但同时这里指出一点,FairCallqueue这种过于灵活的参数配置,让集群管理员一开始不知道如何精确地对FairCallqueue功能进行调参。
出于上面精确调参的问题,笔者在FairCallqueue内部多实现了一个admin的管理命令,来能够动态调整user RPC的priority。这里admin设置的user priority会覆盖掉由FairCallqueue内部算法算出的priority结果。这样能够避免由于参数配置不准确导致部分用户的application被限流处理。
通过上面admin命令的改造再结合HDFS本身的refreshCallqueue功能,笔者设计了下面新的在NameNode端的限流方案:
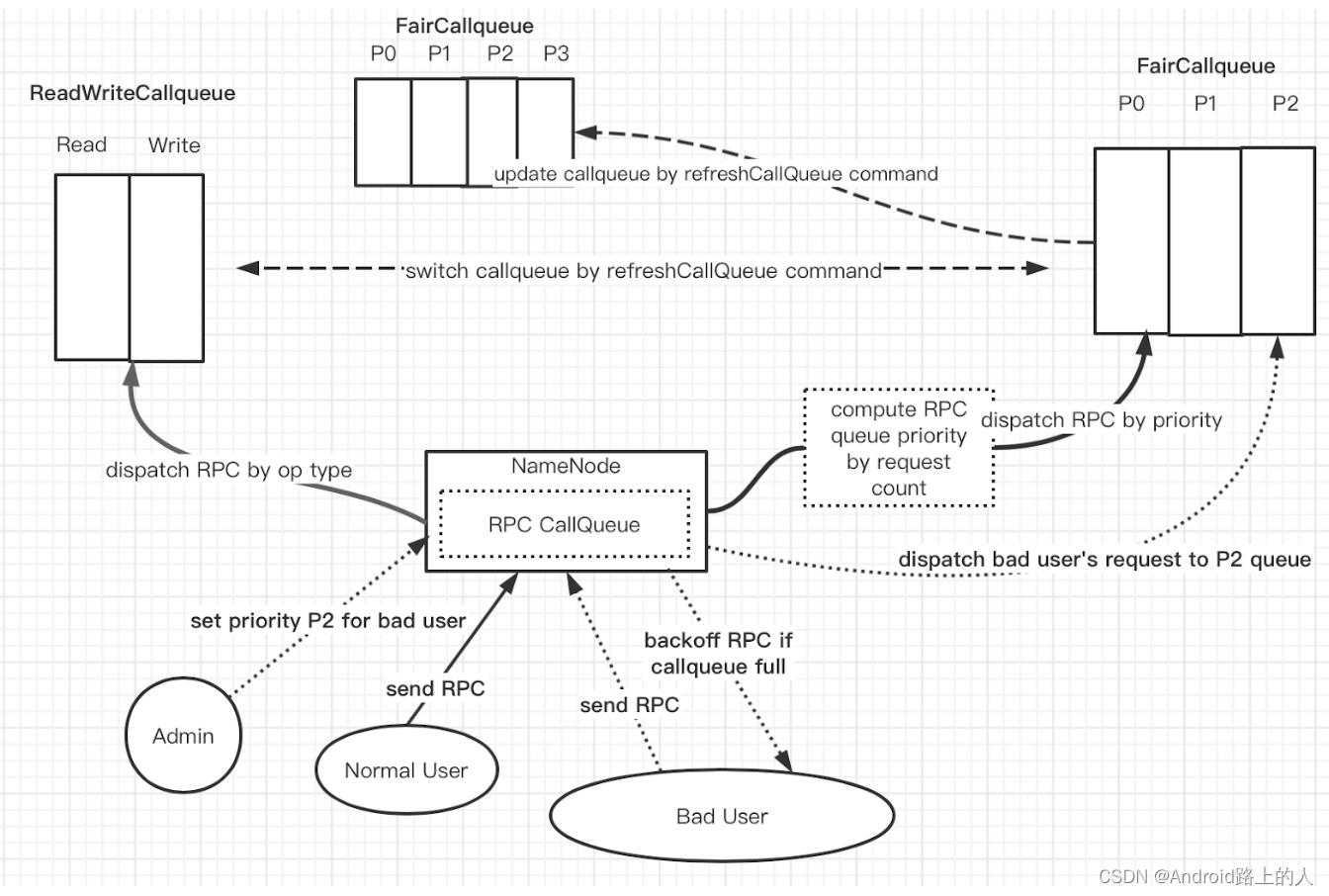
在上图左边显示的ReadWriteCallqueue是原先集群使用的一种Callqueue模式,此Callqueue只是作为FairCallqueue的rollback选择使用。我们主要来看上图中关于FairCallqueue使用的部分。
这里主要提下面2个关键点:
- RPC Callqueue的配置可动态刷新,这里不仅包括FairCallqueue内部参数的动态刷新调整(从3个priority queue增加到4个priority queue),它还支持 FairCallqueue和其它callqueue类型的动态切换。
- Admin对user RPC priority的设置,见上图虚线部分的流程操作。
上述架构如果在FairCallqueue参数配置完美的情况下,大大利用其分级队列的原理,当然能达到比较好的限流效果,但是在运行过程中,完美还是得面临逐步调参的过程。这里另外一个关键的问题来了:我们如何来一步步准确地对FairCallqueue来调参呢?
分级RPC queue的调参
我们经常调侃调参是一门艺术,参数调得准确与否只有一步一步实践了才知道。
在这里我们要调的参数是FairCallqueue的分级queue有关的参数,这里的参数主要有下面几个:
- 1)分级RPC queue的数量设置
- 2)RPC priority的条件判断阈值设置
- 3)RPC queue的处理权重设置
从笔者的实际使用经验来说,我们采用的一个原则是逐步调整的原则,所以在一开始的时候建议采用的是一种偏向保守的参数设置。在queue数量的设置上,3到4个优先级queue的设置笔者个人建议比较适合,基本达到区分出高优先级,中优先级和低优先级的三级队列的设置即可。
其次是priority设置的条件阈值,简单来讲就是我们如何判定某个用户的RPC应该的高priority或者低priority的。这里我们可以参考默认FairCallqueue的配置,将超过50%的当前时段的RPC量的用户列为最低priority的用户。然后前面2个queue的priority的切分阈值可调整为20%或者30%这样的比例。
最后是RPC priority queue的处理权重设置。这里的处理权重指的是NameNode在每次处理周期内处理各个RPC queue请求的数量比。按照正常情况,高优先级queue的RPC请求理应被处理地更多,而低优先级的queue的请求应被更少地处理。当然我们可以将高优先级的queue的权重设置的远高于低priority。但是基于一开始的保守调参的原则,笔者建议在一开始调成略偏向于高优先级的权重设置即可,比如6:5:4这样的设置,意为NameNode在处理的周期内,会处理掉6个高优先级queue RPC,5个中优先级的queue的RPC和4个低优先级queue的RPC。当然这个权重比例的设置在经过实践运行后更加偏向于高优先级的queue。
分级RPC queue的insight
上节的分级队列调参只是初步保守的参数设置,并不是笔者所谓的"黄金配置"。因为在后面实际生产集群的使用过程中,我们肯定会看到是否那些真正的bad user被限制住了,是否高优先级queue的用户RPC被正常地处理。这里其实牵扯到的就是分级RPC queue的insight了,如果我们只有了解了FairCallqueue内部实际的处理情况后,才好对现有的配置参数做进一步地调整优先。
不过好在目前社区FairCallqueue对外已经暴露了很多的内部指标metric来帮助用户了解实际的Callqueue的运行状况,这里主要有下面两个方面的指标:
与分级queue相关的指标:
- 每个priority queue的queue size,queue size越大,意味着这个priority的RPC请求量越大。
- 每个priority queue的平均RPC处理量,以及每个priority queue的RPC的平均处理时间。
这部分的metric如下所示:
"name" : "Hadoop:service=NameNode,name=ipc.xxxx.FairCallQueue",
...
"FairCallQueueSize_p0" : 0,
"FairCallQueueOverflowedCalls_p0" : 0,
"FairCallQueueSize_p1" : 0,
"FairCallQueueOverflowedCalls_p1" : 0,
"FairCallQueueSize_p2" : 0,
"FairCallQueueOverflowedCalls_p2" : 0
"name" : "Hadoop:service=NameNode,name=DecayRpcSchedulerDetailedMetrics.ipc.xxxx",
...
"DecayRPCSchedulerPriority.2.RpcQueueTimeNumOps" : 0,
"DecayRPCSchedulerPriority.2.RpcQueueTimeAvgTime" : 0.0,
"DecayRPCSchedulerPriority.3.RpcQueueTimeNumOps" : 0,
"DecayRPCSchedulerPriority.3.RpcQueueTimeAvgTime" : 0.0,
"DecayRPCSchedulerPriority.1.RpcQueueTimeNumOps" : 2,
"DecayRPCSchedulerPriority.1.RpcQueueTimeAvgTime" : 0.0,
"DecayRPCSchedulerPriority.2.RpcProcessingTimeNumOps" : 0,
"DecayRPCSchedulerPriority.2.RpcProcessingTimeAvgTime" : 0.0,
"DecayRPCSchedulerPriority.3.RpcProcessingTimeNumOps" : 0,
"DecayRPCSchedulerPriority.3.RpcProcessingTimeAvgTime" : 0.0,
"DecayRPCSchedulerPriority.1.RpcProcessingTimeNumOps" : 2,
"DecayRPCSchedulerPriority.1.RpcProcessingTimeAvgTime" : 0.0
与用户相关的指标:
- 用户被处理的RPC call的数量,这可以让我们知道什么用户目前正在发起大量的RPC call操作到FairCallqueue里面。
- 用户对应的优先级的值,这能让我们知道是否FairCallqueue真正地限制住了那些bad user。
此部分的信息通过FairCallqueue的jmx可以看到,样例如下所示:
"name" : "Hadoop:service=NameNode,name=DecayRpcSchedulerMetrics2.ipc.xxxx",
...
"Caller(userA).Volume" : 13,
"Caller(userA).Priority" : 0,
"Caller(userB).Volume" : 42,
"Caller(userB).Priority" : 0,
"Caller(userC).Volume" : 12101586,
"Caller(userC).Priority" : 2,
"Priority.0.AvgResponseTime" : 4.411196280181061,
"Priority.1.AvgResponseTime" : 68.62911603651932,
"Priority.2.AvgResponseTime" : 0.590890993110008,
"Priority.0.CompletedCallVolume" : 34,
"Priority.1.CompletedCallVolume" : 47827,
"Priority.2.CompletedCallVolume" : 0,
"CallVolume" : 12101651
通过上述FairCallqueue的metric,我们能了解它里面的一个insight,继而可以帮助我们不断优化调整FairCallqueue的参数,最终发挥出FairCallqueue的限流功效。
以上是关于HDFS RPC限流方案实践探索的主要内容,如果未能解决你的问题,请参考以下文章