突破硬件瓶颈:Intel体系架构的发展与瓶颈挖掘
Posted 刘爱贵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了突破硬件瓶颈:Intel体系架构的发展与瓶颈挖掘相关的知识,希望对你有一定的参考价值。
软件定义存储SDS正在从容量型向性能型演进,千万级IOPS和微秒级低延迟,非常具有挑战性。3节点标准x86服务器,能否有可能实现1000万IOPS与200us低延迟?这个可以有。硬件性能并不是瓶颈所在,软件颠覆才是关键。
想要取得如此强的性能,必须要有突破时下存储软件对于硬件利用的瓶颈。
而要突破这些瓶颈,就需要对硬件有深入的了解,而后利用软件想方设法突破,或者绕过他们,实现性能的腾飞。
本文是突破硬件瓶颈系列文章的第一篇,分析Intel体系架构带来的瓶颈。
存储的性能越高,则对延迟越敏感,当IOPS提高到百万的时候,纳秒(ns)级别的延迟也必须考虑进去。
想达到这种性能,必须着力降低软硬件体系内的一切延迟,这些延迟往往来自于硬件体系本身,因此,分析硬件体系架构是有必要的。
目前市面上的服务器存世量较高,横贯多种架构,单一分析某一种架构并没有很高的实际价值,采用从前到后、从低端到高端的分析方式,不仅能遍历每代架构的优缺点,也能从Intel的进步过程中,明确瓶颈的所在。
Intel体系架构一瞥
在普遍采用的intel体系架构中,CPU早已不仅是服务器的运算核心,他也是控制内存、外部存储的核心。
集成内存控制器(integratedmemory controller,IMC)早已位于CPU中,它负责调度内存进行读写操作。
PCI-E控制器也位于CPU中,它负责控制高速设备(如显卡、网卡、NVMe等)。
即便是芯片组也是通过DMI总线,间接由CPU控制。
以某块C612双路主板为例,可以看出CPU的核心地位:
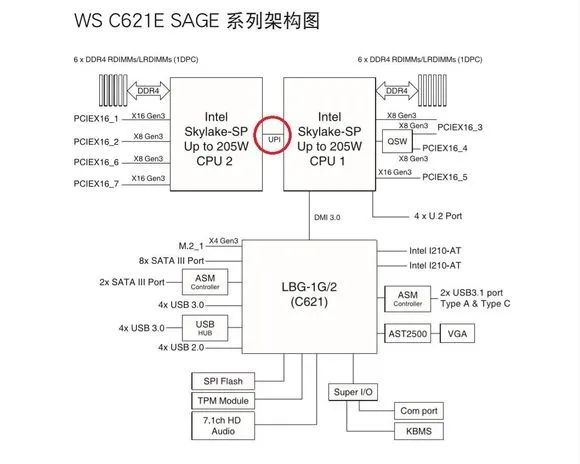
因此,想要找到延迟的根源,必须深挖CPU内部的构造。

01 低端服务器架构设计
曾几何时,CPU的内部架构非常简单,如这颗四核心CPU为例:

最左侧的蓝色部分是集成显卡(iGPU),占据了大量面积(服务器CPU屏蔽这部分)。
四个红色的计算核心(core)旁边则是绿色的L3 Cache缓存。
最右方则是前端部分(agent),包含PCI-E、DP等外部控制器。
上方的黄色部分连接了内存。
几乎所有的部分,都由一条高速通道——Ring总线连接。
Intel绝大多数2-4核心CPU设计都是如此,甚至少数6核心CPU也是这种设计,目前有大量仍在服役的服务器CPU也采用了近似设计。
然而这种设计注定不适合更多核心的CPU,当核心变多,Ring总线势必拉长,而经过的Core越多,则可能造成更多的中断。
四核心的内存理想延迟仅为50ns,而到八核心,延迟就增加到了70ns左右,而且一旦出现IO中断,延迟可能会翻倍激增。
02 中端服务器架构设计
深耕行业多年的Intel深知这种延迟的积累,终究会影响性能,所以Intel后续的CPU使用了环形总线。
单路变环路,吞吐量不仅增加了,还减少了中断造成的延迟。

核心更多,需要缓存的数据也更多,命中率不可避免的降低。
intel将Cache包含关系改变,并且改变缓存配比,使对外速度翻倍(可以理解为L3做了“镜像”),同时引入了CMS,用以进一步降低延迟,L3 Cache成为了环形Ring总线上的“服务区”,不再仅对自己的核心服务,大大提高了缓存利用率。

缓存利用率和速度的提高,是总线中断次数和时间减少,再加上总线通道数增加,都大大缓解了多核心下的延迟。
Intel的6-8核心CPU多数采用此种设计方法,现服役的大量中端服务器,均采用这种设计的CPU。
03 高端服务器架构设计
但是核心的进一步增加,造成了新的瓶颈:更多的核心,需要搭配更多的iMC,如果我们八核心需要双通道内存,那么十六核心就需要四通道内存。
如果iMC都在一侧,则远端的核心内存延迟势必增大,更严重的是Ring的数据分布也会不平均,近IMC一侧延迟增多,造成“前方吃紧,后方紧吃”的结果。
CPU在BroadWell EX中架构采取了笨办法,如果一个环不够“串”起来那么多的核心,那就两个环吧,每个环连接一个IMC。
这种做法解决了一个问题,却又创造了另外一个问题,一个IMC体系之中的延迟降低了,但是两个IMC之间的连接效率低下,简直是将两块CPU涂了“胶水”黏在一起。

因此,Intel不得不再次改变设计,采取了图右侧中的方法。
如果画个草图,就是原来是“串”起来,现在则是“格”起来。
原来每两个实体之间只有一条路,且单向,现在则是有三条路。

从前intel是左边的设计,这里每一个方块都可能代表了IMC(内存控制器)、CORE等结构。
而右边的是Intel的新设计,不仅总线数量增加了,也把system agent里的内存控制器拎了出来,装上CMS模块,用于减少延迟。
新的总线被Intel成为网状(Mesh)总线,如下图:

蓝色双向箭头代表通过针脚与外部联通的部分,橙色是Mesh总线。
以SKylake-SP HCC SoC die(完整18核)为例,下图为该CPU (Xeon E7 8895-V3以及E5-4669 V3等)DIE的电镜图:

可以看到,除了四周的外部接口和触电部分,中央的核心部分被Mesh整齐的分开。
Mesh包含纵向和横向,如果拆开来看,他们的作用并不相同,这里不再过多赘述。

需要指出的是,Mesh架构虽然在高核心数(12核)以上,拥有比Ring低的延迟。
但是即便使用了Mesh,也不可能让16核心的CPU延迟和4核心一样低。
Mesh的意义在于,18核心的理想内存延迟为70ns左右,虽然高于四核心单Ring的50ns,但是平均每核心的延迟远低于单Ring。
由于走线压力,Agent仍然处于一端,PCI-E、UPI的延迟在一定程度上被舍弃了。
另一边,这种设计下,CPU的成本迅速增长,因为半导体工艺良品率的关系,四倍的核心数(面积),往往能造成十倍以上的成本。
正因为单CPU堆核心对于成本的提高太快,我们不得不使用多路CPU系统。
截至目前,新品Intel服务器CPU仍采用这种Mesh设计。
这种设计下,大量的CPU寻址少数的IMC,且延迟不一,每个CPU均有权寻址任何IMC下的任何内存。
04 服务器架构共性问题
由于Intel本身内存调度不够智能,容易造成调度混乱,满载时延迟会爆发性增高。
超线程技术加剧了这一现象,双倍的逻辑处理器造成更高的延迟。
实际上,超线程技术更多的适合虚拟化,以及低功耗、低负载场景,在满载情况下,Intel的超线程技术已经被证明无法增加额外的算力。
现代服务器多为双路,甚至四路、八路。
多路CPU要协同工作,通过UPI(或QPI)连接,跨过“遥远”的主机板电路,出现延迟。
在常见的逻辑中, CPU中所有核心数都逻辑平等。

正因如此,软件通常会随机调度CPU,例如在CPU1中拿出一个核心,又从CPU2中拿出一个核心。
在单颗CPU中,这样延迟并不会太多。

但是在多颗CPU情况下,延迟就可能剧增,一颗CPU可能会需要频繁的绕过主机板,并且再向另一颗CPU发送请求,才能调用并不属于它的IMC,进而调用隶属这颗IMC的内存。
这好比仅想买一包泡面,明明门口有小卖铺,却跑到了另一条街,再找人帮忙代购一包方便面。
这种巨大的延迟是高性能存储服务器所不能容忍的,因此NUMA(Non-Uniform Memory Access)功能应运而生,它标识了内存的跨NUMA节点访问请求,为软件干预调度提供了可能。
至此,我们用实际测试对内存调用产生的延迟做一个总结,下面三行分别是以Xeon E5单路、双路、以及E7 v四路下,CPU运行时钟为3Ghz(时钟频率会影响内存延迟),延迟如下表:

由表中可见,本地内存访问延迟为67ns,而远端访问的双路、四路分别为125ns、140ns。
同样,内存性能的增加也远不是线性的,tot cycles代表每次循环处理事务,可以看到,四路系统的处理速度不到单路的两倍。
05 Intel体系架构瓶颈总结
由以上分析可以得出Intel体系架构目前面临的四大问题:
1、过多核心、线程导致内存的调用效率低下,延迟提升
2、多路CPU导致内存的延迟进一步增高
3、核心的缓存利用率不够高,命中率低
4、如果出现上下文切换,过多的CPU核心会导致更严重的延迟
如果能解决这些问题,就能从CPU和内存调度的角度,提升存储的性能,打破固有的“瓶颈”。
(TaoCloud团队原创)
以上是关于突破硬件瓶颈:Intel体系架构的发展与瓶颈挖掘的主要内容,如果未能解决你的问题,请参考以下文章