论文阅读|node2vec: Scalable Feature Learning for Networks
Posted 白鳯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|node2vec: Scalable Feature Learning for Networks相关的知识,希望对你有一定的参考价值。
论文阅读|node2vec: Scalable Feature Learning for Networks
文章目录
Abstract
Node2vec:一种用于学习网络中节点的连续特征表示的算法框架。学习节点到低维特征空间的映射,以最大化保留节点网络领域概念,并设计了一个baised(偏向)随机游走过程,有效探索不同的领域。
Introduction
任何有监督的机器学习算法都需要一组信息丰富的、有辨别力的和独立的特征。 在网络的预测问题中,这意味着必须为节点和边构建特征向量表示。 非典型解决方案涉及基于专业知识的手工工程特定领域特征。 即使不考虑特征工程所需的繁琐工作,这些特征通常是为特定任务设计的,并且不会在不同的预测任务中泛化。另一种方法是通过解决优化问题来学习特征表示。 特征学习的挑战在于定义目标函数,这涉及平衡计算效率和预测准确性的权衡。
node2vec 可以学习根据节点的网络角色或它们所属的社区组织节点的表示。 通过开发一系列有偏随机游走来实现这一点,它可以有效地探索给定节点的不同邻域。
贡献如下:
- 提出了 node2vec,这是一种用于网络中特征学习的高效可扩展算法,可使用 SGD 有效优化新的网络感知、邻域保留目标。
- 算法的灵活性,适用于等价网络?
- 扩展了node2vec和其他基于邻域保留目标的特征学习方法,从节点到节点对,用于基于边的预测任务。
- 应用于现实网络中进行多标签分类和链路预测
Feature Learning Framework
f : V → R d f:V→R^d f:V→Rd,d为特征维度,f为大小为 ∣ V ∣ |V| ∣V∣的矩阵,对于每个源节点 u ∈ V u ∈ V u∈V ,我们将 N S ( u ) ⊂ V N_S (u) ⊂ V NS(u)⊂V 定义为通过邻域采样策略 S 生成的节点 u 的网络邻域。
优化以下目标函数:
m
a
x
f
∑
u
∈
V
l
o
g
P
r
(
N
S
(
u
)
∣
f
(
u
)
)
max_f\\sum_u∈VlogPr(N_S(u)|f(u))
maxfu∈V∑logPr(NS(u)∣f(u))
为优化问题易于处理,论文中做出两个标准假设:
-
有条件的独立。 我们通过假设观察邻域节点的可能性独立于给定源的特征表示观察任何其他邻域节点来分解似然:
P r ( N S ( u ) ∣ f ( u ) ) = ∏ n i ∈ N S ( u ) P r ( n i ∣ f ( u ) ) Pr(N_S(u)|f(u))=\\prod_n_i∈N_S(u)Pr(n_i|f(u)) Pr(NS(u)∣f(u))=ni∈NS(u)∏Pr(ni∣f(u)) -
特征空间中的对称性。 源节点和邻域节点在特征空间中彼此具有对称效应。 对条件似然进行建模,每个源-邻域节点对作为由其特征的点积参数化的softmax单元:
P r ( n i ∣ f ( u ) ) = e x p ( f ( n i ) ⋅ f ( u ) ) ∑ v ∈ e x p ( f ( v ) ⋅ f ( u ) Pr(n_i|f(u))=\\fracexp(f(n_i)·f(u))\\sum_v∈exp(f(v)·f(u) Pr(ni∣f(u))=∑v∈exp(f(v)⋅f(u)exp(f(ni)⋅f(u))
通过上述假设,目标函数可简化为
m
a
x
f
∑
u
∈
V
[
−
l
o
g
Z
u
+
∑
n
i
∈
N
S
(
u
)
f
(
n
i
)
⋅
f
(
u
)
]
max_f \\quad \\sum_u∈V\\bigg[ -logZ_u + \\sum_n_i∈N_S(u)f(n_i)·f(u) \\bigg]
maxfu∈V∑[−logZu+ni∈NS(u)∑f(ni)⋅f(u)]
Classic search strategies
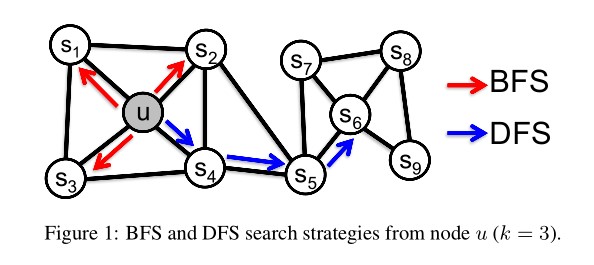
论文将源节点的邻域采样问题视为一种局部搜索形式。对于上图中的源结点u,我们的目标是生成(采样)其邻域 N S ( u ) N_S(u) NS(u)。为了采样策略的公平,将邻域 N S ( u ) N_S(u) NS(u)的大小限制为k个节点,然后为单个节点u采样多个集。通常,生成k个节点的邻域 N S N_S NS有两种极端采样策略:
- Breadth-first Samping(BFS)
- Depth-first Samping(DFS)
BFS体现了网络结构的微观等效性;
DFS体现了网络结构的宏观等效性;
node2vec
Random Walks(随机游走)
通常,给定一个源结点u,游走长度固定为
l
l
l,
c
i
c_i
ci表示游走的第i个节点,令初始节点为
c
0
=
u
c_0=u
c0=u,节点
c
i
c_i
ci由以下分布生成:
P
(
c
i
=
x
∣
c
i
−
1
=
v
)
=
π
v
x
Z
,
i
f
(
v
,
x
)
∈
E
0
,
o
t
h
e
r
w
i
s
e
P(c_i=x|c_i-1=v)=\\begincases \\fracπ_vxZ,if(v,x)∈E \\\\ 0, otherwise \\endcases
P(ci=x∣ci−1=v)=Zπvx,if(v,x)∈E0,otherwise
其中
π
v
x
π_vx
πvx是节点v和x之间的非归一化转移概率,Z是归一化常数。
Search bias α(有偏搜索α)

带有两个参数p和q的二阶随机游走,考虑一个游走,它刚刚遍历了边(t,v),现在位于图中节点v。步行现在需要决定下一步,此时评估从v开始的边**(v,x)上的转移概率
π
v
x
π_vx
πvx。将非归一化转移概率设置为
π
v
x
=
α
p
q
(
t
,
x
)
⋅
w
v
x
π_vx=αpq(t,x)·w_vx
πvx=αpq(t,x)⋅wvx,其中
α
p
q
(
t
,
x
)
=
1
p
,
i
f
d
t
x
=
0
1
,
i
f
d
t
x
=
1
1
q
,
i
f
d
t
x
=
2
α_pq(t,x)=\\begincases \\frac1p, \\quad if \\quad d_tx=0 \\\\ 1, \\quad if \\quad d_tx = 1\\\\ \\frac1q, \\quad if \\quad d_tx = 2 \\endcases
αpq(t,x)=⎩⎪⎨⎪⎧p1,ifdtx=01,ifdtx以上是关于论文阅读|node2vec: Scalable Feature Learning for Networks的主要内容,如果未能解决你的问题,请参考以下文章