《spark技术应用》课程期末考试大作业报告,使用eclipse完成求top值文件排序二次排序三个程序的个性化开发。
Posted Robinnnnnnnnnn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《spark技术应用》课程期末考试大作业报告,使用eclipse完成求top值文件排序二次排序三个程序的个性化开发。相关的知识,希望对你有一定的参考价值。
目录
1.1在VMware中安装一台Ubuntu64位系统... 5
1.5更换壁纸、创建文件夹放置压缩文件和解压后的文件以及数据.. 6
5.1 安装jdk并将hadoop压缩包拷贝到tian文件夹中... 8
5.2将package文件夹中的压缩包解压到tian文件夹中.. 9
6.4格式化 hdfs namenode -format. 12
10.1在GTworkspace 目录下创建文件夹 GTwordcount 并打开终端... 17
10.2在GTwordcount目录下创建以下文件结构,find 查看结构... 17
10.4 创建project文件夹,在project/build.properties输入sbt版.. 18
11.1开启hadoop集群(start-all.sh). 19
《spark技术应用》课程期末考试大作业报告
完成hadoop、spark的安装配置,在此基础上使用eclipse完成求top值、文件排序、二次排序三个程序的个性化开发。
环境(个人):
win11 ubuntukylin-16.04.7
软件版本(个人):
openjdk 1.8.0_292
hadoop-2.7.1
sbt-0.13.18
scala-2.11.8
spark-2.1.0
scala-SDK-4.7.0(eclipse)
1)ssh免密登录
2)安装jdk
3)安装hadoop
4)配置hadoop集群
5)安装spark
6)配置spark集群
7)安装sbt
8)安装配置eclipse
9)开启hadoop、spark进程
10)准备好运行程序所需要的数据文件
11)在eclipse上运行程序
1.设计主要内容
用户名主机名个性化,jdk、hadoop、spark、sbt、eclipse安装路径个性化,eclipse程序个性化。
2.关键技术
ssh免密登录
hadoop集群搭建
spark集群搭建
本地文件上传HDFS
1.准备工作
1.1在VMware中安装一台Ubuntu64位系统
安装Ubuntu 设置用户名(姓名缩写+学号后两位):gt-12

1.2启用共享文件夹实现文件共享,方便文件传输

1.3安装VMware Tools

1.4设置root管理员
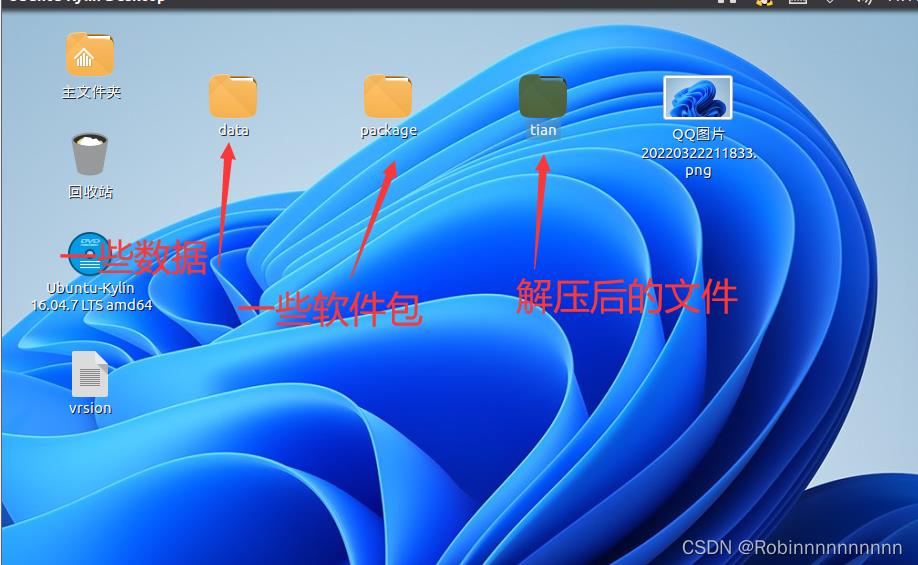
1.5更换壁纸、创建文件夹放置压缩文件和解压后的文件以及数据
2.安装vim编译器
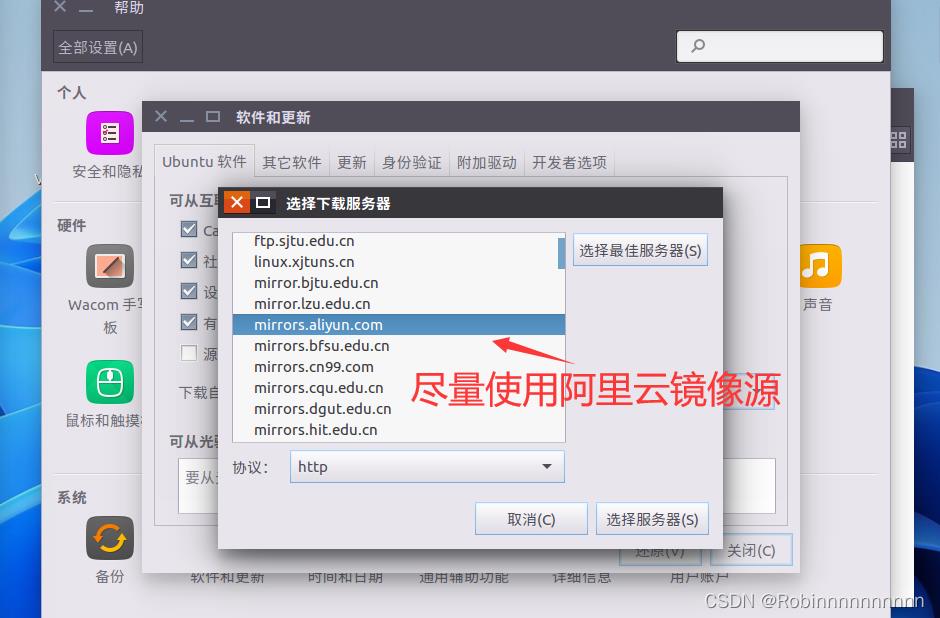
2.1更换镜像网址

2.2下载vim

3.修改环境变量
3.1查看IP地址

3.2修改hosts文件


4.免密登录设置
4.1安装ssh服务

4.2生成密钥私钥

4.3将密钥发送给用户
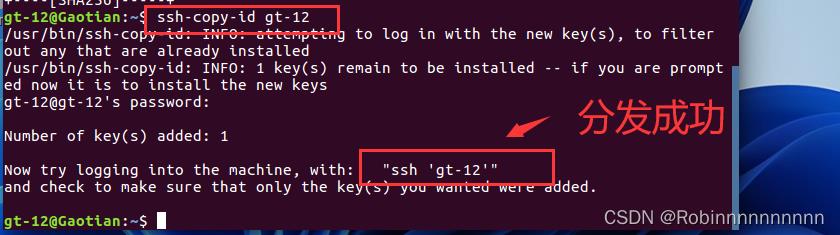
4.4测试免密登录

5.安装jdk、配置jdk全局变量
5.1 安装jdk并将hadoop压缩包拷贝到tian文件夹中

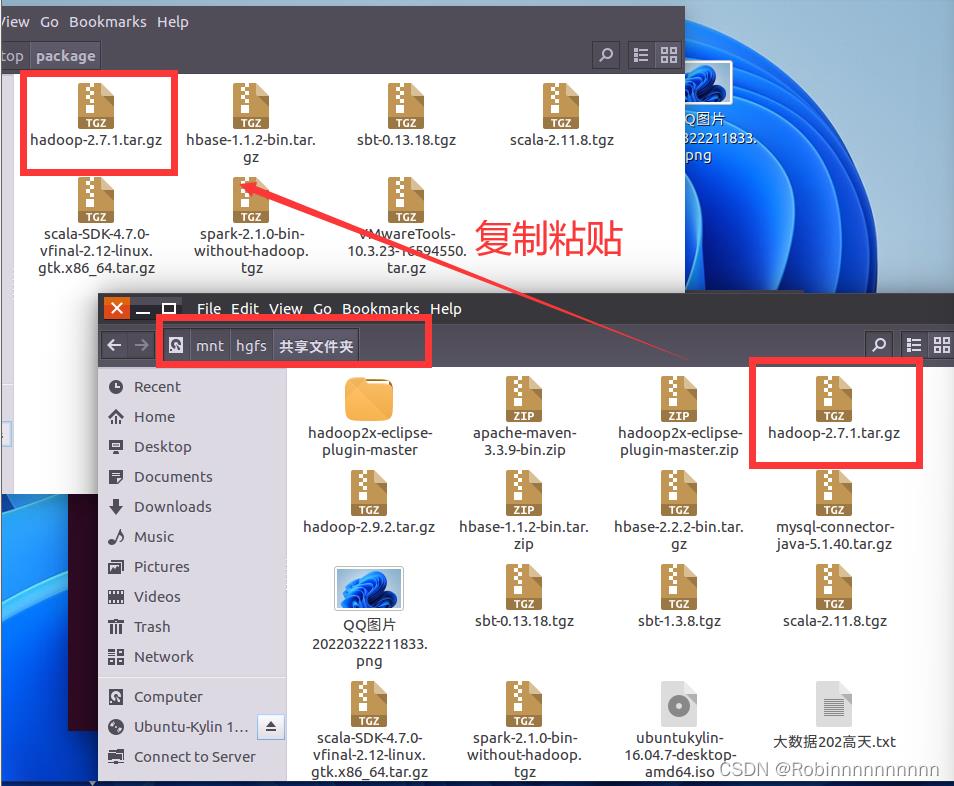
5.2将package文件夹中的压缩包解压到tian文件夹中

5.3修改配置文件
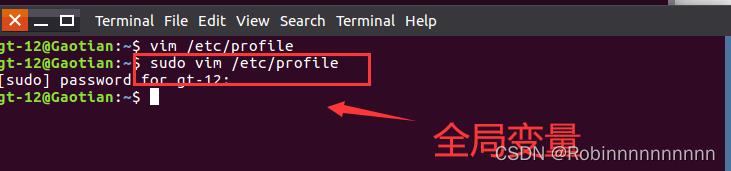


6.搭建hadoop集群
6.1修改hadoop四个配置文件

1)core-site.xml文件

2)hdfs-site.xml文件

3)yarn-site.xml文件

4)mapred-site.xml文件
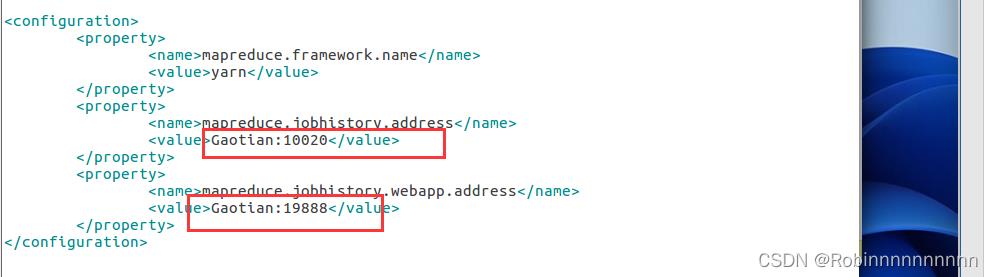
6.2修改hadoop-env.sh文件

6.3修改slaves文件,添加自己的集群名

6.4格式化 hdfs namenode -format

6.5启动和关闭hadoop集群


关闭


7.搭建spark集群
7.1解压spark安装包

7.2 修改配置文件


- 修改spark-env.sh文件 (vim spark-env.sh)

2)返回上级目录 在sbin目录下修改spark-config.sh文件


7.4开启spark 集群 (sbin/start-all.sh)
启动


关闭集群 (sbin/stop-all.sh)

8.安装sbt
解压sbt,将sbt-launch.jar复制到sbt安装目录下,在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt, 同时为该Shell脚本文件增加可执行权限
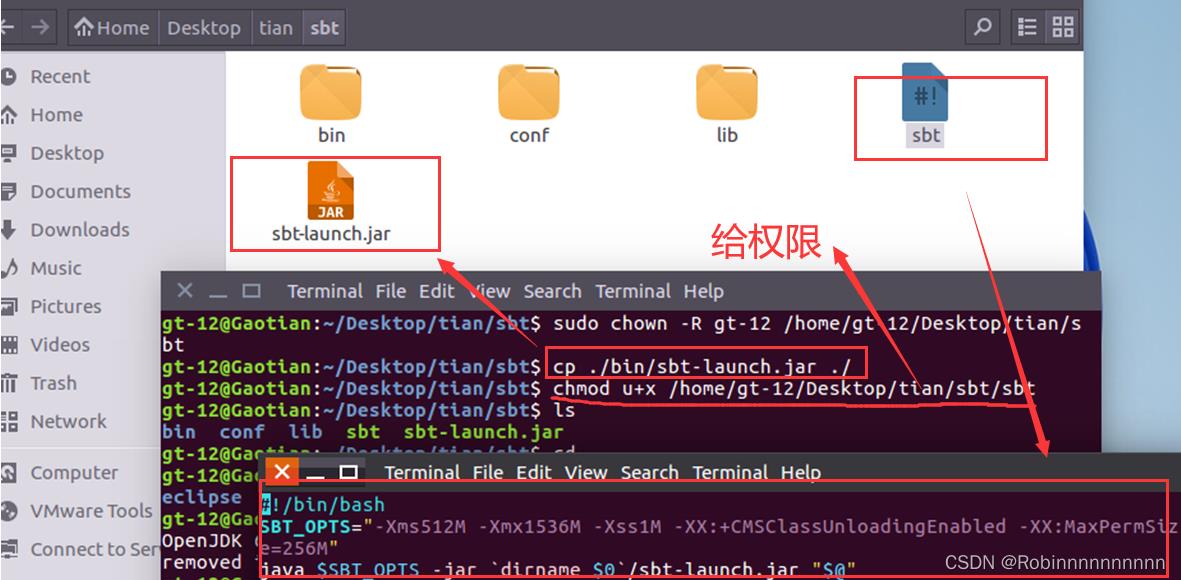
使用命令查看 sbt版本 (./sbt sbtVersion)

9.安装配置eclipse
9.1解压eclipse

9.2配置全局变量
创建目录~/.sbt/0.13/plugins,并在该目录下创建文件build.sbt, 在build.sbt文件输
入以下内容:

9.3 下载sbt相关插件,exit退出
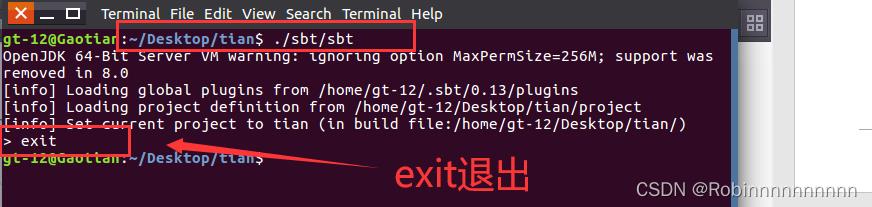
9.4 启动eclipse


10.创建eclipse应用程序运行环境
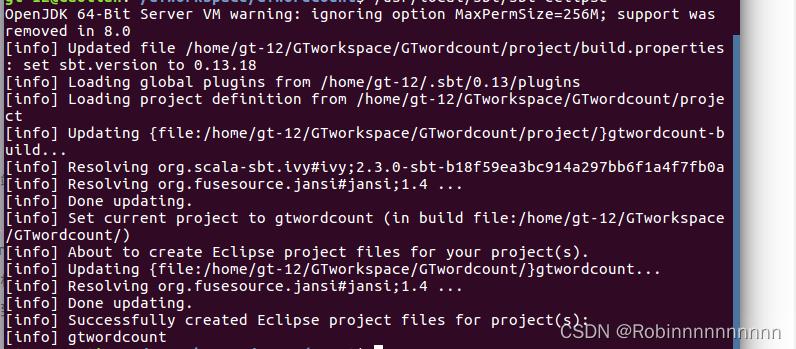
10.1在GTworkspace 目录下创建文件夹 GTwordcount 并打开终端

10.2在GTwordcount目录下创建以下文件结构,find 查看结构
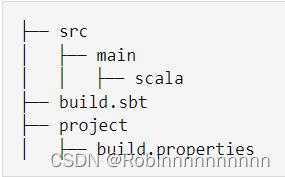

10.3 sbt配置信息

修改为自己的scala版本和spark版本
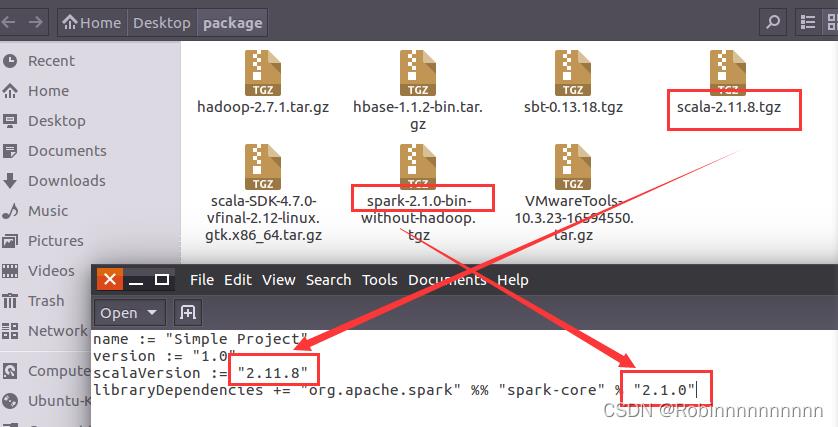
10.4 创建project文件夹,在project/build.properties输入sbt版

10.5 在wordcount 目录下创建eclipse程序
/home/gt-12/Desktop/tian/sbt/sbt eclipse 打包并创建eclipse工程
11.数据准备
11.1开启hadoop集群(start-all.sh)

11.2修改Windows 映射
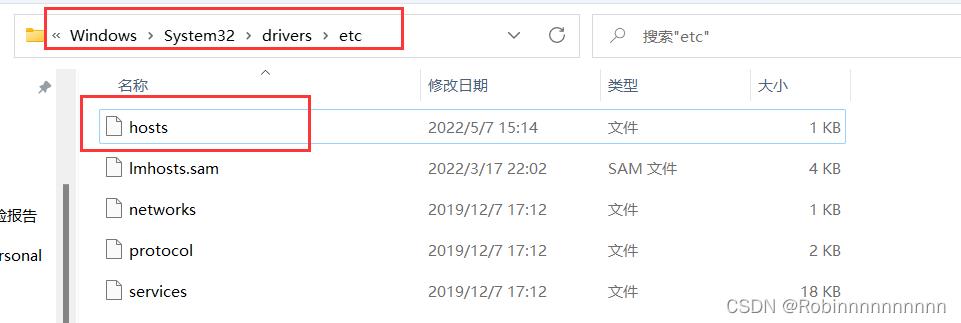
hosts 添加映射

11.3访问hadoop集群web端
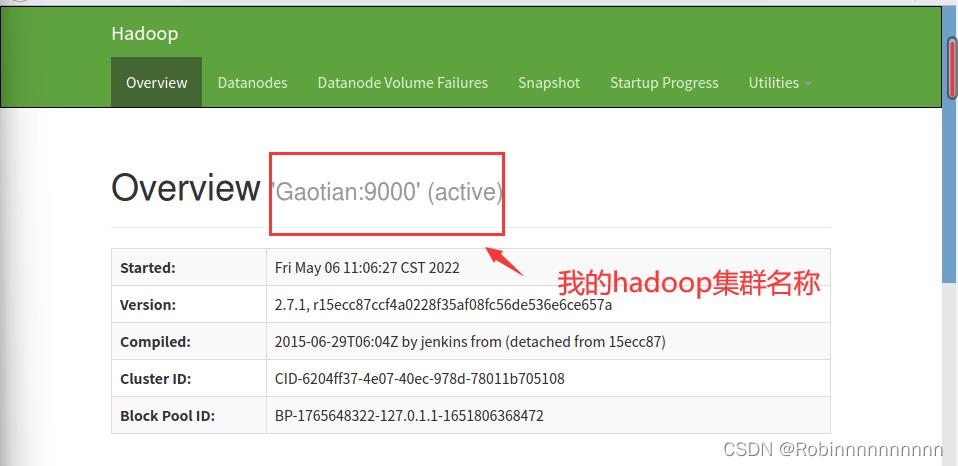
注:也可以直接在ubuntu中直接访问
11.4 HDFS创建文件夹

11.5文件存放
Gaotian_Top文件夹下的大数据202上学期成绩表0.txt 大数据202上学期成绩表0.txt

Gaotian_Top文件夹下的data1、data2

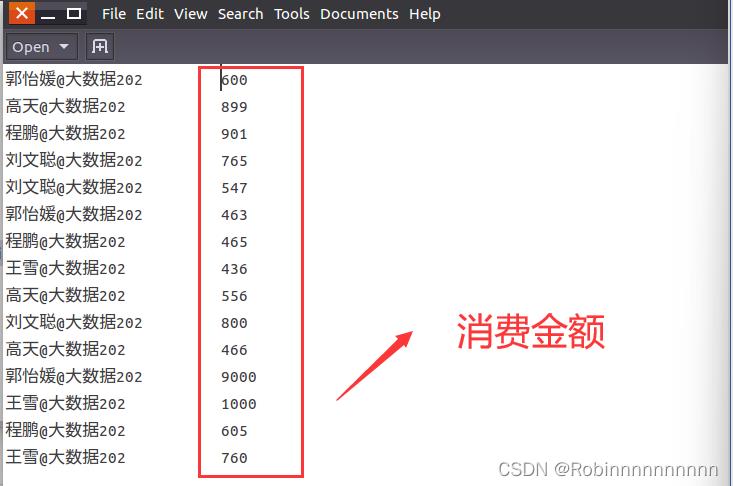
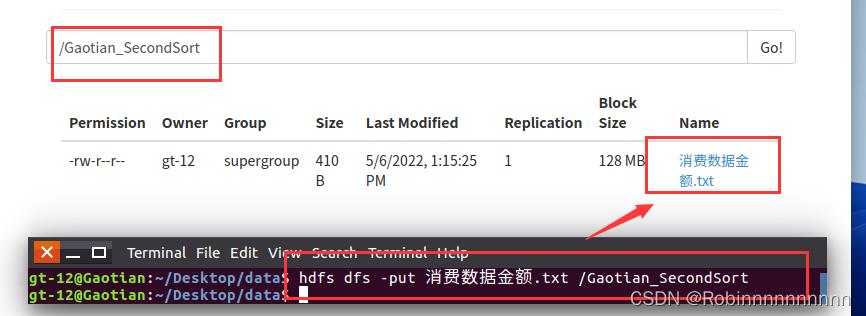
Gaotian-SecondSort文件夹下的 消费数据金额.txt
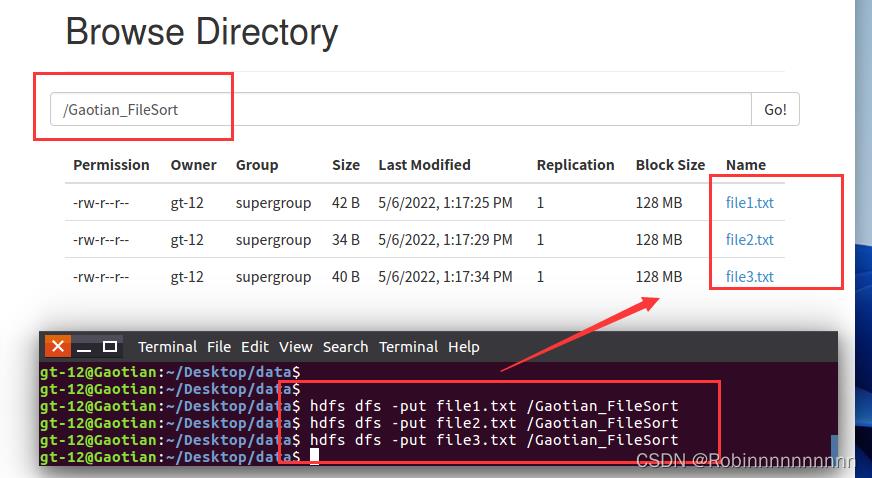
Gaotian_FileSort文件夹下的file1、file2、file3

11.6 数据上传
1)将数据大数据202上学期成绩表0.txt 大数据202上学期成绩表0.txt上传到hdfs Gaotian_Top中

2)将数据data1、data2上传到hdfs Gaotian_Top中


3)将数据 消费数据金额.txt 上传到Gaotian_SecondSort
4)将file1、file2、file3上传到Gaotian_FileSort
12.打开eclipse 导入工程
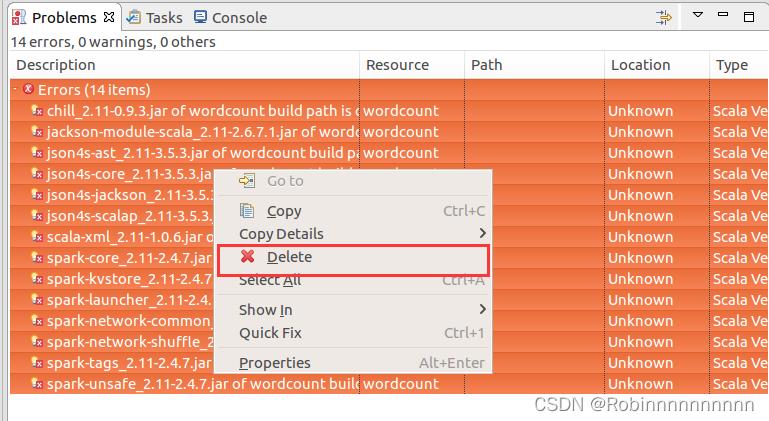
打开eclipse并选择GTworkspace,导入工程File->Import->Existing Projects into Workspace,然后finsh

删除错误文件
GTwordcount工程创建完成

1.班级总成绩Top值
在src/main/scala目录下创建包Gaotian_Top然后创建scala文件Gaotian_SparkTop

写入代码
package Gaotian_Top
import org.apache.spark.SparkConf, SparkContext
/**
* 业务场景:求top值
* 需求:求上学期和这学期大数据课程总成绩综合排名? 前5名
*/
object Gaotian_SparkTop
def main(args: Array[String]): Unit =
//创建SparkConf对象
val conf = new SparkConf().setMaster("local[*]").setAppName("ranking")
//创建上下文对象
val sc = new SparkContext(conf)
//读取外部存储文件
val bigdata = sc.textFile("hdfs://Gaotian:9000/Gaotian_Top/大数据202上学期成绩表0.txt")
val math = sc.textFile("hdfs://Gaotian:9000/Gaotian_Top/大数据202上学期成绩表0.txt")
//对两个表进行连接
val score = bigdata.union(math)
//将连接后的表score中的每行数据按“\\t”分割成集合,并将集合中的学号和分数组合中k-v,学号转换成Int
val rdd1 = score.map(_.split("\\t")).map(x => (x(0) -> x(1).toInt))
//将key学号相同的value进行聚合,
//top()底层调用的是takeOrdered(),我们也直接可以用takeOrdered(10)(Ordering.by(e => e._2) 这种写法叫函数柯里化
val value = rdd1.reduceByKey(_+_).top(5)(Ordering.by(e => e._2))
//输出结果
value.foreach(println)
运行程序

2.多个数据Top值
在src/main/scala目录下创建包Gaotian_Top然后创建scala文件Gaotian_SparkTop,修
改scala版本
package Top
import org.apache.spark.SparkConf, SparkContext
/**
* 业务场景:求top值
object SparkTop
def main(args: Array[String]): Unit =
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val six = sc.textFile("/home/gt-12/Desktop/data/top")
var idx = 0;
val res = six.filter(x => (x.trim().length > 0) && (x.split(",").length == 4))
.map(_.split(",")(2))
.map(x => (x.toInt, ""))
.sortByKey(false)
.map(x => x._1).take(5)
.foreach(x =>
idx = idx + 1
println(idx + "\\t" + x)
)

在src/main/scala目录下创建包Gaotian_ FileSort,然后创建scala文件Gaotian_Spark FileSort

写入代码
package Gaotian_FileSort
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
/**
* 业务场景:求文件排序
* 需求:将每个文件中的数据,进行升序排列?
* @Author: 大数据202 高天 2007322212
*/
object Gaotian_SparkFilesort
def main(args: Array[String])
val conf = new SparkConf().setAppName("FileSort").setMaster("local")
val sc = new SparkContext(conf)
val dataFile = "hdfs://Gaotian:9000/Gaotian_FileSort"
val lines = sc.textFile(dataFile,3)
var index = 0
val result = lines.filter(_.trim().length>0).map(n=>(n.trim.toInt,"")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => index += 1
(index,t._1)
)
result.saveAsTextFile("hdfs://Gaotian:9000/Gaotian_fileout1") //文件名不能存在
运行结果

查看结果
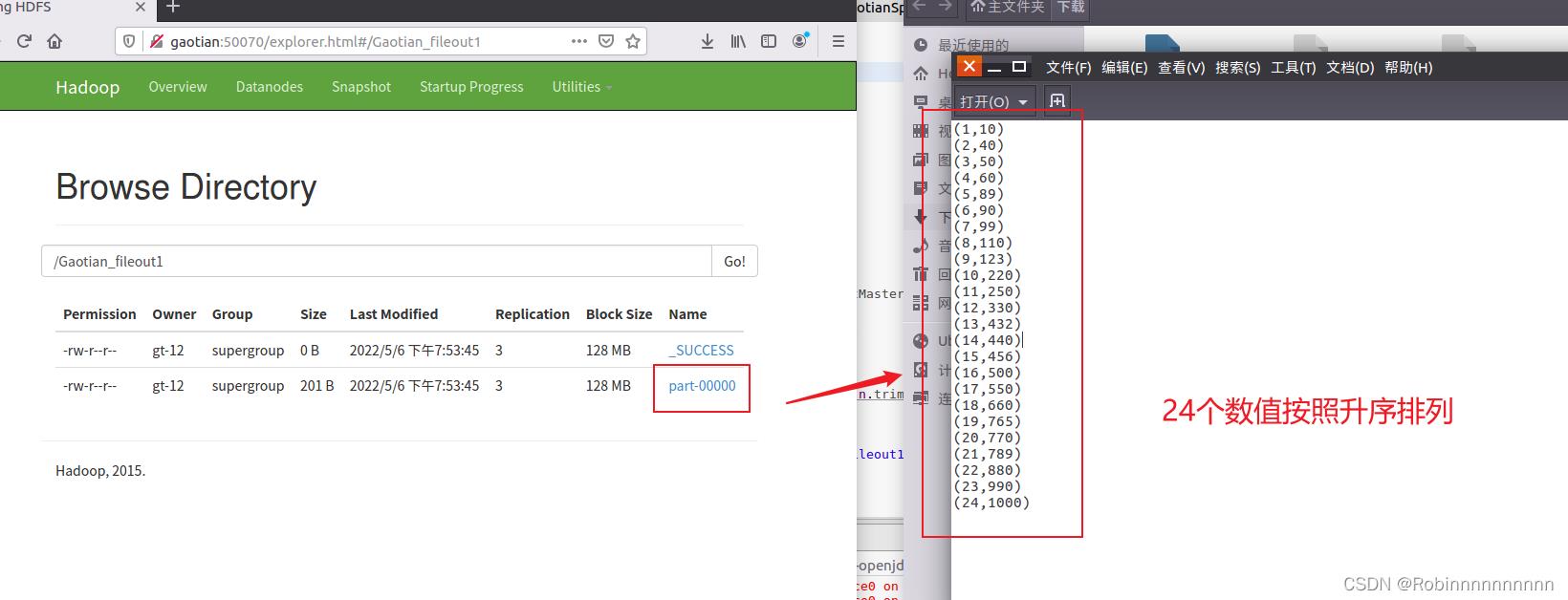
查看一下二次排序 程序的数据
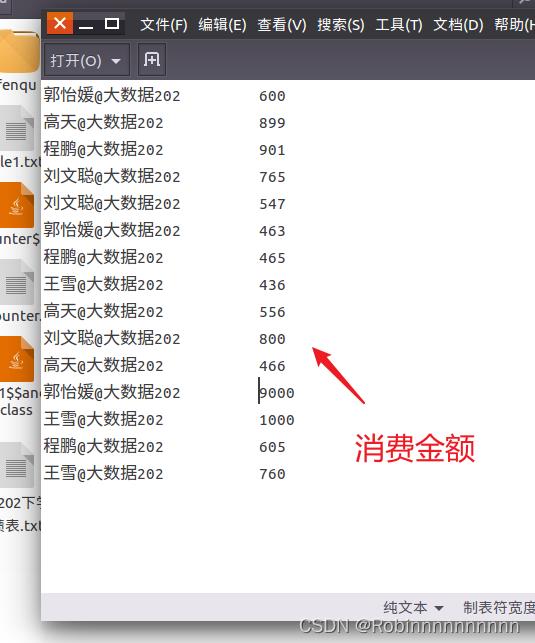
在src/main/scala目录下创建包Gaotian_ SecondSort,然后创建scala文件Gaotian_ SparkSecondSort

写入代码
package Gaotian_SecondSort
import org.apache.spark.SparkConf, SparkContext
/**
* 业务场景:求二次排序
* 需求:求每位用户近期每周消费的金额使用情况,并按照升序排列?
<
以上是关于《spark技术应用》课程期末考试大作业报告,使用eclipse完成求top值文件排序二次排序三个程序的个性化开发。的主要内容,如果未能解决你的问题,请参考以下文章