如何对分库后的数据进行分页查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何对分库后的数据进行分页查询相关的知识,希望对你有一定的参考价值。
1、直接使用跨库的多表联合查询。不建议。2、向6台数据库server均发送一个查询请求,然后对所有查询结果进行汇总,再处理分页逻辑。
3、建立一个总数据库,只负责维护主键和必要的索引,以供分页查询。
4、使用redis维护一个主键序列,分页操作就是截取该序列的一部分,其结果就是主键id集合。拿到id后便可以映射到多台mysql服务器上查询数据了。但毕竟数据被分布式存储了,取到完整结果集必须要多次、多台的数据库访问,这个肯定是避免不了。
注:“多台”数据库访问的问题无解,但同台“多次”数据库访问的问题可以通过程序优化。 参考技术A 想要恢复被删除的数据。以顶尖数据恢复软件为例 第一步,下载顶尖数据恢复软件。 第二步,打开数据恢复软件 第三步,选择误格式化硬盘,然后从中选择自己想要恢复的磁盘,单击进入下一步。 第四步,软件会扫描分区格式化之前的文件,耐心等待扫面完成即可。 第五步,从下面恢复结果的界面中选择自己要恢复的文件,因为是格式化导致的数据丢失,因此也可以全部恢复
亿万级分库分表后如何进行跨表分页查询
亿万级分库分表后如何进行跨表分页查询
前言
在常规的应用系统开发中,很少会涉及到需要对数据进行分库或者分表的操作,多数情况下,我们习惯使用ORM带来的便利,且使用连接查询是一种高效率的开发方式,就算涉及到分表的场景,很多时候也都可以使用ORM自带的分表规则来解决问题。
比如在电商场景中,用户和订单是属于重点增量的数据,通常情况下,或者按用户编号取模或者按订单编号取模进行分表,按便利性来区分,可以使用按用户编号分表解决后续跨表分页查询问题,这也是推荐的方式之一。
据说淘宝采用的是双写订单,即客户和商家各自一套冗余数据库,再指向订单表,这样做可以规避资源抢夺的问题。
分表后查询的多种方法
全局表查询
顾名思义,全局查询就是将分表后的数据主键再集中存储到一张表中,由于全局表只存储很简单的编号信息,查询效率相对较高,但是在数据持续增长的情况下,压力也越来越大。
禁止跳页查询
禁止跳页查询在移动互联网中广泛被应用,这种方法的原理是在查询中摒弃舍弃传统的Page,转而使用一个timestamp时间戳来代码页码,下一页的查询总是在上一页的最后一条记录的时间戳之后,当客户端拉取不到任何数据的时候,即可停止分页。
这种方法带的一个问题就是不允许进行跳转分页,并且会带来冗余查询的问题,比如需要查询多张表后才得到PageSize需要的数据量,只能按部就班的往下查询,不能进行并行查询。特别致命的是,此方法还将带来重复数据的问题。对数据精度要求不高的场景可以采用。
按日期的二次查询法
按日期的二次查询法号称可以解决分页带来的性能和精度问题,具体原理为,先将分页跳过的数据量平均分布到所有表中,如 Page=10,PageSize=50,如果有5个分表,则SQL语句:page=page/5,LIMIT 2,10;分别对5张表进行查询,得到5个结果集,此时,5个结果集里面分别有10条数据,其中下标0和rn-1的结果分别是当前结果集中的最小和最大时间戳(maxTimestamp),通过比较5张表的返回记录得到一个最小的时间戳 minTimestamp,再将这个最小的时间戳带入SQL条件进行二次查询,SQL代码
SELECT * FROM TABLE_NAME WHERE Timestamp BETWEEN @minTimestamp AND @maxTimestamp ORDER BY Timestamp
通过上面的代码,可以从数据库中得到一个完全的结果集,然后在内存中将5个结果集合并排序,取分页数据即可。看起来无懈可击,完美解决了上面两种分页查询引起的问题。实际上我个人认为,这里面还是有一些需要注意的地方,比如由于分表规则的问题导致第一次查询的表比较多(可能几千张表),又或者在二次查询中,某个区间的数据比较大,最后就是在内存中合并结果集也会造成性能问题。
这种查询方法还是解决了精度的问题,也部分解决了性能问题,特别是在取模分表的场景,数据随机性比较大的情况下,还是非常有用的。
大数据集成法
当数据量达到一定程度的时候,可以考虑上ELK或者其它大数据套件,可以很好的解决分页带的影响。
NewSql法
如果有条件,可以迁移数据库到NewSql类型的数据库上,NewSql数据库属于分布式数据库,既有关系数据库的优点又可以无限扩表,通常还支持关系数据库间的无障碍迁移,比如国产的TiDB数据库等。
有序的二次查询法
有序的二次查询法是基于上面的按日期的二次查询法发展而来,这种方法目前还处于测试阶段,具体做法是将数据按天进行分表,这样就可以确保数据块是连续的,以查询最近17天的分页数据为例,先查询出所有表的总行数,这里使用 COUNT(*) ,Mysql 会优化为information_schema.TABLES.TABLE_ROWS 索引查询提高查询效率,不用担心性能问题,下面列出详细的测试步骤。
建立分页实体
public class PageEntity
/// <summary>
/// 跳过的记录数
/// </summary>
public long Skip get; set;
/// <summary>
/// 选取的记录数
/// </summary>
public long Take get; set;
/// <summary>
/// 总行数
/// </summary>
public long Total get; set;
/// <summary>
/// 表名
/// </summary>
public string TableName get; set;
定义分页算法类
public class PageDataService
...
初始化表
在 PageDataService 类中使用内存表模拟数据库表,主要模拟数据分页的情况,所以每个表的数据量都很小,方便人肉计算和跳页
private readonly static List<PageEntity> entitys = new List<PageEntity>()
new PageEntity Total=12,TableName="230301" ,
new PageEntity Total=3,TableName="230302" ,
new PageEntity Total=4,TableName="230303" ,
new PageEntity Total=1,TableName="230304" ,
new PageEntity Total=1,TableName="230305" ,
new PageEntity Total=7,TableName="230306" ,
new PageEntity Total=2,TableName="230307" ,
new PageEntity Total=11,TableName="230308" ,
new PageEntity Total=41,TableName="230309" ,
new PageEntity Total=25,TableName="230310" ,
new PageEntity Total=33,TableName="230311" ,
new PageEntity Total=8,TableName="230312" ,
new PageEntity Total=3,TableName="230313" ,
new PageEntity Total=0,TableName="230314" ,
new PageEntity Total=17,TableName="230315" ,
new PageEntity Total=88,TableName="230316" ,
new PageEntity Total=2,TableName="230317"
;
分页算法
public static List<PageEntity> Pagination(int page, int pageSize)
long preBlock = 0;
int currentPage = page;
int currentPage = page >= 1 ? page - 1 : 0;
long currentPageSize = pageSize;
List<PageEntity> results = new List<PageEntity>();
foreach (var item in entitys)
if (item.Total == 0)
continue;
var skip = (currentPage * currentPageSize) + preBlock;
var remainder = item.Total - skip;
if (remainder > 0)
item.Skip = skip;
item.Take = currentPageSize;
if (remainder >= currentPageSize)
results.Add(item);
break;
else
currentPageSize = currentPageSize - remainder;
item.Take = remainder;
currentPage = 0;
preBlock = 0;
results.Add(item);
else
preBlock = Math.Abs(remainder);
currentPage = 0;
// 输出测试结果
if (results.Count > 0)
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("本次查询,Page:0,PageSize:1", page, pageSize);
Console.ForegroundColor = ConsoleColor.Gray;
foreach (var item in results)
Console.WriteLine("表:0,总行数:1,OFFSET:2,LIMIT:3", item.TableName, item.Total, item.Skip, item.Take);
Console.WriteLine();
else
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("分页下无数据:0,1", page, pageSize);
Console.ForegroundColor = ConsoleColor.Gray;
return results;
在上面的分页算法中,定义了4个私有变量,分别是
preBlock:存跨表数据块长度
currentPage:当前表分页
currentPageSize:当前表分页长度,也是当前表接 preBlock 所需要的查询长度
results:查询表结果,存需要进行二次查询的表结构
接下来,就对最近 17 张表进行模拟轮询计算,把数据块连接起来,首先是计算 skip 的长度,这里使用当前表分页加跨表块
var skip = ((currentPage - 1) * currentPageSize) + preBlock
得到真实的 skip,然后用当前表 Total - skip 得到下一表的接续长度
var remainder = item.Total - skip;
再通过判断接续长度 remainder 大于 0,如果小于0则设定 preBlock 和 currentPage 进入下一表结构,如果大于 0 则进一步判断其是否可以覆盖 currentPageSize,如果可以覆盖则记录当前表并跳出循环,否则 重置 currentPageSize 和其它条件后进入下一个表结构。
if (remainder > 0)
item.Skip = skip;
item.Take = currentPageSize;
if (remainder >= currentPageSize)
results.Add(item);
break;
else
currentPageSize = currentPageSize - remainder;
item.Take = remainder;
currentPage = 1;
preBlock = 0;
results.Add(item);
else
preBlock = Math.Abs(remainder);
currentPage = 1;
测试分页结果
构建一些测试数据进行分页,看接续是否已经闭合
public class Program
public static void Main(string[] args)
PageDataService.Pagination(1, 40);
PageDataService.Pagination(2, 40);
PageDataService.Pagination(3, 40);
PageDataService.Pagination(4, 40);
PageDataService.Pagination(5, 40);
PageDataService.Pagination(6, 40);
PageDataService.Pagination(7, 40);
PageDataService.Pagination(8, 40);
PageDataService.Pagination(9, 40);
PageDataService.Pagination(113, 10);
Console.ReadKey();
输出测试结果
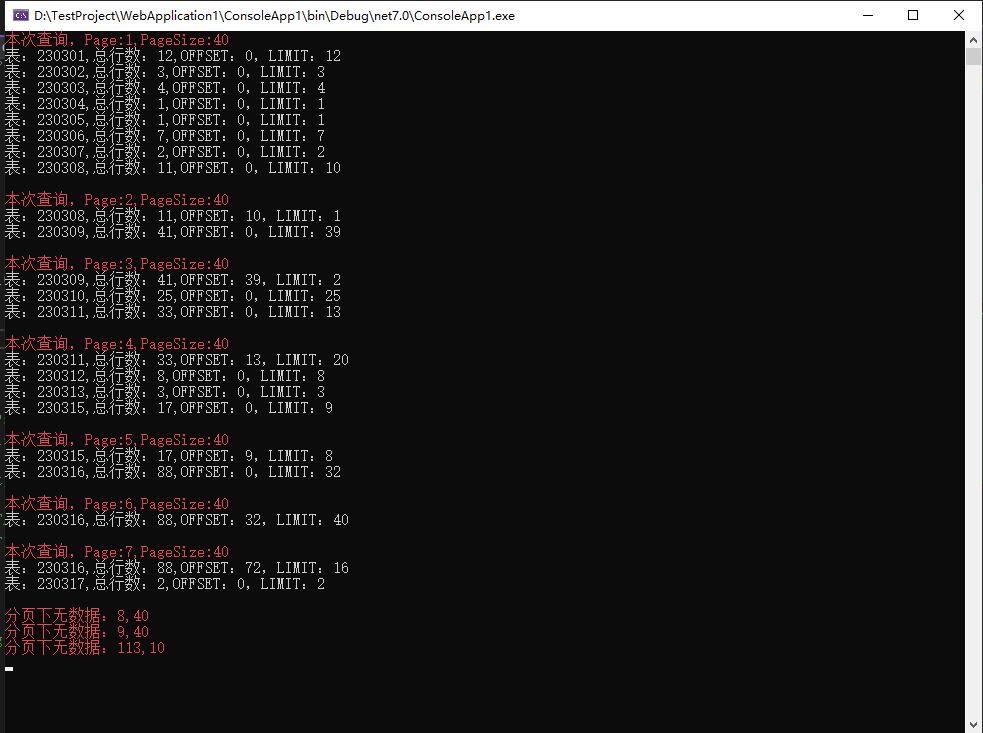
通过输出的测试结果,可以看到,数据块是连续的,且已经得到了每次需要查询的表结构数据,在实际应用中,只需要对这个结果执行并行查询然后在内存中归并排序就可以了。
并行查询和排序
public static void Query()
var entitys = PageDataService.Pagination(1, 40);
List<UserEntity> datas = new List<UserEntity>();
Parallel.ForEach(entitys, entity =>
var sql = $"SELECT * FROM TABLE_entity.TableName ORDER BY Timestamp LIMIT entity.Skip,entity.Take";
var results = Mysql.Query<UserEntity>(sql);
datas.AddRange(results);
);
// 排序
datas = datas.OrderByDescending(x => x.Timestamp).ToList();
到这里,就完成了有序的二次查询法的算法过程。这种分页算法存在一定的局限性,比如必须是连续的数据块,按一定时间区间进行分表才可使用,大区间查询时的分页,第一次查询会比较慢,比如查询区间为3年内的按天分表分页数据,将会导致第一次查询开启 3*365 个数据库连接,当然,这取决于你第一次查询采用的是并行查询还是轮询,还是有优化空间的。
结束语
本文共列出了多种分库分表方式下的查询问题,大部分 ORM 只解决了分表插入的问题,对于分页查询,实际上也是没有很好的解决方案,原因在于分页查询和业务的分割有着紧密的联系,很多时候不能简单的将业务问题认为是中间件的问题。有序的二次查询法作为一次探索,期望能解决部分业务带来的分页问题。

-
欢迎关注收取阅读最新文章
-
好看点个推荐呗~
- 出处:http://www.cnblogs.com/viter/
- 本文版权归作者和博客园共有,欢迎个人转载,必须保留此段声明;商业转载请联系授权,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
- 欢迎大家关注我的微信公众号,一起学习一起进步
外包项目可以找我,前端后端一锅端,作者:漫思,转载请注明原文链接:https://www.cnblogs.com/sexintercourse/p/17285928.html
如有疑问,请加我微信,maliang19860121,24小时在线战略合作伙伴以上是关于如何对分库后的数据进行分页查询的主要内容,如果未能解决你的问题,请参考以下文章